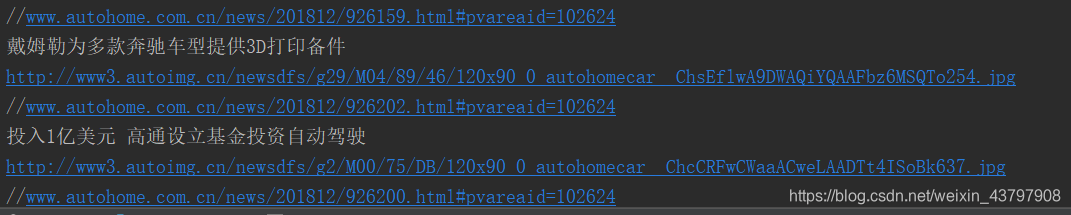
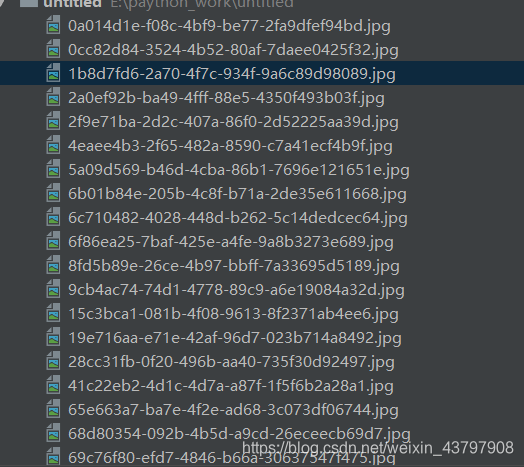
python網路爬蟲爬取汽車之家的最新資訊和照片
實現的功能是爬取汽車之家的最新資訊的連結
題目和文章中的照片
爬蟲需要用到我們使用了 requests 做網路請求,拿到網頁資料再用 BeautifulSoup 進行解析
首先先檢查是否安裝了pip,如果已經安裝了pip,直接pip install requests,pip uninstall BeautifulSoup,安裝成功就可以爬取資料了,以下就是要爬的內容
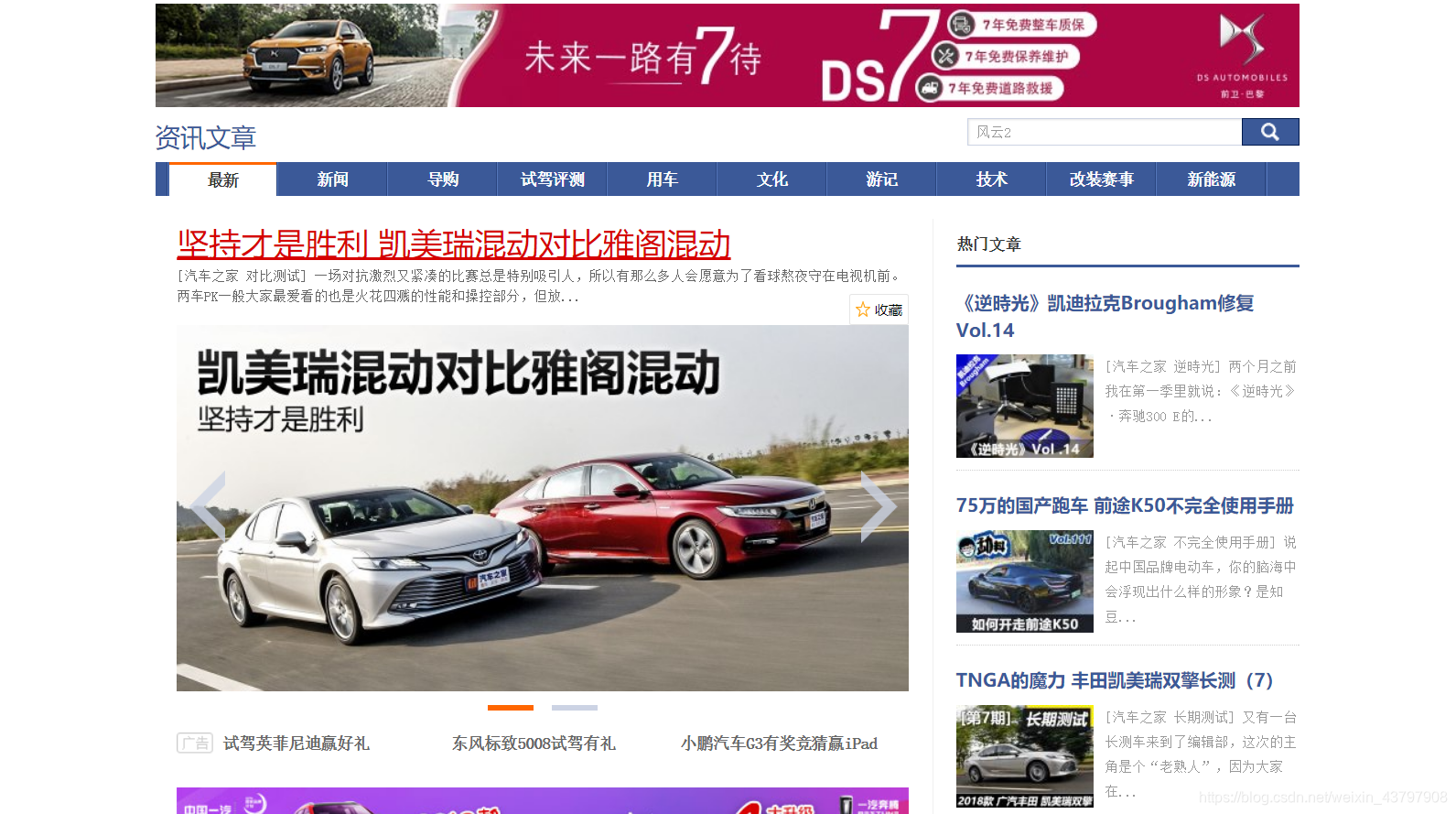
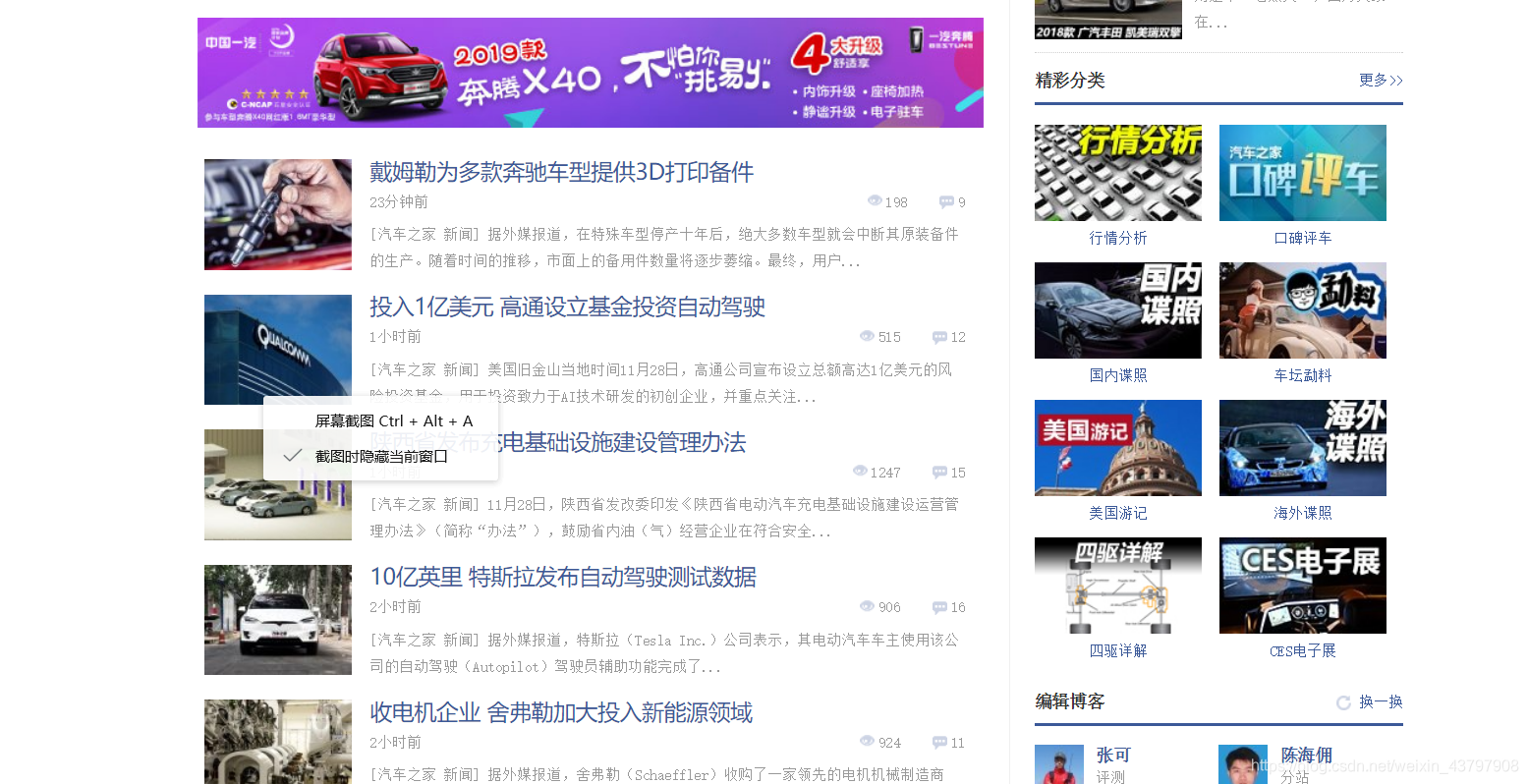
這是網頁的原始碼,就是通過找標籤或者屬性來爬取特定的內容

程式碼如下
import requests
import uuid
from bs4 import BeautifulSoup
response = requests.get(url= ‘
‘’‘解決亂碼問題,以什麼樣的方式編碼就以什麼樣的方式解碼’’’
response.encoding = response.apparent_encoding
‘’‘將網頁的內容轉換成文字列印’’’
#print(response.text)
‘’‘文字轉換成物件,以什麼方式進行轉換’’’
soup = BeautifulSoup(response.text,features=‘html.parser’)#內建的轉換方式#html.parser
target = soup.find(id = ‘auto-channel-lazyload-article’)#根據屬性找
#print(target)
li_list = target.find_all(‘li’)#根據標籤找,返回的是列表型別,不是beautiflsop的物件沒有find函式
#print(li_list),i = li_list[0],是beautifulsoup的物件可以find
for i in li_list:
a = i.find(‘a’)
if a:
print(a.attrs.get(‘href’))#attrs表示找到a標籤的所有屬性,返回的是字典屬性,
# 意思就是a標籤中找到所有屬性中的href的屬性
txt = a.find(‘h3’).text#不加.txt其實是物件,加了就是字串
print(txt)
img_url = a.find(‘img’).attrs.get(‘src’)
img_url = ‘http:’+img_url
print(img_url)
img_response = requests.get(img_url)
file_name = str(uuid.uuid4()) + ‘.jpg’#隨機生成檔案的名字也就是數字
with open(file_name,‘wb’) as f:
f.write(img_response.content)#content返回的是位元組型別’’’
需要注意的問題就是 img_url = a.find(‘img’).attrs.get(‘src’)返回的是一個連結//www3.autoimg.cn/newsdfs/g29/M04/89/46/120x90_0_autohomecar__ChsEflwA9DWAQiYQAAFbz6MSQTo254.jpg但是直接訪問是不行的,所以要給加上http:變成一個可訪問的連結地址,然後再去儲存圖片
另外還需要注意的是:requests可能會自動給地址新增%0A,導致不能訪問
但是requests.get( ‘https://www.autohome.com.cn/all/#pvareaid=3311229’)
是正常的
url = ‘
requests.get(url)是不正常的無法訪問
所以‘%0A’並不是被訪問的網站加的,而是requets乾的,%0A是十六進位制的換行,即’\n’,所以需要去掉換行,可將requrl按行分裂,因為是一個列表所以可以取第一部分:res=requests.get(url.split(’\n’)[0])
以下是結果,爬取成功