
圖的儲存和遍歷
圖的儲存
圖的儲存一般有兩種方式:鄰接矩陣和鄰接表
鄰接矩陣
設圖G(V,E)的頂點標號為0,1,……n-1,則令二維陣列G[n][n]的兩維分別表示圖的頂點標號。
即如果G[i][j]等於1,指頂點i和頂點j之間有邊,如果G[i][j]等於0,指頂點i和頂點j之間沒有邊,
如果為有權圖,則令G[i][j]存放邊權。
但如果題目中頂點數過大,可能會造成記憶體超限。
鄰接表
圖的常用儲存結構之一,由表頭結點和表結點兩部分組成,其中表頭結點儲存圖的各頂點,
表結點用單向連結串列儲存表頭結點所對應頂點的相鄰頂點(也就是表示了圖的邊)。
在有向圖裡表示表頭結點指向其它結點(a->b),無向圖則表示與表頭結點相鄰的所有結點(a—b)
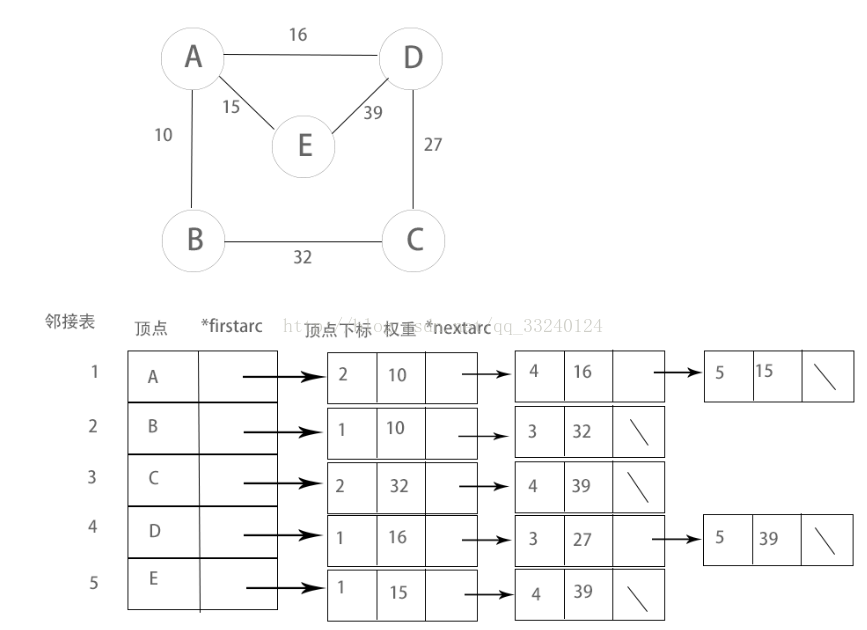
//表頭結點(表示圖的頂點)
struct vnode{
char data; //頂點資料,這裡用字元表示
struct arcnode * firstarc; //指標指向第一條邊
};
//表結點(表示圖的邊)
struct arcnode{
int wt; //權重
int adjvex; //頂點下標
struct arcnode *nextarc; //指標指向下一條邊
};
typedef struct arcnode * Arc;
//圖 圖的遍歷
用DFS遍歷圖
沿著一條路徑直到無法繼續前進,才退回到路徑上離當前頂點最近的還存在未訪問分支頂點的岔道口,並前往訪問那些未訪問的分支節點,直至遍歷完成
* 連通分量:在無向圖中,如果兩個頂點可以互相到達,則稱這兩個頂點連通,如果圖G(V,E)的任意兩個頂點都連通,則稱圖G為連通圖,
否則,稱圖G為非連通圖,且稱其中的極大連通子圖為連通分量。
* 強連通分量:在有向圖中,如果兩個頂點可以各自通過一條有向路徑到達另一個頂點,則稱這兩個頂點強聯通。如果一個圖的任意兩個頂點都強聯通,
則稱這個圖為強連通圖;否則這個圖為非強連通圖,且稱其中的極大連通子圖為強聯通分量。
虛擬碼
DFS(u){
vis[u]=true;
for(從u出發能到達的所有頂點v)
if(vis[v]==false)
DFS(v);
}
DFSTrave(G){
for(G的所有頂點u)
if(vis[u]==false)
DFS(u);
}
鄰接矩陣實現
const int maxv=1000;
const int inf=1000000;
int n,G[maxv][maxv];
bool vis[maxv]={false};
void dfs(int u,int depth){
vis[u]=true;
for(int v=0;v<n;v++){
if(vis[v]==false&&G[u][v]!=inf){
dfs(v,depth+1);
}
}
}
void dfstrave(){
for(int u=0;u<n;u++){
if(vis[u]==false){
dfs(u,1);
}
}
}
鄰接表實現
vector<int> Adj[maxv];
int n;
bool vis[maxv] = {false};
void dfs(int u,int depth){
vis[u] =true;
for(int i=0;i<Adj[u].size();i++){
int v=Adj[u][i];
if(vis[v]==false){
dfs(v,depth+1);
}
}
}
void dfstrave(){
for(int u=0;u<n;u++){
if(vis[u]==false){
dfs(u,1);
}
}
}用BFS遍歷圖
類似樹的遍歷,遍歷圖需要使用一個佇列,通過反覆取出隊首頂點,將該頂點可到達的未曾加入過佇列的頂點全部入隊,直到佇列為空時遍歷結束。
虛擬碼
BFS(u){
queue q;
inq[u]=true;
while(q非空){
取出q的隊首元素加以訪問;
for(從u出發能到達的所有頂點v)
if(inq[v]==false){
將v入隊;
inq[v]=true;
}
}
}
BFSTrave(G){
for(G的所有頂點u)
if(inq[u]==false)
{
BFS(u);
}
}
鄰接矩陣實現
int n,G[maxv][maxv];
bool inq[maxv]={false};
void BFS(int u){
queue<int> q;
q.push(u);
inq[u]=true;
while(!q.empty()){
int u.q.front();
q.pop();
for(int v=0;v<n;v++){
if(inq[v]==false&&G[u][v]!=inf){
q.push(v);
inq[v]=true;
}
}
}
}
void BFSTrave(){
for(int u=0;u<n;u++){
if(inq[u]==false){
BFS(q);
}
}
}
鄰接表實現
vector<int> Adj[maxv];
int n;
bool inq[maxv]={false};
void BFS(int u){
queue<int> q;
q.push(u);
inq[u]=true;
while(!q.empty()){
int u=q.front();
q.pop();
for(int i=0;i<Adj[u].size();i++){
int v=Adj[u][i];
if(inq[v]==false){
q.push(v);
inq[v]=true;
}
}
}
}
void BFSTrave(){
for(int u=0;u<n;u++){
if(inq[u]==false){
BFS(q);
}
}
}例子:
#include<bits/stdc++.h>
using namespace std;
typedef struct
{
int edges[100][100];///鄰接矩陣
int n;
int e;
}graph;
bool vis[100];///訪問陣列
void creategraph(graph &G)
{
int i,j;
int s,t;
int v;
for(i=0;i<G.n;i++)
{
for(j=0;j<G.n;j++)
{
G.edges[i][j]=0;///鄰接表初始化
}
vis[i]=false;///訪問陣列初始化
}
for(i=0;i<G.e;i++)
{
cin>>s>>t>>v;///讀入頂點數邊數和權值
G.edges[s][t]=v;///賦值
}
}
void dfs(graph G,int v)
{
int i;
printf("%d ",v);
vis[v]=true;///訪問第v個定點,並將訪問陣列置為true
for(i=0;i<G.n;i++)
{
if(G.edges[v][i]!=0&&vis[i]==false)
{
dfs(G,i);///如果i未被訪問遞迴呼叫dfs
}
}
}
void bfs(graph G,int v)
{
queue<int>Q;
printf("%d ",v);
vis[v]=true;
Q.push(v);
while(!Q.empty())
{
int i,j;
i=Q.front();///取隊頭元素
Q.pop();///隊頭元素出隊
for(j=0;j<G.n;j++)
{///檢查所有鄰接點
if(G.edges[i][j]!=0&&vis[j]==false)
{
printf("%d ",j);
vis[j]=true;
Q.push(j);
}
}
}
}
int main()
{
int n,e;
while(1)
{
puts("輸入圖的頂點數和邊數:");
cin>>n>>e;
graph G;
G.n=n;
G.e=e;
creategraph(G);
puts("輸出深度優先遍歷序列:");
dfs(G,0);
puts("\n");
creategraph(G);
puts("輸出廣度優先遍歷序列:");
bfs(G,0);
puts("\n");
}
return 0;
}
相關推薦
圖的儲存和遍歷
圖的儲存 圖的儲存一般有兩種方式:鄰接矩陣和鄰接表 鄰接矩陣 設圖G(V,E)的頂點標號為0,1,……n-1,則令二維陣列G[n][n]的兩維分別表示圖的頂點標號。 即如果G[i][j]等於1,指頂點i和頂點j之間有邊,如果G[i][j]等於0,指頂
圖的儲存和遍歷C++實現
最近在做一些OJ題目時,感覺自己圖的應用還不夠熟練。所以又翻書看別人的部落格複習了一下,現把圖的常用內容總結如下: 圖的常用儲存方法有:鄰接矩陣和鄰接表 遍歷方法有:按深度遍歷(DFS),按廣度遍歷(BFS) 下面的程式碼都是C++寫的,用了一些STL庫的容器:
集合巢狀儲存和遍歷元素的示例
1 /** 2 * @Auther: lzy 3 * @Date: 2018/12/12 16:07 4 * @Description: 集合巢狀儲存和遍歷元素的示例 5 */ 6 public class ListTest { 7 public static void m
集合中的集合_儲存和遍歷(增強型for迴圈和迭代器)
package GuanQia3_test2_集合中套集合_第一次沒想明白; /* * 一個學科中有若干班級,每一個班級又有若干學生。整個學科一個大集合, * 若干個班級分為每一個小集合(集合巢狀之HashSet巢狀HashSet)。要求如下 * 1、 學生類有兩個屬
Java中ArrayList集合巢狀儲存和遍歷
student類: package day16_Test; /* * 學生類: * 成員變數:姓名、年齡 * 成員方法 * 構造方法 * *
PAT 1138 Postorder Traversal(二叉樹的儲存和遍歷)
題意:給出二叉樹的前序和中序遍歷,給出其後序遍歷的第一個元素。 思路:根據前序和中序遍歷的結果得到二叉樹的具體構造,再進行後序遍歷。 程式碼: #include <cstdio> #in
HashSet的儲存和遍歷
1、特點 1、HashSet實現 Set 介面,由雜湊表(實際上是一個 HashMap 例項)支援。 2、它不保證 set 的迭代順序;特別是它不保證該順序恆久不變。此類允許使用 null 元素
資料結構之 二叉樹的儲存和遍歷總結
知道前序(包括空結點 下面程式碼用’,’代替)建立一個二叉樹,前序 中序 後序 層序輸出 如何求葉子結點數, 如何求二叉樹深度。 #include<stdio.h> #include<stdlib.h> #include<st
資料結構作業14—圖的概念 儲存結構和遍歷
2-1若無向圖G =(V,E)中含7個頂點,要保證圖G在任何情況下都是連通的,則需要的邊數最少是: (3分) A.16 B.21 C.15 D.6 作者: DS課程組 單位: 浙江大學 2-2對於有向圖,其鄰接矩陣表示比鄰接表
資料結構作業14—圖的概念 儲存結構和遍歷(判斷題)
1-1用鄰接矩陣法儲存圖,佔用的儲存空間數只與圖中結點個數有關,而與邊數無關。 (1分) T F 作者: DS課程組 單位: 浙江大學 1-2用鄰接表法儲存圖,佔用的儲存空間數只與圖中結點個數有關,而與邊數無關。 (1分) T
圖的廣度遍歷和深度遍歷
初始化 -- fin num 方法 技術分享 else 全部 nts /* 圖的遍歷方法主要有兩種:一種是深度優先遍歷。一種是廣度優先遍歷。圖的深度優先遍歷類同於樹的先根遍歷。圖的廣度遍歷類同樹的層次遍歷 一:連通圖的深度優先遍歷算法 圖的深度優先遍歷算法是遍歷
JS實現圖的建立和遍歷
圖分為無向圖和有向圖 圖的儲存結構有鄰接矩陣、鄰接表、十字連結串列、鄰接多重表這四種,最常用的是前兩種 本篇主要是利用鄰接矩陣實現無向圖的建立和遍歷(深度優先、廣度優先),深度優先其實就是二叉樹裡的前序遍歷 利用鄰接
整形圖的深度遍歷和廣度遍歷
比較簡單的實現,圖採用鄰接矩陣的儲存方式,且沒有加上覆制建構函式和過載運算子。 #include <iostream> #include<stdexcept> #include<stdio.h> using namespace std; struc
圖的深度遍歷和廣度遍歷
理論部分 圖的深度遍歷和廣度遍歷都不算很難像極了二叉樹的前序遍歷和層序遍歷,如下面的圖,可以用右邊的鄰接矩陣進行表示,假設以頂點0開始對整幅圖進行遍歷的話,兩種遍歷方式的思想如下: 1. 深度優先遍歷(depthFirstSearch—DFS) 由初始頂點開始,沿著一條道一直走,
資料結構——圖的儲存與遍歷(鄰接矩陣)
圖的儲存與遍歷(鄰接矩陣) #include<stdio.h> #include<stdlib.h> #define MAXVEX 20 /*最大頂點個數*/ #define INFINITY 32767
圖的鄰接矩陣儲存及遍歷
這裡採用圖的鄰接矩陣儲存(即為二維陣列) 遍歷:DFS和BFS #include<cstdio> #include<iostream> #include<cstring> #include<queue> using namespace s
二維陣列的動態儲存(遍歷方陣,求各元素的和)
#define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std; int **InitialArray(int row,int column) //動態建立陣列並初始化 {int
圖 | 兩種遍歷方式:深度優先搜尋(DFS、深搜)和廣度優先搜尋(BFS、廣搜)
前邊介紹了有關圖的 4 種儲存方式,本節介紹如何對儲存的圖中的頂點進行遍歷。常用的遍歷方式有兩種:深度優先搜尋和廣度優先搜尋。 深度優先搜尋(簡稱“深搜”或DFS) 圖 1 無向圖 深度優先搜尋的過程類似於樹的先序遍歷,首先從例
ARCEngine中右鍵圖層以遍歷圖層名和欄位名
private void axTOCControl1_OnMouseDown(object sender, ITOCControlEvents_OnMouseDownEvent e) { esri
二叉樹的儲存方式和遍歷方式
二叉樹: 二叉樹的每個節點至多有兩個子樹。如這個二叉樹,其中1,2有兩個子樹,3只有左子樹,5有右子樹,4,6,7沒有子樹。 二叉樹有兩種儲存方式: 第一種,陣列表示。用陣列儲存方式就是用一組連續的儲存單元儲存二叉樹的資料元素。