
快速排序與隨機化快排執行速度實驗比較
目錄
快速排序與隨機化快速排序
在電腦科學與數學中,一個排序演算法(英語:Sorting algorithm)是一種能將一串資料依照特定排序方式進行排列的一種演算法。最常用到的排序方式是數值順序以及字典順序。有效的排序演算法在一些演算法(例如搜尋演算法與合併演算法)中是重要的,如此這些演算法才能得到正確解答。排序演算法也用在處理文字資料以及產生人類可讀的輸出結果。基本上,排序演算法的輸出必須遵守下列兩個原則:
1、 輸出結果為遞增序列(遞增是針對所需的排序順序而言)
2、 輸出結果是原輸入的一種排列、或是重組
雖然排序演算法是一個簡單的問題,但是在計算機資料處理上發揮了很大的作用,從電腦科學發展以來,在此問題上也已經有大量的研究。[1]
快速排序
快速排序用到了分治思想,同樣的還有歸併排序。乍看起來快速排序和歸併排序非常相似,都是將問題變小,先排序子串,最後合併。不同的是快速排序在劃分子問題的時候經過多一步處理,將劃分的兩組資料劃分為一大一小,這樣在最後合併的時候就不必像歸併排序那樣再進行比較。但也正因為如此,劃分的不定性使得快速排序的時間複雜度並不穩定。[2]
快速排序的期望複雜度是O(nlogn),但最壞情況下可能就會變成O(n^2),最壞情況就是每次將一組資料劃分為兩組的時候,分界線都選在了邊界上,使得劃分了和沒劃分一樣,最後就變成了普通的選擇排序了。
快速排序使用分治法(Divide and conquer)策略來把一個
步驟為:
1、從數列中挑出一個元素,稱為"基準"(pivot),
2、重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的後面(相同的數可以到任一邊)。在這個分割槽結束之後,該基準就處於數列的中間位置。這個稱為分割槽(partition)操作。
3、遞迴地(recursive)把小於基準值元素的子數列和大於基準值元素的子數列排序。
遞迴的最底部情形,是數列的大小是零或一,也就是永遠都已經被排序好了。雖然一直遞迴下去,但是這個演算法總會結束,因為在每次的迭代(iteration)中,它至少會把一個元素擺到它最後的位置去。[
選定基準:最後一個元素。

排序分割槽:

遞迴:

隨機化快速排序
當輸入序列為有序時,快排的時間複雜度最大,效率最低,為了使快排在任何序列中,效率始終處於最優,引入隨機化的思想。隨機化即是隨機地選擇主元,使其執行時間不依賴於輸入序列的順序。
經分析, 隨機化快排的演算法效率是Θ(nlgn)。
實現:我們只需在選取主元時加入隨機因素即可。其他與快排一樣。

快排與隨機化快排效能分析
不同配置計算機的執行效果
計算機1(簡稱i7)配置:
硬體:CPU:Intel(R)i7-6500U 2.5GHz,記憶體:8.00GB
軟體:系統:Windows 7專業版 64位作業系統,編譯器:eclipse
計算機2(簡稱i3)配置:
硬體:CPU:Intel(R)i3-3110M 2.4GHz,記憶體:4.00GB
軟體:系統:Windows 7旗艦版 32位作業系統,編譯器:eclipse
實驗資料均是取同一資料量100次計算所花時間的平均值
實驗結果:
計算機i3資料:
|
演算法 |
1w |
5w |
10w |
50w |
100w |
500w |
1000w |
|
確定性快排 |
1 |
6 |
11 |
62 |
142 |
777 |
1611 |
|
隨機化快排 |
2 |
5 |
13 |
78 |
161 |
877 |
1815 |
折線圖:
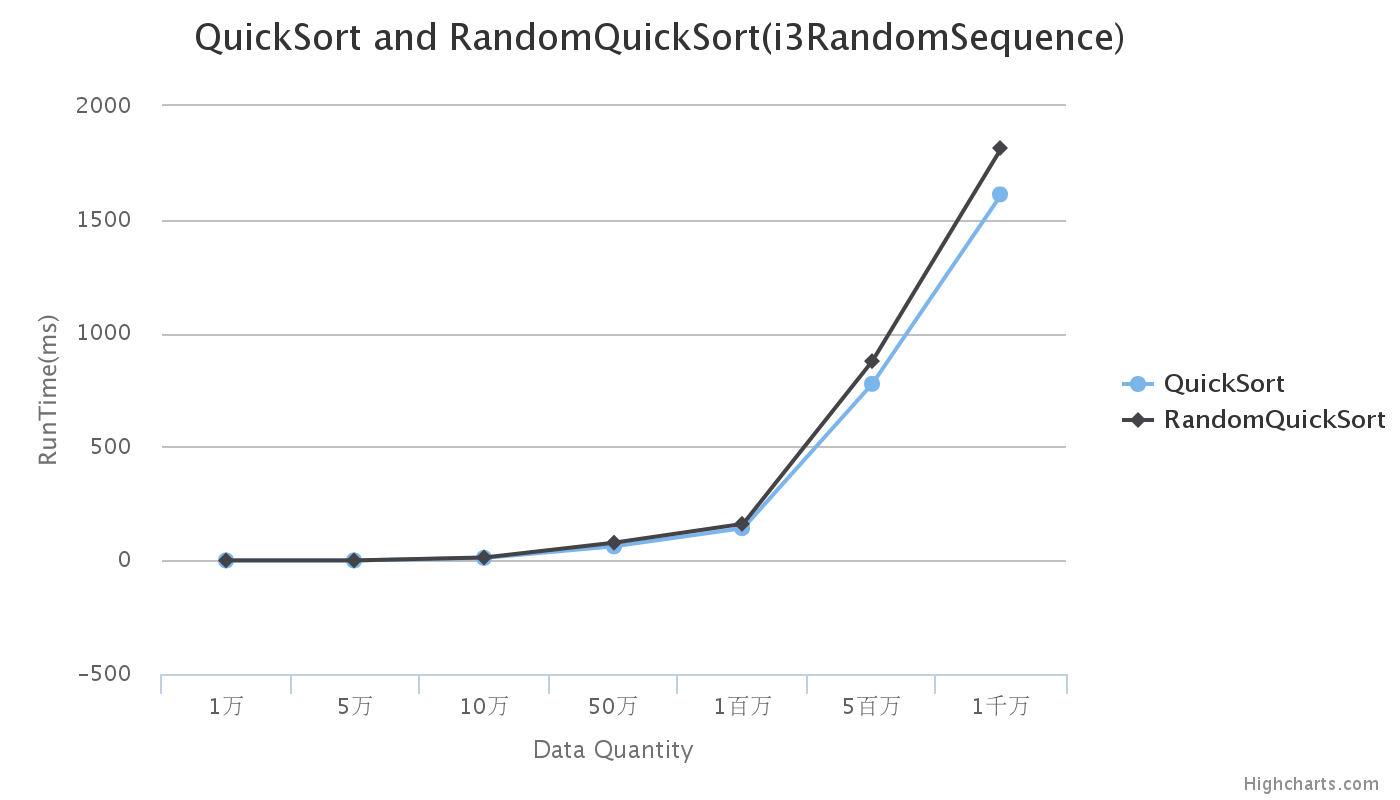
從資料與圖可以看出,在計算速度上,同一資料量的快速排序中,確定性演算法要比隨機化演算法迅速,而且隨著資料量的增大,差距越來越明顯。從圖中還可以看出,當資料量遞增速度慢些時,圖形可以近似成一條曲線,該曲線就是它的期望時間複雜度O(nlogn)。
計算機i7資料:
|
演算法 |
1w |
5w |
10w |
50w |
100w |
500w |
1000w |
|
確定性快排 |
1 |
4 |
10 |
54 |
112 |
655 |
1240 |
|
隨機化快排 |
1 |
4 |
11 |
52 |
127 |
644 |
1389 |
折線圖:

從資料與圖可以看到與i3一致的結論,然而i7幾乎每一項計算速度都比i3的要快。從圖中兩條折線中,在資料達到500萬時出現明顯差距,確定性快排要比隨機化快排快很多。查了一些資料,以及老師上課的知識中知道當資料量達到一定程度時,隨機化快排要比確定性快排在資料隨機的前提下計算速度要快,為了找到那個臨界點,我提升了資料的計算量,然而,當資料提到2000萬以上時,出現了溢位,Java錯誤提示:
問題描述
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
可能原因
你沒有為你的應用程式執行時給予足夠多的可用記憶體。
解決方案
增加 JVM堆可用大小,或者減少你的應用程式所需的記憶體總量。設定jvm heap大小,用eclipse寫/除錯java程式。在eclipse的配置檔案eclipse.ini中設定-vmargs –Xms40m –Xmx800m. [4]
調整後的i7資料可以執行到1億。
|
演算法 |
1w |
5w |
10w |
50w |
100w |
500w |
1000w |
5000w |
10000w |
|
確定性快排 |
1 |
4 |
10 |
54 |
112 |
655 |
1240 |
7782 |
14576 |
|
隨機化快排 |
1 |
4 |
11 |
52 |
127 |
644 |
1389 |
7308 |
14092 |
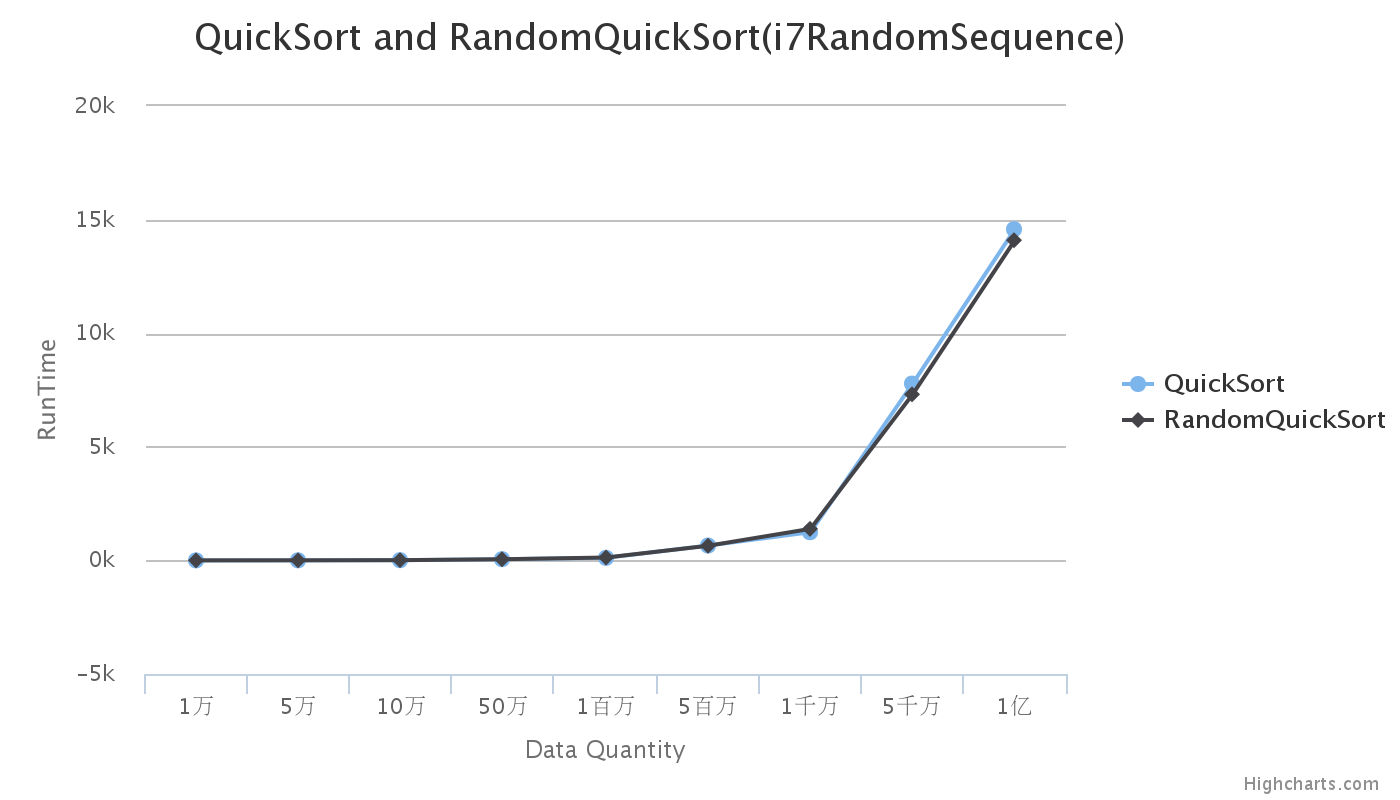
當資料量達到5千萬時,隨機快排比確定性快排時間要短,速度要快。
用同樣的方法改進i3時,因為i3記憶體較小,所以基本沒有改變其計算資料量的大小。因此比較i3與i7只比較前面1千萬的資料。
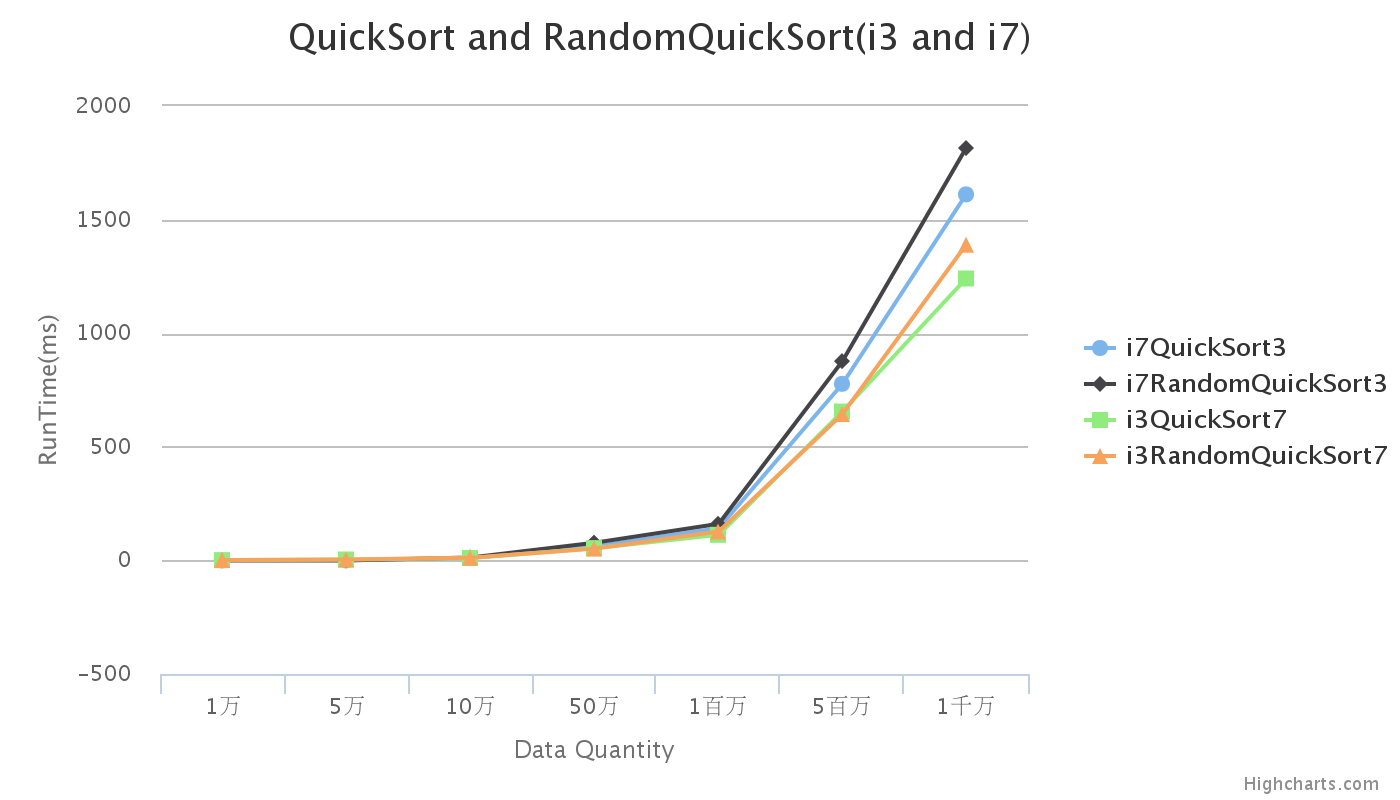
從圖中,i7計算速度比i3計算速度快出很多,而且隨著計算量的增大,差距越來越明顯。所以一個好的軟硬體環境對於資料的處理有很大的幫助,反之,則影響處理工作的效率。
不同初始序列對快速排序的影響
由於初始序列對排序有很大的影響,特別是已經有序的序列對確定性快速排序是其最壞的情況,時間複雜度甚至達到O(n^2)。因此對其初始序列的情況進行專門的實驗。
對初始序列處理為:隨機序列、降序序列、升序序列以及重複序列。
資料:
注:資料都是對同一資料量生成不同的相關序列進行100次計算得到的下取整平均值。
|
資料量 |
演算法 |
隨機序列 |
降序序列 |
升序序列 |
重複序列 |
|
1億 |
確定性演算法 |
14576 |
13915 |
13679 |
14282 |
|
隨機性演算法 |
14092 |
5479 |
4549 |
13220 |
|
|
7500w |
確定性演算法 |
10403 |
10446 |
10276 |
10446 |
|
隨機性演算法 |
9631 |
4361 |
3406 |
9639 |
|
|
5000w |
確定性演算法 |
7782 |
6618 |
6723 |
6733 |
|
隨機性演算法 |
7308 |
2250 |
2263 |
6240 |
|
|
2500w |
確定性演算法 |
3262 |
3296 |
3218 |
3268 |
|
隨機性演算法 |
3061 |
1315 |
1101 |
3039 |
|
|
1000w |
確定性演算法 |
1240 |
967 |
1272 |
1243 |
|
隨機性演算法 |
1389 |
414 |
547 |
1193 |
|
|
750w |
確定性演算法 |
916 |
951 |
904 |
917 |
|
隨機性演算法 |
871 |
383 |
395 |
859 |
|
|
500w |
確定性演算法 |
655 |
614 |
644 |
581 |
|
隨機性演算法 |
644 |
219 |
288 |
547 |
|
|
250w |
確定性演算法 |
289 |
298 |
281 |
280 |
|
隨機性演算法 |
274 |
133 |
129 |
270 |
|
|
100w |
確定性演算法 |
112 |
109 |
109 |
108 |
|
隨機性演算法 |
127 |
40 |
50 |
104 |
|
|
75w |
確定性演算法 |
79 |
81 |
79 |
81 |
|
隨機性演算法 |
76 |
29 |
28 |
75 |
|
|
50w |
確定性演算法 |
54 |
52 |
49 |
49 |
|
隨機性演算法 |
52 |
19 |
16 |
50 |
|
|
25w |
確定性演算法 |
24 |
25 |
24 |
23 |
|
隨機性演算法 |
24 |
12 |
10 |
23 |
|
|
10w |
確定性演算法 |
10 |
9 |
9 |
7 |
|
隨機性演算法 |
11 |
3 |
3 |
13 |
|
|
7.5w |
確定性演算法 |
7 |
7 |
7 |
6 |
|
隨機性演算法 |
7 |
3 |
3 |
6 |
|
|
5w |
確定性演算法 |
4 |
4 |
4 |
5 |
|
隨機性演算法 |
4 |
1 |
1 |
3 |
|
|
2.5w |
確定性演算法 |
1 |
2 |
2 |
3 |
|
隨機性演算法 |
2 |
1 |
0 |
2 |
|
|
1w |
確定性演算法 |
1 |
0 |
0 |
0 |
|
隨機性演算法 |
1 |
0 |
0 |
0 |
折線圖:
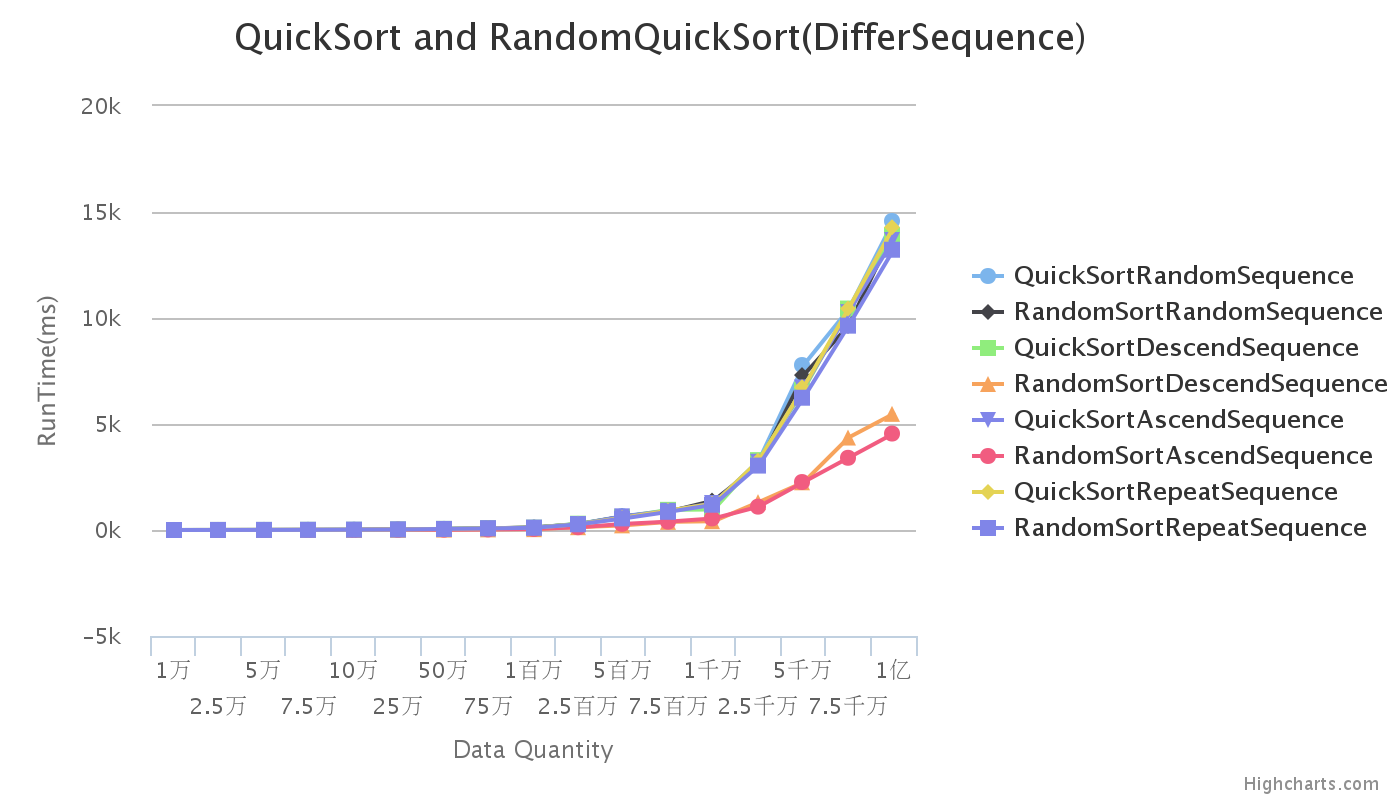
可以看出廚師序列的隨機序列與重複序列基本一致,快速排序的隨機性演算法在初始有序的情況下效率非常高。為了看得更清楚,我們分開對比。
初始序列為降序序列與升序序列的對比:
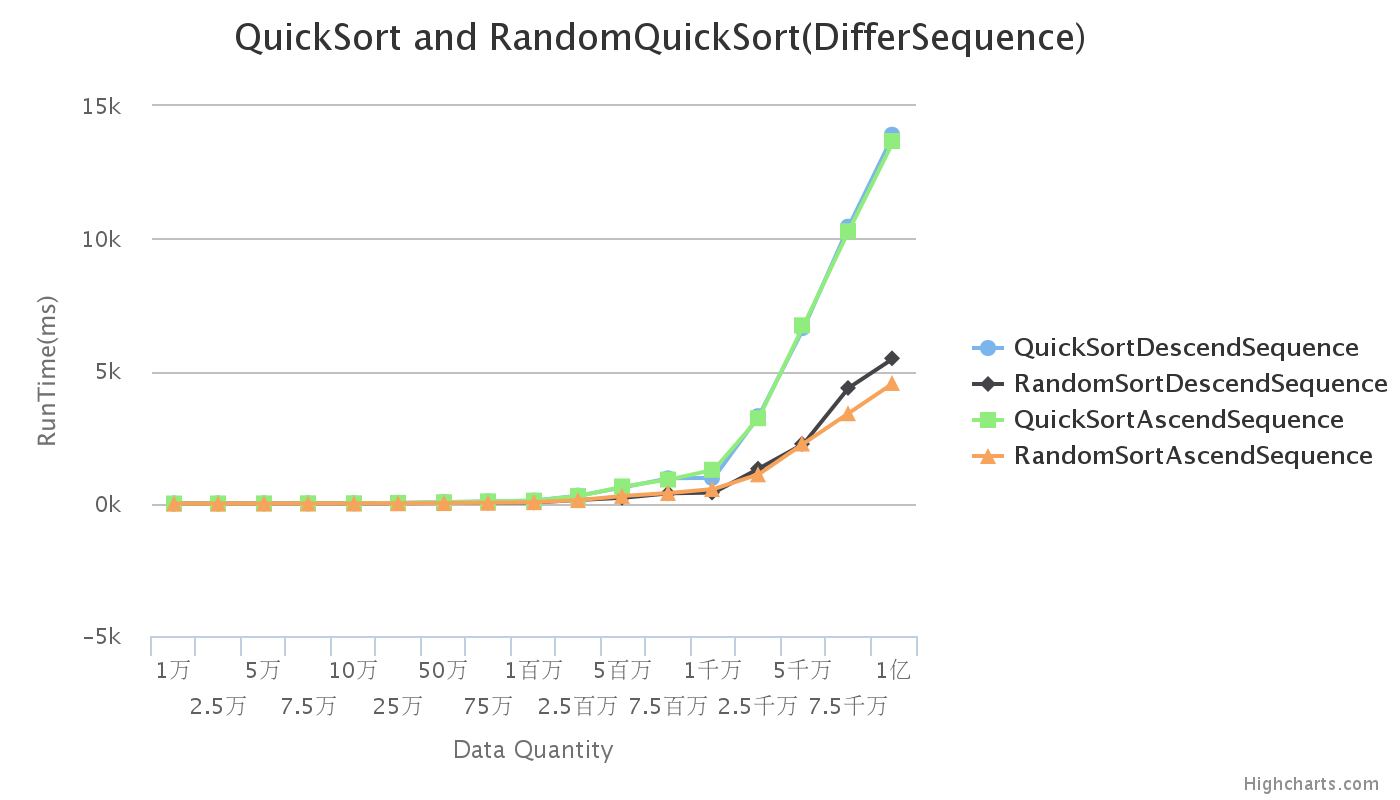
由圖可以看出在初始序列有序的情況下,隨機化演算法比確定性演算法快很多,效率更高,而且隨著資料量的增大,差距越來越明顯。而確定性演算法隨著資料量的增長其計算時間呈指數增長,效率很差,時間複雜度達到最壞情況的O(n^2)。
初始序列為降序的隨機性快排演算法在資料量達到5千萬到1億之間,其排序所耗時間要比升序的隨機性快排演算法要多,效率要低。而確定性演算法不管升序還是降序,其計算時間基本一致。
初始序列為隨機序列與降序序列的對比:

初始序列為隨機序列與降序序列其在確定性演算法中曲線基本重疊,資料一致,但是在初始有序的前提下,隨機化演算法運算時間大大減少,效率越來越高。
因為降序與升序曲線基本一致,就不對比隨機序列與升序序列了。
初始序列為隨機序列與重疊序列的對比:
注:重疊序列的處理:重疊的實現是將要實現的資料量分成10個組,然後將其中一個組隨機生成資料,然後將該組資料逐一複製到其他組中,這就形成了有10組資料的重複。
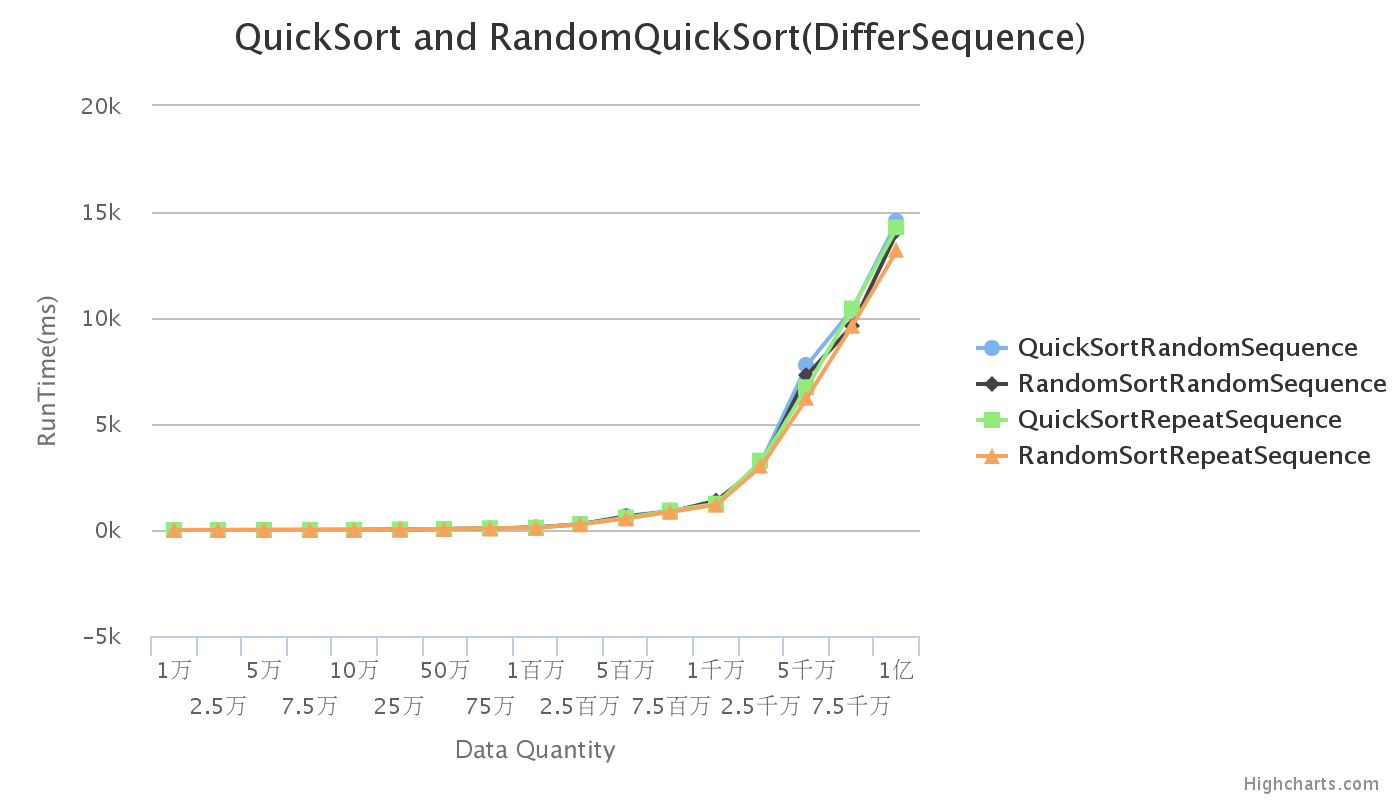
由圖,曲線基本重合,因此資料重複對快速排序基本沒有影響。
資料相對於其多運算的平均值的波動
我們取資料時,一般是取其同一資料量大小,不同隨機生成序列的多次運算的平均時間,然而其單次運算的時間相對於其多次的平均時間波動如何呢?我研究了一下。
這是資料量為1百萬的波動圖(i7隨機序列資料)

其時間資料相對於平均數(-3,+8)之間波動。
我們看大資料:下面是資料量為1億的波動

其波動範圍達到了(-880,+1500),波動越來越大,越來越明顯。
對比其資料量對其單個數據的平均值波動影響:

上面畫出的較為明顯的1百萬的資料波動圖在這個集合圖中只能顯示出一條直線,1千萬的資料量也成了一條直線(藍黑“直線”),當資料量為5千萬時,出現了波動,但也不太明顯,只有1億的資料量才有明顯清晰的波動情況。因此,資料量越大,其單個數據相對於其多次運算的均值波動更為強烈。在資料處理中,其具體取值在資料量越來越大的情況下顯得尤為重要。
總結
這篇文章是我研一來的第一篇文章,以前在CSDN上只看別人的,現在我覺得我有必要自己寫一些東西,來記錄一下我的學習過程,對自己也是一個交代。希望以後能繼續寫自己原創的博文。這篇參考了一些大牛的作品,下面都有參考文獻。如果我的作品有幸被別人引用時,也希望你能夠標註一下,這是一個好習慣,謝謝。
下面是我提交的作業的總結。
因為之前沒有做過此類的研究,所以當老師將此作業交代下來後,不知所措,不知道怎麼分析與畫圖。之後在網路資料、師哥們的熱心幫助與同學們的相互討論中漸漸有了眉目,對於自己要做的事情有了清晰的目標。
相對於怎麼來對比確定性快排與隨機化快排,老師也給了很多入手的方向,包括它的初始序列特點、相關論文的介紹、優化方法等。我自己選了針對不同頻率處理器與不同大小記憶體的計算機進行運算比較;針對其隨機、降序、升序與重複的初始序列進行排序時間比較;針對每次運算相對於其多次運算均值的波動情況分析。在這些分析與資料處理中,學到了很多知識,知道了一個演算法優劣的具體比較過程,對以後論文及其他方面能力的學習與提升有很大的幫助。
總體來說,配置較好的機器能更快速地處理資料;資料量在5千萬到1億之間(1億以上資料量執行不出),初始為隨機的序列,用隨機化演算法耗時低於確定性演算法,5千萬資料量以下基本高於確定性演算法;初始有序對於確定性演算法處於最壞的情況,耗時最長,隨機化演算法反之;資料量越大單個數據對於其多次計算均值波動越大。
問題
原本想處理不同編譯器對於其快速排序與隨機化快排的影響,但是當我想做這個時,下載編譯軟體(刷了系統,無此軟體)耗時太長,網速太差,就此作罷。
問題:
1、同一資料量i3上面會出現有計算結果0的情況,i7不會出現,這是什麼情況?
2、9 4 5 4 5 5 5 4 5 4 5 55 4 5 5 5 4 5 4前期大後期穩定?在序列中很多次出現前面資料先計算的資料相對後面的序列要大。
3、均值下取整會影響平均值?當資料量小時,會出現平均值小數情況,其上下取整都會影響其均值,進而影響其波動情況。
4、到微秒的整算,資料小時誤差較大?
參考文獻
老師修改意見
老師在課上對大家作業進行了點評,具體意見總結如下:(不一定是特定本文章的問題,具體的我還沒有修改,先記錄一下吧,不然很快忘了)
1 圖表都要寫表名與圖名,表名在表上,圖名在圖下
2 圖表要居中,編號要有序
3 以後發表論文可能是黑白印刷,所以要注意自己的圖表除了顏色區分外還要有具體形狀或標註區分
4 圖的波動要明顯,注意自己的單位長度的設定
5 文章錯別字一定要注意,不然會影響自己在投稿期刊審稿人的印象
6 此篇文章還可以考慮在雙核四核等不同處理器下程式設計實現高效率計算
7 精度要確定好,單位要標註
8 變數斜體
9 圖形佈局一般把說明放在圖中,減少空間
10 均值計算,去掉最高與最低進行平均
相關推薦
快速排序與隨機化快排執行速度實驗比較
目錄 快速排序與隨機化快速排序 在電腦科學與數學中,一個排序演算法(英語:Sorting algorithm)是一種能將一串資料依照特定排序方式進行排列的一種演算法。最常用到的排序方式是數值順序以及字典順序。有效的排序演算法在一些演算法(例如搜尋演算法與合併演算法)中
演算法導論(一):快速排序與隨機化快排
排序演算法是演算法學習的第一步,想當初我學的第一個演算法就是選擇排序,不過當時很長一段時間我都不清楚我到底用的是選擇還是冒泡還是插入。只記得兩個for一個if排序就完成了。 再後來更系統地接觸演算法,才發現那才是排序演算法隊伍中小小而基本的一員。 買的《演算
分治法:快速排序,3種劃分方式,隨機化快排,快排快,還是歸併排序快?
快速排序不同於之前瞭解的分治,他是通過一系列操作劃分得到子問題,不同之前的劃分子問題很簡單,劃分子問題的過程也是解決問題的過程 我們通常劃分子問題儘量保持均衡,而快排缺無法保持均衡 快排第一種劃分子問題實現方式,左右填空的雙指標方式 def partition_1(arr,low
分治法在排序演算法中的應用(JAVA)--快速排序(Lomuto劃分、Hoare劃分、隨機化快排)
分治法在排序演算法中的應用 快速排序:時間複雜度O(nlogn) 如果說歸併排序是按照元素在陣列中的位置劃分的話,那麼快速排序就是按照元素的值進行劃分。劃分方法由兩種,本節將主要介紹Huare劃分,在減治法在查詢演算法中的應用(JAVA)--快速查詢這篇文章中講述了Lomu
排序演算法---快速排序,隨機快速排序和雙路快排(python版)
[原文連結](https://blog.csdn.net/m0_37519490/article/details/80648011) 1、什麼是快速排序演算法? 快速排序是由東尼·霍爾所發展的一種排序演算法,速度快,效率高,也是實際中最常用的一種演算法
演算法導論 第七章:快速排序 筆記(快速排序的描述、快速排序的效能、快速排序的隨機化版本、快速排序分析)
快速排序的最壞情況時間複雜度為Θ(n^2)。雖然最壞情況時間複雜度很差,但是快速排序通常是實際排序應用中最好的選擇,因為它的平均效能很好。它的期望執行時間複雜度為Θ(n lg n),而且Θ(n lg n)中蘊含的常數因子非常小,而且它還是原址排序的。 快速排序是一種排序演算法,對包含n個數的
演算法導論 第七章快速排序與隨機快速排序
view plaincopy to clipboardprint?#include <iostream> #include <cstdlib> #include <time.h> using namespace std;
快速排序 與 隨機快速排序 演算法分析
快速排序是由東尼·霍爾所發展的一種排序演算法。在平均狀況下,排序 n 個專案要Ο(n log n)次比較。在最壞狀況下則需要Ο(n2)次比較,但這種狀況並不常見。事實上,快速排序通常明顯比其他Ο(n log n) 演算法更快,因為它的內部迴圈(inner loop)可以在大
快速排序(Java隨機位置快排實現)
package cn.edu.nwsuaf.cie.qhs; import java.util.Random; import java.util.Scanner; // public class QuickSort { private int initArray[]; public i
深入理解快速排序(隨機快排、雙路快排、三路快排)
快速排序可以說是20世紀最偉大的演算法之一了。相信都有所耳聞,它的速度也正如它的名字那樣,是一個非常快的演算法了。當然它也後期經過了不斷的改進和優化,才被公認為是一個值得信任的非常優秀的演算法。 本文將結合快速排序的三方面進行比較和深入解析。 快速排
Java排序算法分析與實現:快排、冒泡排序、選擇排序、插入排序、歸並排序(二)
第一個元素 spa insert 循環 冒泡排序 author 高級算法 ins -s 一、概述: 上篇博客介紹了常見簡單算法:冒泡排序、選擇排序和插入排序。本文介紹高級排序算法:快速排序和歸並排序。在開始介紹算法之前,首先介紹高級算法所需要的基礎知識:劃分、遞歸,並順
資料結構與算法系列10--排序演算法(歸併、快排)
歸併排序 思想: 歸併排序的核心思想還是蠻簡單的。如果要排序一個數組,我們先把陣列從中間分成前後兩部分,然後對前後兩部分分別排序,再將排好序的兩部分合並在一起,這樣整個陣列就都有序了。 #歸併排序 def merge_sort(a): n=len(a) merge_
Java排序演算法分析與實現:快排、氣泡排序、選擇排序、插入排序、歸併排序(一)
轉載 https://www.cnblogs.com/bjh1117/p/8335628.html 一、概述: 本文給出常見的幾種排序演算法的原理以及java實現,包括常見的簡單排序和高階排序演算法,以及其他常用的演算法知識。 簡單排序:氣泡排序、選擇排序、
java實現排序算法:快排、冒泡排序、選擇排序、插入排序、歸並排序
結果 快速 post ont pla emp string () tro 一、概述:本文主要介紹常見的幾種排序算法的原理以及java實現,包括:冒泡排序、選擇排序、插入排序、快速排序、歸並排序等。 二、冒泡排序: (1)原理: 1、從第一個數據開始,與第二個數據相比較,
排序算法的C語言實現(上 比較類排序:插入排序、快速排序與歸並排序)
大於等於 額外 通過命令 無序 tro 需要 目錄 線性 如何選擇 總述:排序是指將元素集合按規定的順序排列。通常有兩種排序方法:升序排列和降序排列。例如,如整數集{6,8,9,5}進行升序排列,結果為{5,6,8,9},對其進行降序排列結果為{9,8,6,5}。雖然排序的
安卓快速排序與冒泡排序
java int end star ear cal ber instance pretty main 冒泡排序 private void swap(int[] arrays, int i, int j) { int temp;
快速排序和隨機快速排序
轉載http://blog.csdn.net/always2015/article/details/46523531 一、問題描述 實現對陣列的普通快速排序與隨機快速排序 (1)實現上述兩個演算法 (2)統計演算法的執行時間 (3)分析效能差異,作出總結 二、演
快速排序與歸併排序------JavaScript實現
1.快速排序 演算法步驟: 在陣列中找到基準點(flag),其他數與之比較。 建立兩個陣列,小於基準點的數儲存在左邊陣列,大於基準點的數儲存在右邊陣列。 拼接陣列,然後左邊陣列與右邊陣列繼續執行1、2兩個步驟,直到最後完成陣列排序。(該步驟可以看出演算法存在迭代性質)
雙路快速排序演算法及三路快速排序演算法視覺化
雙路快速排序演算法 工具類 import java.awt.*; import java.awt.geom.Ellipse2D; import java.awt.geom.Rectangle2D; import java.lang.Interrup