
try catch 對效能影響
引言
之前一直沒有去研究try catch的內部機制,只是一直停留在了感覺上,正好這週五開會交流學習的時候,有人提出了相關的問題。藉著週末,正好研究一番。
討論的問題
當時討論的是這樣的問題:
比較下面兩種try catch寫法,哪一種效能更好。
for (int i = 0; i < 1000000; i++) {
try {
Math.sin(j);
} catch (Exception e) {
e.printStackTrace();
} try {
for (int i = 0; i < 1000000; i++) {
Math.sin(j);
}
} catch (Exception e) {
e.printStackTrace();
}結論
在沒有發生異常時,兩者效能上沒有差異。如果發生異常,兩者的處理邏輯不一樣,已經不具有比較的意義了。
分析
要知道這兩者的區別,最好的辦法就是檢視編譯後生成的Java位元組碼。看一下try catch到底做了什麼。
下面是我的測試程式碼
package com.kevin.java.performancetTest;
import org.openjdk.jmh.annotations.Benchmark;
/**
* Created by kevin on 16-7-10.
*/
public class ForTryAndTryFor {
public static void main(String[] args) {
tryFor();
forTry();
}
public static void tryFor() {
int j = 3 使用javap -c fileName.class輸出對應的位元組碼
$ javap -c ForTryAndTryFor.class
Compiled from "ForTryAndTryFor.java"
public class com.kevin.java.performancetTest.ForTryAndTryFor {
public com.kevin.java.performancetTest.ForTryAndTryFor();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: invokestatic #2 // Method tryFor:()V
3: invokestatic #3 // Method forTry:()V
6: return
public static void tryFor();
Code:
0: iconst_3
1: istore_0
2: iconst_0
3: istore_1
4: iload_1
5: sipush 1000
8: if_icmpge 23
11: iload_0
12: i2d
13: invokestatic #4 // Method java/lang/Math.sin:(D)D
16: pop2
17: iinc 1, 1
20: goto 4
23: goto 31
26: astore_1
27: aload_1
28: invokevirtual #6 // Method java/lang/Exception.printStackTrace:()V
31: return
Exception table:
from to target type
2 23 26 Class java/lang/Exception
public static void forTry();
Code:
0: iconst_3
1: istore_0
2: iconst_0
3: istore_1
4: iload_1
5: sipush 1000
8: if_icmpge 31
11: iload_0
12: i2d
13: invokestatic #4 // Method java/lang/Math.sin:(D)D
16: pop2
17: goto 25
20: astore_2
21: aload_2
22: invokevirtual #6 // Method java/lang/Exception.printStackTrace:()V
25: iinc 1, 1
28: goto 4
31: return
Exception table:
from to target type
11 17 20 Class java/lang/Exception
}好了讓我們來關注一下try catch 到底做了什麼。我們就拿forTry方法來說吧,從輸出看,位元組碼分兩部分,code(指令)和exception table(異常表)兩部分。當將java原始碼編譯成相應的位元組碼的時候,如果方法內有try catch異常處理,就會產生與該方法相關聯的異常表,也就是Exception table:部分。異常表記錄的是try 起點和終點,catch方法體所在的位置,以及宣告捕獲的異常種類。通過這些資訊,當程式出現異常時,java虛擬機器就會查詢方法對應的異常表,如果發現有宣告的異常與丟擲的異常型別匹配就會跳轉到catch處執行相應的邏輯,如果沒有匹配成功,就會回到上層呼叫方法中繼續查詢,如此反覆,一直到異常被處理為止,或者停止程序。(具體介紹可以看這篇文章How the Java virtual machine handles exceptions。)所以,try 在反映到位元組碼上的就是產生一張異常表,只有發生異常時才會被使用。由此得到出開始的結論。
這裡再對結論擴充:
try catch與未使用try catch程式碼區別在於,前者阻止Java對try塊的程式碼的一些優化,例如重排序。try catch裡面的程式碼是不會被編譯器優化重排的。對於上面兩個函式而言,只是異常表中try起點和終點位置不一樣。至於剛剛說到的指令重排的問題,由於for迴圈條件部分符合happens- before原則,因此兩者的for迴圈都不會發生重排。當然只是針對這裡而言,在實際程式設計中,還是提倡try程式碼塊的範圍儘量小,這樣才可以充分發揮Java對程式碼的優化能力。
測試驗證
既然通過位元組碼已經分析出來了,兩者效能沒有差異。那我們就來檢測一下吧,看看到底是不是如前面分析的那樣。
在正式開始測試時,首先我們要明白,一個正確的測試方法,就是保證我們的測試能產生不被其他因素所歪曲汙染的有效結果。那應該使用什麼方法來測試我們的程式碼呢?
不正確的測試
這裡首先說一下一種常見的錯誤的測量方法,測量一個方法的執行時間,最容易想到的應該是下面這種了:
long startTime = System.currentTimeMillis();
doReallyLongThing();
long endTime = System.currentTimeMillis();
System.out.println("That took " + (endTime - startTime) + " milliseconds");但是我會跟你說,這個方式十分的不準確,我這裡給大家展示一下我的使用上面的方式來進行測試的結果
package com.kevin.java.performancetTest;
/**
* Created by kevin on 16-7-10.
*/
public class ForTryAndTryFor {
public static void main(String[] args) {
forTry();
tryFor();
}
public static void tryFor() {
long startTime = System.currentTimeMillis();
int j = 3;
try {
for (int i = 0; i < 1000000; i++) {
Math.sin(j);
}
} catch (Exception e) {
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
System.out.println("tryFor " + (endTime - startTime) + " milliseconds");
}
public static void forTry() {
long startTime = System.currentTimeMillis();
int j = 3;
for (int i = 0; i < 1000000; i++) {
try {
Math.sin(j);
} catch (Exception e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("forTry " + (endTime - startTime) + " milliseconds");
}
}測試結果
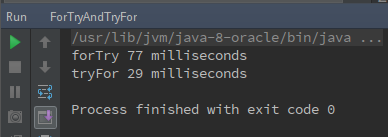
看到這個你是不是會認為tryFor比forTry快了呢?當然一般而言,不會這麼快就下定論,所以接著你就會繼續執行數次,然後可能還是會看見類似上面的結果。很有可能你就會確信forTry比tryFor快。但是這個測試的結果是不準確的,確切的說是無效的。
為什麼呢?如果你測試的次數足夠多(其實也不用很多,我這裡就運行了十幾次這樣),你就會發現問題。我再列出這十幾次測試中比較有代表性的測試結果的截圖。
圖1
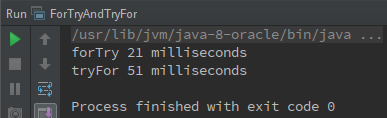
圖2
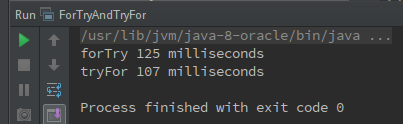
圖3
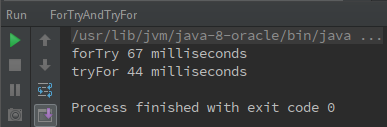
從上面結果看來,絕大多數時候,tryFor比forTry快。那是不是可以說tryFor比forTry快了呢?如果沒有前面分析,如果你只是測試了幾次,並且結果都類似的時候,你是不是會就因此下定論了呢?
上面問題就出現在這個絕大多數,當你執行的次數越多,就越發的體會到結果的撲朔迷離。
至少有下面兩點給人撲朔迷離的感覺:
- 每次的執行時間都相差很大。
同一個函式會出現,兩次執行結果可能相差好幾倍的情況。比如圖1中的forTry竟然比圖2的forTry快了近6倍。 - 偶爾forTry會比tryFor快(我上面的擷取的是比較有代表性的結果,實際執行的時候絕大多數情況顯示的是tryFor快)
那是什麼導致了結果如此的撲朔迷離?原因至少有下面這些
- System.currentTimeMillis()測量的只是逝去的時間,並沒有反映出cpu執行該函式真正消耗的時間。
這導致執行緒未被分配cpu資源時,等待cpu的時間也會被計算進去 JIT優化導致結果出現偏差。
像這種多次迴圈非常容易觸發JIT的優化機制,關於JIT,這裡簡短的介紹一下在Java程式語言和環境中,即時編譯器(JIT compiler,just-in-time compiler)是一個把Java的位元組碼(包括需要被解釋的指令的程式)轉換成可以直接傳送給處理器的指令的程式。當你寫好一個Java程式後,源語言的語句將由Java編譯器編譯成位元組碼,而不是編譯成與某個特定的處理器硬體平臺對應的指令程式碼(比如,Intel的Pentium微處理器或IBM的System/390處理器)。位元組碼是可以傳送給任何平臺並且能在那個平臺上執行的獨立於平臺的程式碼。
JIT 編譯器概述
Just-In-Time (JIT) 編譯器是 Java™ Runtime Environment 的一個元件,用於提高執行時的 Java
應用程式的效能。Java 程式由多個類組成,它包含可在許多不同計算機體系結構上由 JVM 解釋的與平臺無關的位元組碼。在執行時,JVM 裝入類檔案,確定每個單獨的位元組碼的語義,並執行相應的計算。解釋期間額外使用處理器和記憶體意味著 Java應用程式的執行速度要慢於本機應用程式。JIT 編譯器通過在執行時將位元組碼編譯為本機程式碼以幫助提高 Java 程式的效能。
JIT 編譯器在預設情況下為已啟用,並在呼叫 Java 方法時被啟用。JIT 編譯器將該方法的位元組碼編譯為本機機器碼,“即時”編譯該程式碼以便執行。在編譯方法時,JVM 直接呼叫該方法的已編譯程式碼,而不是對程式碼進行解釋。理論上,如果編譯不需要佔用處理器時間和記憶體,那麼編譯每個方法都可能使 Java程式速度接近於本機應用程式的速度。
JIT 編譯需要佔用處理器時間和記憶體。在 JVM首次啟動時,將呼叫數千種方法。即使程式最終實現了較高的峰值效能,編譯所有這些方法也會對啟動時間產生顯著影響。
實際上,第一次呼叫方法時不會對方法進行編譯。 對於每個方法,JVM 都會保留一個呼叫計數,每次呼叫方法時該計數都將遞增。JVM對方法進行解釋,直至其呼叫計數超過 JIT 編譯閾值。因此,在 JVM啟動後將立即編譯常用方法,而在較長時間之後(或者根本不編譯)不常使用的方法。JIT 編譯閾值幫助 JVM 快速啟動並且還可提高效能。 謹慎選擇閾值,以在啟動時與長期效能之間實現最佳平衡。
在編譯方法後,呼叫計數將重置為 0,並且對該方法的後續呼叫將繼續使其計數遞增。在方法的呼叫計數到達 JIT 重新編譯閾值時,JIT 編譯器將執行第二次編譯,與前一次編譯相比,其優化選擇更多。此過程將重複,直至到達最大優化級別。Java程式的最忙碌方法始終是最積極地進行優化,從而實現使用 JIT 編譯器的效能優勢最大化。JIT編譯器還可在執行時度量運作資料,並使用該資料來提高進一步重新編譯的質量。
可禁用 JIT 編譯器,在這種情況下,將解釋整個 Java 程式。除診斷或解決 JIT 編譯問題外,不推薦禁用 JIT 編譯器。
簡單來說,JIT會將某些符合條件(比如,頻繁的迴圈)的位元組碼被編譯成目標的機器指令直接執行,從而加快執行速度。可以通過配置
-XX:+PrintCompilation引數,在控制檯觀察JIT做了哪些優化。當JIT執行優化時,會在終端輸出相應的優化資訊。我們程式碼的JIT輸出的資訊,可以看到我們測試的兩個函式已經被JIT編譯優化了。
67 46 n 0 sun.misc.Unsafe::getObjectVolatile (native) 67 45 3 java.util.concurrent.ConcurrentHashMap::tabAt (21 bytes) 67 47 3 java.lang.AbstractStringBuilder::<init> (12 bytes) 68 49 3 java.lang.AbstractStringBuilder::expandCapacity (50 bytes) 68 48 3 java.lang.ref.SoftReference::get (29 bytes) 78 50 % ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::forTry @ 8 (73 bytes) 78 51 ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::forTry (73 bytes) 79 52 % ! 4 com.kevin.java.performancetTest.ForTryAndTryFor::forTry @ 8 (73 bytes) 79 50 % ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::forTry @ -2 (73 bytes) made not entrant 131 52 % ! 4 com.kevin.java.performancetTest.ForTryAndTryFor::forTry @ -2 (73 bytes) made not entrant forTry 63 milliseconds 141 53 % ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::tryFor @ 8 (71 bytes) 142 54 ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::tryFor (71 bytes) 142 55 % ! 4 com.kevin.java.performancetTest.ForTryAndTryFor::tryFor @ 8 (71 bytes) 143 53 % ! 3 com.kevin.java.performancetTest.ForTryAndTryFor::tryFor @ -2 (71 bytes) made not entrant 192 55 % ! 4 com.kevin.java.performancetTest.ForTryAndTryFor::tryFor @ -2 (71 bytes) made not entrant tryFor 61 milliseconds- 類載入時間也被統計進來了。
類首次被使用時,會觸發類載入,產生了時間消耗。
從上面分析的原因不難看出,為什麼絕大多數時候tryFor會比forTry快了。JIT編譯耗時和類載入時間會被統計到第一個執行的函式forTry裡面。這就直接導致了第一個執行的函式(forTry)要比第二個函式(tryFor)執行的時間要長。最為重要的使用System.currentTimeMillis()測量的是(等待cpu+真正被執行的時間),這就導致出現圖1完全與絕大多數測試結果完全相反的情況。
那有什麼可以讓我們穿過這層層迷霧,直抵真相呢?
穿透迷霧,直抵真相!
- 不要使用System.currentTimeMillis()亦或者使用System.nanoTime()
這裡說明一下,可能你會看到有些建議使用System.nanoTime()來測試,但是它跟System.currentTimeMillis()區別,僅僅在於時間的基準不同和精度不同,但都表示的是逝去的時間,所以對於測試執行時間上,並沒有什麼區別。因為都無法統計CPU真正執行時間。
要測試cpu真正執行時間,這裡推薦使用JProfiler效能測試工具,它可以測量出cpu真正的執行時間。具體安裝使用方法可以自行google百度。因為這不是本文最終使用的測試方法,所以就不做詳細介紹了。但是你使用它來測試上面的程式碼,至少可以排除等待CPU消耗的時間 - 對於後兩者,需要加入Warmup(預熱)階段。
預熱階段就是不斷執行你的測試程式碼,從而使得程式碼完成初始化工作(類載入),並足以觸發JIT編譯機制。一般來說,迴圈幾萬次就可以預熱完畢。
那是不是做到以上兩點就可以了直抵真相了?非常不幸,並沒有那麼簡單,JIT機制和JVM並沒有想象的這麼簡單,要做到以下這些點你才能得到比較真實的結果。下面摘錄至how-do-i-write-a-correct-micro-benchmark-in-java排名第一的答案
Rule 0: Read a reputable paper on JVMs and micro-benchmarking. A good one is Brian Goetz, 2005. Do not expect too much from
micro-benchmarks; they measure only a limited range of JVM performance
characteristics.Rule 1: Always include a warmup phase which runs your test kernel all the way through, enough to trigger all initializations and
compilations before timing phase(s). (Fewer iterations is OK on the
warmup phase. The rule of thumb is several tens of thousands of inner
loop iterations.)Rule 2: Always run with
-XX:+PrintCompilation,-verbose:gc, etc., so you can verify that the compiler and other parts of the JVM
are not doing unexpected work during your timing phase.Rule 2.1: Print messages at the beginning and end of timing and warmup phases, so you can verify that there is no output from Rule 2
during the timing phase.Rule 3: Be aware of the difference between -client and -server, and OSR and regular compilations. The
-XX:+PrintCompilationflag
reports OSR compilations with an at-sign to denote the non-initial
entry point, for example:Trouble$1::run @ 2 (41 bytes). Prefer
server to client, and regular to OSR, if you are after best
performance.Rule 4: Be aware of initialization effects. Do not print for the first time during your timing phase, since printing loads and
initializes classes. Do not load new classes outside of the warmup
phase (or final reporting phase), unless you are testing class loading
specifically (and in that case load only the test classes). Rule 2 is
your first line of defense against such effects.Rule 5: Be aware of deoptimization and recompilation effects. Do not take any code path for the first time in the timing phase, because
the compiler may junk and recompile the code, based on an earlier
optimistic assumption that the path was not going to be used at all.
Rule 2 is your first line of defense against such effects.Rule 6: Use appropriate tools to read the compiler’s mind, and expect to be surprised by the code it produces. Inspect the code
yourself before forming theories about what makes something faster or
slower.Rule 7: Reduce noise in your measurements. Run your benchmark on a quiet machine, and run it several times, discarding outliers. Use
-Xbatchto serialize the compiler with the application, and consider
setting-XX:CICompilerCount=1to prevent the compiler from running
in parallel with itself.Rule 8: Use a library for your benchmark as it is probably more efficient and was already debugged for this sole purpose. Such as
JMH, Caliper or Bill and Paul’s Excellent UCSD Benchmarks
for Java.
那就沒有簡單可靠的測試方法了嗎?如果你認真看完上面提到的點,你應該會注意到Rule 8,沒錯,我就是使用Rule8提到的JMH來。這裡摘錄一段網上的介紹
JMH是新的microbenchmark(微基準測試)框架(2013年首次釋出)。與其他眾多框架相比它的特色優勢在於,它是由Oracle實現JIT的相同人員開發的。結果可信度很高。
正確的測試
測試環境:
JVM版本:
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
系統:
Linux Mint 17.3 Rosa 64bit
配置:i7-4710hq+16g
工具:Intellij IDEA 2016+JMH的jar包+JMH intellij plugin外掛具體使用可以看JMH外掛Github專案地址,上面有介紹使用細節
測試程式碼:
package com.kevin.java.performancetTest;
import org.openjdk.jmh.annotations.Benchmark;
/**
* Created by kevin on 16-7-10.
*/
public class ForTryAndTryFor {
public static void main(String[] args) {
tryFor();
forTry();
}
@Benchmark
public static void tryFor() {
int j = 3;
try {
for (int i = 0; i < 1000; i++) {
Math.sin(j);
}
} catch (Exception e) {
e.printStackTrace();
}
}
@Benchmark
public static void forTry() {
int j = 3;
for (int i = 0; i < 1000; i++) {
try {
Math.sin(j);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}測試結果
JMH會做執行一段時間的WarmUp,之後才開始進行測試。這裡只是擷取結果部分,執行過程輸出就不放出來了
# Run complete. Total time: 00:02:41
Benchmark Mode Cnt Score Error Units
performancetTest.ForTryAndTryFor.forTry thrpt 40 26.122 ± 0.035 ops/ms
performancetTest.ForTryAndTryFor.tryFor thrpt 40 25.535 ± 0.087 ops/ms# Run complete. Total time: 00:02:41
Benchmark Mode Cnt Score Error Units
performancetTest.ForTryAndTryFor.forTry sample 514957 0.039 ± 0.001 ms/op
performancetTest.ForTryAndTryFor.tryFor sample 521559 0.038 ± 0.001 ms/op每個函式都測試了兩編,總時長都是2分41秒
主要關注Score和Error兩列,±表示偏差。
第一個結果的意思是,每毫秒呼叫了 26.122 ± 0.035次forTry函式,每毫秒呼叫了 25.535 ± 0.087次tryFor函式,第二個結果表示的是呼叫一次函式的時間。
從結果中,可以看到兩個函式效能並沒有差異,與之前的分析吻合。
最終總結
本文由Try catch與for迴圈的位置關係開始討論,通過分析得出了結論,並最終通過測試,驗證了分析的結論——兩者在沒有丟擲異常時,是沒有區別的。在分析的過程中,我們也瞭解到try catch的實質,就是跟方法關聯的異常表,在丟擲異常的時候,這個就決定了異常是否會被該方法處理。
最後回到標題討論的,try catch對效能的影響。try catch對效能還是有一定的影響,那就是try塊會阻止java的優化(例如重排序)。當然重排序是需要一定的條件觸發。一般而言,只要try塊範圍越小,對java的優化機制的影響是就越小。所以保證try塊範圍儘量只覆蓋丟擲異常的地方,就可以使得異常對java優化的機制的影響最小化。
還是那句話,先保證程式碼正確執行,然後在出現明顯的效能問題時,再去考慮優化。
參考連結
相關推薦
try catch 對效能影響
引言 之前一直沒有去研究try catch的內部機制,只是一直停留在了感覺上,正好這週五開會交流學習的時候,有人提出了相關的問題。藉著週末,正好研究一番。 討論的問題 當時討論的是這樣的問題: 比較下面兩種try catch寫法,哪一種效能更好。
mysql觸發器對效能影響
大佬們一直說不要用觸發器,觸發器對效能影響很多,但是一直似懂非懂,藉著最近有時間準備清理下公司庫裡的觸發器,研究下觸發器的機制跟對效能影響。想來定義:在MySQL中,觸發器可以在你執行INSERT、UPDATE或DELETE的時候,執行一些特定的操作。在建立觸發器時,可以指定
異常處理 try...catch...finally 執行順序, 以及對返回值得影響
異常處理 try...catch...finally 執行順序, 以及對返回值得影響 結論:1、不管有沒有出現異常,finally塊中程式碼都會執行;2、當try和catch中有return時,finally仍然會執行;3、finally是在return後面的表示式運算後執行的(此時並沒有返回運算後的值,而
C# 深度剖析try catch finally及其效能影響
關於try-catch-finally的使用本文不做探討,詳見try-catch參考。 本文想真正剖析的是在程式碼中使用try-catch-finally塊對於效能的影響。很多程式設計師認為:只要沒有異常丟擲,try就沒有額外的效能開銷。為此,我們先來
Python異常(try...except)對程式碼執行效能的影響
前言 Python的異常處理能力非常強大,但是用不好也會帶來負面的影響。我平時寫程式的過程中也喜歡使用異常,雖然採取防禦性的方式編碼會更好,但是交給異常處理會起到偷懶作用。偶爾會想想異常處理會對效能造成多大的影響,於是今天就試著測試了一下。 Pyth
【百度】大型網站的HTTPS實踐(三)——HTTPS對效能的影響
HTTPS在保護使用者隱私,防止流量劫持方面發揮著非常關鍵的作用,但與此同時,HTTPS也會降低使用者訪問速度,增加網站伺服器的計算資源消耗。本文主要介紹HTTPS對效能的影響。 HTTPS對訪問速度的影響 在介紹速度優化策略之前,先來看下HTTPS對速度有什麼影響。影響主要來自兩方面:協議互動所增加的網
try catch影響Spring事務嗎?
對於這個問題有兩種情況: 1.catch只打印異常,不丟擲異常 try { 資料庫做新增訂單表; int a=5/0; 資料庫減少庫存; }catch (Exception e){ e.
mysql優化之sql執行流程及表結構(schema)對效能的影響
part 1 sql執行流程(如下圖所示) 1、客戶端傳送一條查詢到伺服器。 2、伺服器通過許可權檢查後,先檢查查詢快取,命中則直接返回結果。否則進入3。 3、伺服器進行sql解析,預處理,再由優化器根據該sql涉及到的資料表的資訊計算,生成執行計劃。 4.、MySQL根據優化器生成的執行計劃,呼叫儲
cpu 分支預測對效能的影響
cpu 分支預測對效能的影響 現在的 cpu 一般都支援分支預測功能。維基百科中有以下描述: 在計算機體系結構中,分支預測器(英語:Branch predictor)是一種數位電路,在分支指令執行結束之前猜測哪一路分支將會被執行,以提高處理器的指令流水線的效能。使用分支預
訊息中介軟體學習總結(12)——Kafka與RocketMQ的多Topic對效能穩定性的影響比較分析
引言 上期我們對比了RocketMQ和Kafka在多Topic場景下,收發訊息的對比測試,RocketMQ表現穩定,而Kafka的TPS在64個Topic時可以保持13萬,到了128個Topic就跌至0.85萬,導致無法完成測試。我們不禁要問: 為什麼看不到Kafka效能
資料庫新增索引對效能的影響以及使用場景
1.新增索引後查詢速度會變快 mysql中索引是儲存引擎層面用於快速查詢找到記錄的一種資料結構,索引對效能的影響非常重要,特別是表中資料量很大的時候,正確的索引會極大的提高查詢效率。簡單理解索引,就相當於一本磚頭厚書的目錄部分,通過目錄可以快速查詢到想要找的內容具體所在
測試go多協程併發寫入記憶體和磁碟對效能的影響
最近希望能把一些過程,由傳統的順序執行改變成併發執行,看這樣的優化是否能帶來效能的提高。於是寫了幾個test來測試帶來的影響。 測試的環境為mac pro,2.3 GHz Intel Core i5(雙核),16GB記憶體。 (1)先測試併發寫入記憶體是否能夠得到效能的提高
MySQL中採用型別varchar(20)和varchar(255)對效能上的影響
1.MySQL建立索引時如果沒有限制索引的大小,索引長度會預設採用的該欄位的長度,也就是說varchar(20)和varchar(255)對應的索引長度分別為20*3(utf-8)(+2+1),255*3(utf-8)(+2+1),其中"+2"用來儲存長度資訊,“+1”用來
ceph bluestore bcache 磁碟對齊對於效能影響
1. 磁碟劃分: # for sd in a b c d e f g h i j k l m n o ; do fdisk -l /dev/sd${sd} 2>/dev/null| grep "^ 1"; done 1 2048 1953523711 931
sequence cache設定 對RAC效能影響
此文章為翻譯轉譯文章: 環境 : 11g 64位 2節點的RAC 開發同事每次上程式碼的時候,建立sequence都是指定“no cache”。長期下來效能很慢。下面分析下: 如果指定CACHE值,Oracle就可以預先在記憶體裡面放置一些Sequence
ABAP 對RESB表取數效能影響
系統環境: ECC6 EHP7 IBM-P740 192G RAM IBM-P7+ 32CORE ORACLE 11.2.0.3 症狀: ZPPR0001_NEW生產訂單批量報工程式 ,運行於每天凌晨2:30, 執行速度緩慢。 2015-09-14
ArrayList初始容量對效能的影響
package testList; import java.util.ArrayList; public class TestLArrayList { public static void main(String[] args) { System.out.prin
關於對Java中異常處理的try catch和throw的理解(淺顯理解)
一.try catch方法 A.什麼try catch 方法 try catch是異常處理中一種方法,檢測並捕捉異常然後進行處理 try是檢測異常,catch是捕捉異常 B try catch的三種格式 格式1 try{ 語句體; }catch{
java中try/catch效能和原理
部分內容轉載自http://blog.csdn.net/tao_zi7890/article/details/17584813 記得在做企業雲專案的時候,我接了兩個有意思的任務,一個是為幾個執行緒加很多的try/catch程式碼。catch的異常有好幾層,範圍最小的,或者說
Kafka vs RocketMQ——多Topic對效能穩定性的影響
引言上期我們對比了RocketMQ和Kafka在多Topic場景下,收發訊息的對比測試,RocketMQ表現穩定,而Kafka的TPS在64個Topic時可以保持13萬,到了128個Topic就跌至0.85萬,導致無法完成測試。我們不禁要問:為什麼看不到Kafka效能暴跌的趨