
numpy中方差var、協方差cov求法
在PCA中涉及到了方差var和協方差cov,下面詳細瞭解這兩個函式的用法。numpy中var和cov函式求法和MATLAB中var和cov函式求法類似。
首先均值,樣本方差,樣本協方差公式分別為
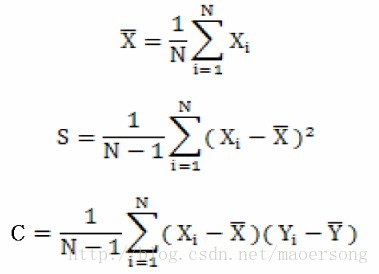
樣本的方差,而是整個空間的方差。
下面就介紹MATLAB中var和cov函式的用法
函式名稱:cov
函式功能: 求協方差矩陣
函式用法: cov(X) % cov(X,0) = cov(X)
cov(X,Y) % X,Y必須是各維數都相同的矩陣
cov(X,1) % 除以N而不是N-1
詳細描述:
......................................................................
if X is a vector向量,cov(X)輸出的是這個向量的方差
例:
>> A = [4 1 3];
>> AA = cov(A)
AA =
2.3333
>> a = mean(A)
a =
2.6667
>> AAA = 1/3*((4-a)^2+(1-a)^2+(3-a)^2)
AAA =
1.5556
>> AAAA= 1/2*((4-a)^2+(1-a)^2+(3-a)^2) %同樣,這個方差不是真正意義的方差,而是對樣本統計方差的一個無偏估計值
AAAA =
2.3333
..............................................................................
對於矩陣來說,matlab把每行看做一個觀察值,把每列當做一個變數,也就是說對於一個4*3的矩陣求協方差矩陣,matlab會認為存在三個變數,即會求出一個3*3的協方差矩陣。
其中,對角線元素為對應變數的方差無偏估計值,其他位置為對應變數間的 協方差無偏估計值(即除的是N-1)
.......................................................................
例1:
>> X = [1 5 6; 4 3 9 ; 4 2 9; 4 7 2]
X =
1 5 6
4 3 9
4 2 9
4 7 2
>> Y = cov(X)
Y =
2.2500 -0.7500 0.5000
-0.7500 4.9167 -7.1667
0.5000 -7.1667 11.0000
為探究過程,以Y(1,1)和Y(1,2)為例進行驗證
>> x=X(:,1);
>> sum((x-3.25).^2)/3
ans =
2.2500
>> y = X (:,2);
>> aa = x'*y/3
aa =
-0.7500
......................................................
對於cov(X,Y)
X、Y必須是各維數都相等的矩陣,其功能是把X中所有元素看做一個變數的樣本,Y中所有元素看做另外一個變數的樣本,把矩陣中每個對應位置看做一個聯合觀察值
函式實現的是求出兩個變數的協方差矩陣
例2:
>> X
X =
1 5 6
4 3 9
4 2 9
4 7 2
>> Y = [1 6 7; 7 5 9 ; 1 6 4 ; 2 9 2]
Y =
1 6 7
7 5 9
1 6 4
2 9 2
>> cov(X,Y)
ans =
6.9697 4.4242
4.4242 8.4470
現在用(1,1)和(1,2)位置驗證
>> sum(sum((X-mean(mean(X))).^2))/11 %把X中每個元素都看做一個變數的樣本,求其方差的無偏估計值
ans =
6.9697
>> sum(sum((X-mean(mean(X))).*(Y-mean(mean(Y)))))/11 %把X、Y矩陣對應位置元素看做一個聯合樣本,根據公式E[(X-EX)*(Y-EY)]求協方差
ans =
4.4242
.....................................................................................
cov(X,1) 和 cov(X,Y,1) 與之前的求解過程一致,不同的是,其求出的是協方差,而不是樣本的協方差無偏估計值,即其除以的是N 而不是N-1
例3:
>> cov(X,1)
ans =
1.6875 -0.5625 0.3750
-0.5625 3.6875 -5.3750
0.3750 -5.3750 8.2500
>> x=X(:,1);
sum((x-3.25).^2)/4 %不同之處
ans =
1.6875
>> y = X (:,2);
>> y = y - 4.25;
>> aa = x'*y/4 %不同之處
aa =
-0.5625
例4:
X =
1 5 6
4 3 9
4 2 9
4 7 2
>> Y = [1 6 7; 7 5 9 ; 1 6 4 ; 2 9 2]
Y =
1 6 7
7 5 9
1 6 4
2 9 2
>> cov(X,Y)
ans =
6.9697 4.4242
4.4242 8.4470
>> a =cov(X,Y,1)
a =
6.3889 4.0556
4.0556 7.7431
>> a.*12/11 %看出來了吧
ans =
6.9697 4.4242
4.4242 8.4470
相關推薦
numpy中方差var、協方差cov求法
在PCA中涉及到了方差var和協方差cov,下面詳細瞭解這兩個函式的用法。numpy中var和cov函式求法和MATLAB中var和cov函式求法類似。 首先均值,樣本方差,樣本協方差公式分別為
numpy中的方差、協方差、相關系數
degree log mes python axis 維數 關於 數據 如果 一、np.var 數學上學過方差: $$D(X)=\sum_{i\in [0,n)} ({x-\bar{x}})^2 $$ np.var實際上是均方差。 函數原型:numpy.var(a, axi
標準差、方差、協方差的簡單說明
cli -1016 -i 分享 技術 變量 one 舉例 blog 在一個樣本中,樣本的無偏估計的均值、標準差和方差如下: 對於單個變量,它的協方差可以表示為: 其實它即是方差,所以呢,當只有一個變量時,方差是協方差的一種特殊情況; 舉例:有一個變量 X的樣
均值、方差、協方差等定義與基本運算
class sigma 自變量 layout div htm 統計 因此 計算 一、均值 定義: 設P(x)是一個離散概率分布函數自變量的取值範圍是。那麽其均值被定義為:
均方誤差、平方差、方差、均方差、協方差(轉)
相差 均方差 nbsp 無法 bsp 技術 方法 簡便 但是 一,均方誤差 作為機器學習中常常用於損失函數的方法,均方誤差頻繁的出現在機器學習的各種算法中,但是由於是舶來品,又和其他的幾個概念特別像,所以常常在跟他人描述的時候說成其他方法的名字。 均方誤差的數學表達為:
協方差、協方差矩陣的數學概念及演算法計算
在講解協方差之前,我們先一起回憶一下樣本的均值、方差、標準差的定義。 方差,協方差和協方差矩陣 1、概念 方差(Variance)是度量一組資料的分散程度。方差是各個樣本與樣本均值的差的平方和的均值: 協方差(Covariance)是度量兩個變數的變動的同步程度
期望、方差、協方差、標準差
期望, 方差, 協方差,標準差 期望 概率論中描述一個隨機事件中的隨機變數的平均值的大小可以用數學期望這個概念,數學期望的定義是實驗中可能的結果的概率乘以其結果的總和。 定義 設P(x) 是一個離散概率分佈,自變數的取值範圍為{x1,x2,...,xn }。其期望被定義為:
方差、協方差
方差是在概率論和統計方差衡量隨機變數或一組資料時離散程度的度量。概率論中方差用來度量隨機變數和其數學期望(即均值)之間的偏離程度。統計中的方差(樣本方差)是每個樣本值與全體樣本值的平均數之差的平方值的平均數。在許多實際問題中,研究方差即偏離程度有著重要意義。 方差是
統計學習方法——均值、方差、標準差及協方差、協方差矩陣
一、統計學基本概念:均值、方差、標準差 統計學裡最基本的概念就是樣本的均值、方差、標準差。首先,我們給定一個含有n個樣本的集合,下面給出這些概念的公式描述: 均值: 標準差: 方差: 均值描述的是樣本集合的中間點,它告訴我們的資訊是有限的。 標準差給我們描述的是樣
機器學習之數學基礎——期望、方差、協方差、相關係數、矩、協方差矩陣
期望 定義 離散型 E(X)=∑i∞xkpk 連續型 E(X)=∫∞−∞xf(x)dx 性質 E[aX+bY]=aE[X]+bE[Y] 方差 定義 D(X)=Var(X)=E{[X−E(X)]2}=E
標準差、方差、協方差的區別
分享圖片 期望 方差 線性 ria info bubuko 變量 能說 公式: 標準差: 方差: 協方差: 意義: 方差(Variance):用來度量隨機變量和其數學期望(即均值)之間的偏離程度。 標準差:方差開根號。標準差和方差一般是用來描述一維數據的。 協方差:衡量兩個
概率統計:數學期望、方差、協方差、相關係數、矩
摘要:最近在學習機器學習/資料探勘的演算法,在看一些paper的時候經常會遇到以前學過的數學公式或者名詞,又是總是想不起來,所以在此記錄下自己的數學複習過程,方便後面查閱。 1:數學期望 數學期望是隨機變數的重要特徵之一,隨機變數X的數學期望記為E(X),E(X)是X的算術平均的近似值,數學期望表示了X的
概率論基礎知識整理:概率分佈、邊緣/條件概率、期望、協方差
一、概率分佈 離散型變數的概率分佈可以用 概率質量函式(probability mass function, PMF) 來描述。我們通常用大寫字母 P 來表示概率質量函式。通常每一個隨機變數都會有 一個不同的概率質量函式,並且讀者必須根據隨機變數來推斷所使用的 PMF,而不 是根據函式的名稱來推
分類-3-生成學習-2-高斯判別分析、協方差
多元高斯分佈 多變數高斯分佈描述的是 n維隨機變數的分佈情況,這裡的μ變成了向量, σ也變成了矩陣Σ。寫作N(μ,Σ)。其中Σ(協方差矩陣)是一個半正定的矩陣,μ是高斯分佈的均值,下面給出它的概率密度函式: begin-補充-協方差和協方差矩
oracle資料庫之統計分析(方差、標準差、協方差)
SELECT deptno, ename, --st_name || ' ' || last_name employee_name, hiredate, sal, STDDEV (sal) OVER (PARTIT
標準差、方差、協方差三者的表示意義
三者都是統計學中,對於樣本的集合描述。定義公式標準差:方差:協方差:協方差相關係數:數學實際含義方差(Variance):用來度量隨機變數和其數學期望(即均值)之間的偏離程度。標準差:方差開根號。協方差:衡量兩個變數之間的變化方向關係。方差、標準差、和協方差之間的聯絡與區別:
方差與樣本方差、協方差與樣本協方差
0. 獨立變數乘積的方差 獨立變數積的方差與各自期望方差的關係: Var(XY)=[E(X)]2Var(Y)+[E(Y)]2Var(X)+Var(X)Var(Y)=[E(X)]2Var(Y)+[E
期望、方差、標準差、偏差、協方差和協方差矩陣
期望 一件事情有n種結果,每一種結果值為xixi,發生的概率記為pipi,那麼該事件發生的期望為: E=∑i=1nxipiE=∑i=1nxipi 方差 S2=1n∑i=1n(Xi−μ)2S2=1n∑i=1n(Xi−μ)2 其中:μμ為全體平均數
方差、協方差、期望、相關係數等概念集合
首先說明一下,本文是本人在複習方差等相關知識的過程中,通過網路上的相關講解,進行個人總結後得到的,並非個人原創,在此釋出只是為了作為一個學習記錄與大家分享。 1.期望 試驗中可能出現的值及其概率的乘積,即是數學期望 1)離散型 離散型隨機變數的一切可能的取值
Mathematics Base - 期望、方差、協方差、相關系數總結
scu 大小 深度 相關性 兩個 定義 int spa 相關 參考:《深度學習500問》 期望 ?在概率論和統計學中,數學期望(或均值,亦簡稱期望)是試驗中每次可能結果的概率乘以其結果的總和。它反映隨機變量平均取值的大小。 線性運算: \(E(ax+by+c) = aE(