
New – Amazon EC2 Instances with Up to 8 NVIDIA Tesla V100 GPUs (P3)
Driven by customer demand and made possible by on-going advances in the state-of-the-art, we’ve come a long way since the original m1.small instance that we launched in 2006, with instances that emphasize compute power, burstable performance, memory size, local storage, and accelerated computing.
The New P3
Today we are making the next generation of GPU-powered EC2 instances available in four AWS regions. Powered by up to eight NVIDIA Tesla V100 GPUs, the P3 instances are designed to handle compute-intensive machine learning, deep learning, computational fluid dynamics, computational finance, seismic analysis, molecular modeling, and genomics workloads.
P3 instances use customized Intel Xeon E5-2686v4 processors running at up to 2.7 GHz. They are available in three sizes (all VPC-only and EBS-only):
| Model | NVIDIA Tesla V100 GPUs | GPU Memory | NVIDIA NVLink | vCPUs |
Main Memory | Network Bandwidth | EBS Bandwidth |
| p3.2xlarge | 1 | 16 GiB | n/a | 8 | 61 GiB | Up to 10 Gbps | 1.5 Gbps |
| p3.8xlarge | 4 | 64 GiB | 200 GBps | 32 | 244 GiB | 10 Gbps | 7 Gbps |
| p3.16xlarge | 8 | 128 GiB | 300 GBps | 64 | 488 GiB | 25 Gbps | 14 Gbps |
Each of the NVIDIA GPUs is packed with 5,120 CUDA cores and another 640 Tensor cores and can deliver up to 125 TFLOPS of mixed-precision floating point, 15.7 TFLOPS of single-precision floating point, and 7.8 TFLOPS of double-precision floating point. On the two larger sizes, the GPUs are connected together via NVIDIA NVLink 2.0 running at a total data rate of up to 300 GBps. This allows the GPUs to exchange intermediate results and other data at high speed, without having to move it through the CPU or the PCI-Express fabric.
What’s a Tensor Core?
I had not heard the term Tensor core before starting to write this post. According to this very helpful post on the NVIDIA Blog, Tensor cores are designed to speed up the training and inference of large, deep neural networks. Each core is able to quickly and efficiently multiply a pair of 4×4 half-precision (also known as FP16) matrices together, add the resulting 4×4 matrix to another half or single-precision (FP32) matrix, and store the resulting 4×4 matrix in either half or single-precision form. Here’s a diagram from NVIDIA’s blog post:
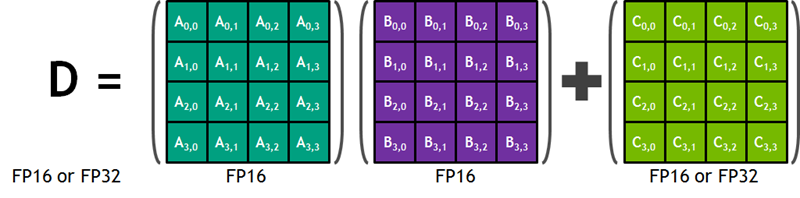
This operation is in the innermost loop of the training process for a deep neural network, and is an excellent example of how today’s NVIDIA GPU hardware is purpose-built to address a very specific market need. By the way, the mixed-precision qualifier on the Tensor core performance means that it is flexible enough to work with with a combination of 16-bit and 32-bit floating point values.
Performance in Perspective
I always like to put raw performance numbers into a real-world perspective so that they are easier to relate to and (hopefully) more meaningful. This turned out to be surprisingly difficult, given that the eight NVIDIA Tesla V100 GPUs on a single p3.16xlarge can do 125 trillion single-precision floating point multiplications per second.
Let’s go back to the dawn of the microprocessor era, and consider the Intel 8080A chip that powered the MITS Altair that I bought in the summer of 1977. With a 2 MHz clock, it was able to do about 832 multiplications per second (I used this data and corrected it for the faster clock speed). The p3.16xlarge is roughly 150 billion times faster. However, just 1.2 billion seconds have gone by since that summer. In other words, I can do 100x more calculations today in one second than my Altair could have done in the last 40 years!
What about the innovative 8087 math coprocessor that was an optional accessory for the IBM PC that was announced in the summer of 1981? With a 5 MHz clock and purpose-built hardware, it was able to do about 52,632 multiplications per second. 1.14 billion seconds have elapsed since then, p3.16xlarge is 2.37 billion times faster, so the poor little PC would be barely halfway through a calculation that would run for 1 second today.
Ok, how about a Cray-1? First delivered in 1976, this supercomputer was able to perform vector operations at 160 MFLOPS, making the p3.x16xlarge 781,000 times faster. It could have iterated on some interesting problem 1500 times over the years since it was introduced.
Comparisons between the P3 and today’s scale-out supercomputers are harder to make, given that you can think of the P3 as a step-and-repeat component of a supercomputer that you can launch on as as-needed basis.
Run One Today
In order to take full advantage of the NVIDIA Tesla V100 GPUs and the Tensor cores, you will need to use CUDA 9 and cuDNN7. These drivers and libraries have already been added to the newest versions of the Windows AMIs and will be included in an updated Amazon Linux AMI that is scheduled for release on November 7th. New packages are already available in our repos if you want to to install them on your existing Amazon Linux AMI.
The newest AWS Deep Learning AMIs come preinstalled with the latest releases of Apache MxNet, Caffe2, and Tensorflow (each with support for the NVIDIA Tesla V100 GPUs), and will be updated to support P3 instances with other machine learning frameworks such as Microsoft Cognitive Toolkit and PyTorch as soon as these frameworks release support for the NVIDIA Tesla V100 GPUs. You can also use the NVIDIA Volta Deep Learning AMI for NGC.
P3 instances are available in the US East (N. Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo) Regions in On-Demand, Spot, Reserved Instance, and Dedicated Host form.
— Jeff;
相關推薦
New – Amazon EC2 Instances with Up to 8 NVIDIA Tesla V100 GPUs (P3)
Driven by customer demand and made possible by on-going advances in the state-of-the-art, we’ve come a long way since the original m1.small instan
Stop and Start Amazon EC2 Instances with Data Pipeline
You can use AWS Data Pipeline to programmatically start and stop your EC2 instances at scheduled instances. Data Pipeline uses AWS technologies
Facing Load Balancer to EC2 Instances with Private IP Addresses
You must create public subnets in the same Availability Zones as the private subnets that are used by your private instances. Then associate th
the rs gold with up to $18 Vouchers to Vic Hati, S
rate mes europe escape layer graphic iot led oss Most Australians are not homophobic; consider the number runescape gold of homosexuals e
Amazon and SiriusXM team up to offer free service and Echo Dots
Amazon and SiriumXM have partnered up to bring together streaming radio and the Amazon Echo. Echo owners can enjoy a three-month trial of SiriusXM for free
I need more Amazon EC2 instances, but I've reached my limit
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So
New Amazon EC2 Spot pricing model: Simplified purchasing without bidding and fewer interruptions
Contributed by Deepthi Chelupati and Roshni Pary Amazon EC2 Spot Instances offer spare compute capacity in the AWS Cloud at steep discount
New P2 Instance Type for Amazon EC2 – Up to 16 GPUs
I like to watch long-term technology and business trends and watch as they shape the products and services that I get to use and to write about. A
Amazon brings predictive scaling to EC2 instances
Amazon Web Services this week is improving its Auto Scaling tool with machine learning, giving it predictive capabilities. The new predictive scaling featu
I want to migrate instances between my local virtualization environment and Amazon EC2
Amazon Web Services is Hiring. Amazon Web Services (AWS) is a dynamic, growing business unit within Amazon.com. We are currently hiring So
How to Break a Monolith Application into Microservices with Amazon Elastic Container Service, Docker, and Amazon EC2
Traditional monolithic architectures are hard to scale. As an application's code base grows, it becomes complex to update and maintain.
No new migrations found. Your system is up-to-date.處理
span system 記錄 new blog 相關操作 處理 style date 顯然是migrations表中存儲的相關操作記錄了,刪除就好了!!! No new migrations found. Your system is up-to-date.處理
Up-to-date cache with EclipseLink and Oracle
property included conflict rec main enable previous party toc Up-to-date cache with EclipseLink and Oracle One of the most useful fe
Project configuration is not up-to-date with pom.xml. Run Maven->Update Project or use Quick Fix
完整錯誤資訊: Description Resource Path Location Type Project configuration is not up-to-date with pom.xml. Run Maven->Update Project or use Quick Fix.
Project configuration is not up-to-date with pom.xml. Run Maven->Update Project or use Quick Fix
原 Project configuration is not up-to-date with pom.xml. Run Maven->Update Project or use Quick Fix
Version Control System: Get up to speed with GIT
Version Control System: Get up to speed with GITGit WorkflowWhat is Git?Git is an open source distributed version control system used primarily for Source
Royce teams up with Intel to build autonomous ships | AITopics
Rolls-Royce revealed its plans to deploy autonomous ships back in 2016, outlining its strategy and a general overview of how the vessels would work. Now, t
Ask HN: How do you keep up to date with developments in quantum computing?
It's a topic that I've recently become more interested in and am trying to stay in the loop with recent updates and news in the field. Would love to hear w