
ElasticSearch原始碼解析(五):排序(評分公式)
轉載自:http://blog.csdn.net/molong1208/article/details/50623948
一、目的
一個搜尋引擎使用的時候必定需要排序這個模組,一般情況下在不選擇按照某一欄位排序的情況下,都是按照打分的高低進行一個預設排序的,所以如果正式使用的話,必須對預設排序的打分策略有一個詳細的瞭解才可以,否則被問起來為什麼這個在前面,那個在後面不好辦,因此對Elasticsearch的打分策略詳細的看了下,雖然說還不是瞭解的很全部,但是大部分都看的差不多了,結合理論以及搜尋的結果,做一個簡單的介紹
二、Elasticsearch的打分公式
Elasticsearch的預設打分公式是lucene的打分公式,主要分為兩部分的計算,一部分是計算query部分的得分,另一部分是計算field部分的得分,下面給出ES官網給出的打分公式:
- score(q,d) =
- queryNorm(q)
- · coord(q,d)
- · ∑ (
- tf(t in d)
- · idf(t)²
- · t.getBoost()
- · norm(t,d)
- ) (t in q)
queryNorm(q):
對查詢進行一個歸一化,不影響排序,因為對於同一個查詢這個值是相同的,但是對term於ES來說,必須在分片是1的時候才不影響排序,否則的話,還是會有一些細小的區別,有幾個分片就會有幾個不同的queryNorm值
queryNorm(q)=1 / √sumOfSquaredWeights
上述公式是ES官網的公式,這是在預設query boost為1,並且在預設term boost為1 的情況下的打分,其中
sumOfSquaredWeights =idf(t1)*idf(t1)+idf(t2)*idf(t2)+...+idf(tn)*idf(tn)
其中n為在query裡面切成term的個數,但是上面全部是在預設為1的情況下的計算,實際上的計算公式如下所示:
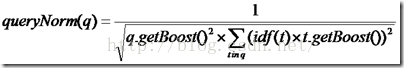
coord(q,d):
coord(q,d)是一個協調因子它的值如下:
-
coord(q,d)=overlap/maxoverlap
tf(t in d):
即term t在文件中出現的個數,它的計算公式官網給出的是:
- tf(t in d) = √frequency
idf(t):
這個的意思是出現的逆詞頻數,即召回的文件在總文件中出現過多少次,這個的計算在ES中與lucene中有些區別,只有在分片數為1的情況下,與lucene的計算是一致的,如果不唯一,那麼每一個分片都有一個不同的idf的值,它的計算方式如下所示:
- idf(t) = 1 + log ( numDocs / (docFreq + 1))
t.getboost():
對於每一個term的權值,沒仔細研究這個項,個人理解的是,如果對一個field設定boost,那麼如果在這個boost召回的話,每一個term的boost都是該field的boost
norm(t,d):
對於field的標準化因子,在官方給的解釋是field越短,如果召回的話權重越大,例如搜尋無線通訊,一個是很長的內容,但都是包含這幾個字,但是並不是我們想要的,另外一個內容很短,但是完整包含了無線通訊,我們不能因為後面的只出現了一次就認為權重是低的,相反,權重應當是更高的,其計算公式如下所示:
其中d.getboost表明如果該文件權重越大那麼久越重要


f.getboost表明該field的權值越大,越重要
lengthnorm表示該field越長,越不重要,越短,越重要,在官方文件給出的公式中,預設boost全部為1,在此給出官方文件的打分公式:
- norm(d) = 1 / √numTerms
三、實際的打分explain
在實際的時候,例如搜尋“無線通訊”,如下圖所示,因為一些私人原因,將一些欄位打碼,查詢的時候設定explain為true,如下圖所示:

因為使用的是預設的分詞器,所以最後的結果是將“無線通訊”分成了四個字,並且認為是四個term來進行計算,最後將計算的結果進行相加得到最後的得分0.7605926,這個分數是“無”的得分+“線”的得分+“通”的得分+“信”的得分,四個term的得分如下圖所示:




最後的得分是0.7605926=0.118954286+0.1808154+0.14515185+0.31567,與上述符合,因為四個詞都出現了所以在這裡面的coord=1,總分數的計算知道後,我們單看每一部分的得分的計算,以“無”為例進行介紹:

其中每一個term內部分為兩部分的分數,一部分是queryweight,一部分是fieldweight,其中總分數=queryweight*fieldweight
例如此處queryweight=0.51195854,fieldWeight=0.2323514,所以總的分數就是0.118954286
queryweigth計算:
對於queryweight部分的計算分為兩個部分idf和querynorm,其中idf的值是2.8618271,這個值是如何計算的呢
idf=1+ln(1995/(309+1))=2.8618271,說明在分片四里面共有1995個文件,召回了包含“無”的309個文件,因此為這個值
querynorm部分的計算:根據上面“無”“線”“通”“信”四個的分數計算,可以看到,idf的值分別為
無:2.8618271
線:3.1053379
通:2.235371
信:2.901306
所以按照計算公式
- querynorm=1 / √2.8618271*2.8618271+3.1053379*3.1053379+2.235371*2.235371+2.901306*2.901306=0.1788922
所以queryweight部分的值是0.1788922*2.8618271=0.51195854
再次總結下此處的公式:queryweight=idf*queryNorm(d)
fieldweight部分計算:
idf的計算上邊已經算過,在此不詳細敘述
tf的值是在此處出現3次,所以為√3=1.7320508
fieldnorm的值不知道如何計算,按照公式計算不出來explain的值,網上資料說是編解碼導致的,哪位朋友知道如何計算麻煩回覆下,多謝
總結下fieldweight部分的計算公式:fieldweight=idf*tf*fieldnorm=1.7320508*2.8618271*0.046875=0.2323514
所以總體的計算就是
- score=queryweight*fieldweight=idf*queryNorm(d)*idf*tf*fieldnorm=coord*queryNorm(d)*tf*idf^2*fieldnormview pl
相關推薦
ElasticSearch原始碼解析(五):排序(評分公式)
轉載自:http://blog.csdn.net/molong1208/article/details/50623948 一、目的 一個搜尋引擎使用的時候必定需要排序這個模組,一般情況下在不選擇按照某一欄位排序的情況下,都是按照打分的高低進行一個預設排序的,所以如
ElasticSearch原始碼解析(三):索引建立
我們先來看看索引建立的事例程式碼: Directory directory = FSDirectory.getDirectory("/tmp/testindex"); // Use standard analyzer Analyzer analyzer = new
JDK原始碼解讀(第五彈:Integer之toString方法)
上一篇只講了Integer的幾個屬性,這一次我們來看一下toString方法。 toString總共有3個過載,先來看兩個引數的toStirng方法: public static String toString(int i, int radix) {
ElasticSearch原始碼解析(一):轉一篇介紹中文分詞的文章
轉自:http://www.cnblogs.com/flish/archive/2011/08/08/2131031.html 基於CRF(Conditional Random Field)分詞演算法 論文連結:http://nlp.stanford.edu/pubs/
IntelliJ IDEA(五) :Settings(中)
dia 可見 .cn 哪些 -c cto 自己 關閉 ext 上篇介紹了Settings中的Appearance & Behavior和Keymap,這篇繼續,將介紹Editor,Plugins,Version Control。 一、Editor(編輯) 便捷界
ELK系列(一):安裝(elasticsearch + logstash + kibana)
minimum 5.6 解壓 通過 stdout you targe 記錄 pat 因為公司使用ELK的緣故,這兩天嘗試在阿裏雲上安裝了下ELK,這裏做個筆記,有興趣的同學可以看下。 先大致介紹下ELK,ELK是三個組件的縮寫,分別是elasticsearch、logsta
javaweb學習筆記(十五):JDBC(1)
目錄 1.概念 2 JDBC介面的核心API 例1:jdbc連線資料庫 例2:Statement物件演示 例3:PreparedStatement物件演示 例4:CallableStatement物件演示 1.概念 SUN公司為了簡化、統一對資料庫
《生命》第五集:Birds (鳥類)
看了前四集之後意猶未盡,今天終於有時間來看第五集了。 本集講的是鳥類,一個在恐龍開始繁榮的時代才開始有的物種。 鳥類和其他動物最不同的地方,就是羽毛,能隔熱,保暖,最重要的是:能幫助他們飛行。 在祕魯的安第斯山脈,有一種鳳尾蜂鳥,長著非常漂亮的兩根長長的尾巴,這是
【linux】Valgrind工具集詳解(十五):Callgrind(效能分析圖)
一、概述 1、Callgrind Callgrind用於記錄程式中函式之間的呼叫歷史資訊,對程式效能分析。預設情況下,收集的資料包括執行的指令數,它們與原始碼行的關係,函式之間的呼叫者、被呼叫者關係以及此類呼叫的數量。可選項是,對快取記憶體模擬和分支預測(類似於Cachegrin
華北五省機器人武術擂臺賽(無差別)(第二篇:從無到有的機械設計)
華北五省機器人武術擂臺賽(無差別)(第二篇:從無到有的機械設計) 1. 方案設計 2. 前期材料選型(建議) 3. 加工手段(建議參賽隊自備的裝置) 4. 機械設計 5. 結束語 1. 方案設計 這裡借用東北大學ROBO
第五章:JavaScript(第一話)
文章目錄 第一節:JavaScript簡介 ==關於JavaScript== ==JavaScript的作用== ==JavaScript的組成== ==JS的編寫位置==
讀OkHttp3原始碼(二):CertificatePinner(鎖定證書)
okhttp3 public final class CertificatePinner extends Object 類介紹: 該類用於約束哪些證書是可信的。 鎖定證書可以防止對證書頒發機構相關的攻擊。 它還阻止通過使用者已知或未知的中間證書頒發機構建立的連線。 這個類
再談資料結構(四):排序與查詢
1 - 引言 雖然C++中的STL庫中提供了許多排序和查詢的方法。但是我們還是需要了解一下排序和查詢內部的原理,下面讓我們學習一下各類排序與查詢演算法 2 - 歸併排序 第一種高效的排序演算法是歸併排序,按照分治三步法,對歸併排序演算法介紹如下: 劃分問題:把序列分成
資料結構:排序(1)
王爭資料結構11筆記 1、氣泡排序、插入排序、選擇排序是基於比較的排序。時間複雜度為。 2、快排,歸併排序也是基於比較的排序。時間複雜度為 3、桶排序、計數排序、基數排序不是基於比較的排序,其時間複雜度為 4、氣泡排序BS:一次冒泡會讓至少一個元素移動它應該在的位置,
SpringCloud(五):斷路器(Hystrix)
一、簡介 http://projects.spring.io/spring-cloud/spring-cloud.html#_circuit_breaker_hystrix_clients Netflix開源了Hystrix元件,實現了斷路器模式,SpringCloud對這
python手記(四):pillow(五)最後一篇:過濾器,截圖。
人生不易且無趣,一起找點樂子吧。歡迎評論,和文章無關也可以。 這篇就當pillow的最後一篇好了,後面的模組沒有前面的有趣,主要是一些細節上的處理,例如圖片的文字啊,文字的型別啊。 無非就是告訴你很多東西都可以自定義,建立你自己的個性
Java排序演算法(五)--希爾排序(ShellSort)
希爾排序(插入排序-漸減增量排序diminishing increment sort): 思想:1.將原始陣列按照增量分解為多個數組,分別按插入排序調好子序列的順序;
Java for Web學習筆記(二五):JSTL(1)使用JSTL
在前面已經使用過JSTL,例如<c:url>,fn是JSTL的functionlibrary,而c是JSTL的tag library。使用它們,我們要告知解析器,如下: <%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core
【SpringCloud Greenwich版本】第五章:斷路器(hystrix)
一、SpringCloud版本 本文介紹的Springboot版本為2.1.1.RELEASE,SpringCloud版本為Greenwich.RC1,JDK版本為1.8,整合環境為IntelliJ IDEA 二、hystrix介紹 Netflix的創造了一個呼叫的庫Hystri
vue的原始碼學習之五——7.資料驅動(update)
1. 介紹 版本:2.5.17。 我們使用vue-vli建立基於Runtime+Compiler的vue腳手架。 &nb