
ElasticSearch原始碼解析(三):索引建立
阿新 • • 發佈:2019-01-02
我們先來看看索引建立的事例程式碼:
Directory directory = FSDirectory.getDirectory("/tmp/testindex"); // Use standard analyzer Analyzer analyzer = new StandardAnalyzer(); // Create IndexWriter object IndexWriter iwriter = new IndexWriter(directory, analyzer, true); iwriter.setMaxFieldLength(25000); // make a new, empty document Document doc = new Document(); File f = new File("/tmp/test.txt"); // Add the path of the file as a field named "path". Use a field that is // indexed (i.e. searchable), but don't tokenize the field into words. doc.add(new Field("path", f.getPath(), Field.Store.YES, Field.Index.UN_TOKENIZED)); String text = "This is the text to be indexed."; doc.add(new Field("fieldname", text, Field.Store.YES,Field.Index.TOKENIZED)); // Add the last modified date of the file a field named "modified". Use // a field that is indexed (i.e. searchable), but don't tokenize the field // into words. doc.add(new Field("modified",DateTools.timeToString(f.lastModified(), DateTools.Resolution.MINUTE),Field.Store.YES, Field.Index.UN_TOKENIZED)); // Add the contents of the file to a field named "contents". Specify a Reader, // so that the text of the file is tokenized and indexed, but not stored. // Note that FileReader expects the file to be in the system's default encoding. // If that's not the case searching for special characters will fail. doc.add(new Field("contents", new FileReader(f))); iwriter.addDocument(doc); iwriter.optimize(); iwriter.close();
從程式碼中可以看出來索引index的建立主要是在IndexWriter中進行的。IndexWriter的呼叫關係如下圖所示:

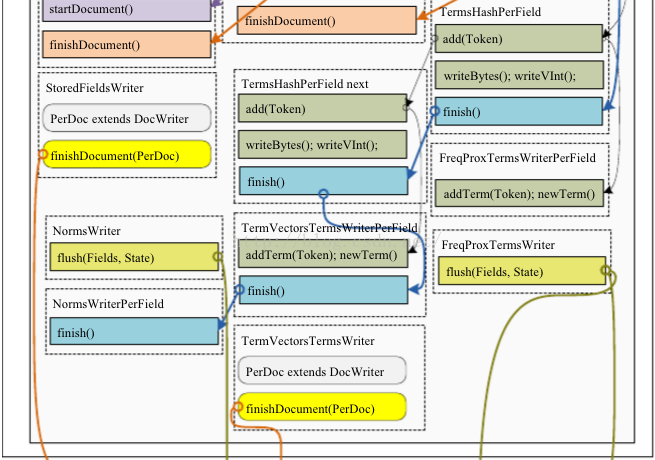

最終生成索引檔案。
.fdx是field索引檔案,.fdt是field資料檔案,.nrm是Norms調節因子檔案,計算文件得分用的,.tvf是term向量檔案之一,儲存了term列表、詞頻還有可選的位置和偏移資訊,.tvx儲存在.tvf域檔案和.tvd文件資料檔案中的偏移量,.tvd是field資料檔案,它包含fields的數目,有term向量的fields的列表,還有指向term向量域檔案(.tvf)中的域資訊的指標列表。該檔案用於對映(map
out)出那些儲存了term向量的fields,以及這些field資訊在.tvf檔案中的位置。.prx 檔案是位置資訊資料檔案容納了每一個term出現在所有文件中的位置的列表。.tti/.tis分別是term資訊索引檔案和term資訊資料檔案。
知道了IndexWriter的呼叫關係,那麼它的原始碼究竟是怎麼樣的呢?接下來我們就來分析索引建立的相關原始碼。IndexWriter的addDocument函式最終是呼叫DocementWriter的updateDocument函式,先上updateDocument函式的圖:
boolean updateDocument(Iterable<? extends IndexableField> doc, Analyzer analyzer, Term delTerm) throws IOException, AbortingException { <span style="white-space:pre"> </span>//預處理,下面會講這個函式的作用 boolean hasEvents = this.preUpdate(); <span style="white-space:pre"> </span>//獲取鎖 ThreadState perThread = this.flushControl.obtainAndLock(); DocumentsWriterPerThread flushingDWPT; try { <span style="white-space:pre"> </span> //確定文件已經開啟 this.ensureOpen(); this.ensureInitialized(perThread); assert perThread.isInitialized(); <span style="white-space:pre"> </span> //非同步flush記憶體中已經存在的文件到磁碟 DocumentsWriterPerThread dwpt = perThread.dwpt; int dwptNumDocs = dwpt.getNumDocsInRAM(); try { dwpt.updateDocument(doc, analyzer, delTerm); } catch (AbortingException var18) { this.flushControl.doOnAbort(perThread); dwpt.abort(); throw var18; } finally { <span style="white-space:pre"> </span>//獲取還在記憶體中的文件的數目 this.numDocsInRAM.addAndGet(dwpt.getNumDocsInRAM() - dwptNumDocs); } boolean isUpdate = delTerm != null; //後置處理 flushingDWPT = this.flushControl.doAfterDocument(perThread, isUpdate); } finally { //釋放執行緒池中的當前使用執行緒 this.perThreadPool.release(perThread); } <span style="white-space:pre"> </span>//後置重新整理 return this.postUpdate(flushingDWPT, hasEvents); }
下面看看前置update處理和後置update處理
private boolean preUpdate() throws IOException, AbortingException {
this.ensureOpen();
boolean hasEvents = false;
//如果存在停滯的執行緒或待重新整理佇列有內容
if(this.flushControl.anyStalledThreads() || this.flushControl.numQueuedFlushes() > 0) {
//如果當前輸出流具有刪除和寫入許可權
if(this.infoStream.isEnabled("DW")) {
this.infoStream.message("DW", "DocumentsWriter has queued dwpt; will hijack this thread to flush pending segment(s)");
}
//多個執行緒不斷將segment同步地寫入到directory中去
while(true) {
DocumentsWriterPerThread flushingDWPT;
while((flushingDWPT = this.flushControl.nextPendingFlush()) == null) {
if(this.infoStream.isEnabled("DW") && this.flushControl.anyStalledThreads()) {
this.infoStream.message("DW", "WARNING DocumentsWriter has stalled threads; waiting");
}
this.flushControl.waitIfStalled();
if(this.flushControl.numQueuedFlushes() == 0) {
if(this.infoStream.isEnabled("DW")) {
this.infoStream.message("DW", "continue indexing after helping out flushing DocumentsWriter is healthy");
}
return hasEvents;
}
}
hasEvents |= this.doFlush(flushingDWPT);
}
} else {
return hasEvents;
}
}private boolean postUpdate(DocumentsWriterPerThread flushingDWPT, boolean hasEvents) throws IOException, AbortingException {
//如果有待重新整理的segment在記憶體中,那麼把它們刷入檔案
hasEvents |= this.applyAllDeletes(this.deleteQueue);
if(flushingDWPT != null) {
hasEvents |= this.doFlush(flushingDWPT);
} else {
DocumentsWriterPerThread nextPendingFlush = this.flushControl.nextPendingFlush();
if(nextPendingFlush != null) {
hasEvents |= this.doFlush(nextPendingFlush);
}
}
return hasEvents;
}public void updateDocument(Iterable<? extends IndexableField> doc, Analyzer analyzer, Term delTerm) throws IOException, AbortingException {
this.testPoint("DocumentsWriterPerThread addDocument start");
assert this.deleteQueue != null;
this.reserveOneDoc();
this.docState.doc = doc;
this.docState.analyzer = analyzer;
this.docState.docID = this.numDocsInRAM;
boolean success = false;
try {
try {
this.consumer.processDocument();
} finally {
this.docState.clear();
}
success = true;
} finally {
if(!success) {
this.deleteDocID(this.docState.docID);
++this.numDocsInRAM;
}
}
this.finishDocument(delTerm);
}