spark學習記錄(三、spark叢集搭建)
阿新 • • 發佈:2019-01-13
一、安裝spark
1.上傳壓縮包並解壓
2.在conf目錄下配置slaves
cp slaves.template slaves//在master機上配置worker節點
hadoop2
hadoop33.配置spark-env.sh
cp spark-env.sh.template spark-env.shexport SPARK_MASTER_IP=hadoop1 export SPARK_MASTER_PORT=7077 //每臺worker使用的cpu核數 export SPARK_WORKER_CORES=2 //每臺worker的使用記憶體 export SPARK_WORKER_MEMORY=1g //webUI頁面埠號 export SPARK_MASTER_WEBUI_PORT=8888
4.將spark檔案複製到其他機子上
scp -r spark-2.4.0-bin-hadoop2.7/ hadoop2:/usr/local/5.驗證
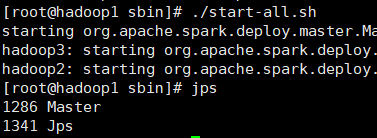
在sbin目錄下
二、執行案例
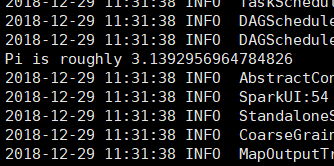
spark官方提供了一個案例,求π的值
object SparkPI { def main(args: Array[String]) { val conf = new SparkConf().setAppName("Spark Pi").setMaster("local[2]") val spark = new SparkContext(conf); val slices = 100; val n = 1000 * slices //選n個點 val count = spark.parallelize(1 to n,slices).map({ i => def random: Double = java.lang.Math.random() //這裡取圓心為座標軸原點,在正方向中不斷的隨機選點 val x = random * 2 - 1 val y = random * 2 - 1 println(x+"--"+y) //通過在圓內的點 if (x*x + y*y < 1) 1 else 0 }).reduce(_ + _) //pi=S2=S1*count/n println("Pi is roughly " + 4.0 * count / n) spark.stop() } }
在bin目錄下執行
./spark-submit --master spark://hadoop1:7077 --class org.apache.spark.examples.SparkPi /usr/local/spark-2.4.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.0.jar