
斯坦福機器學習: 網易公開課系列筆記(五)——高斯判別分析、樸素貝葉斯
高斯判別分析(Gaussian discriminant analysis)
判別模型和生成模型
前面我們介紹了Logistic迴歸,通過學習hΘ(x)來對資料的分類進行預測:給定一個特徵向量x→輸出分類y∈{0,1}。這類通過直接學習分類決策函式 hΘ(x)或者直接對後驗概率分佈P(y|x)進行建模的學習方法稱為判別方法,得到的模型稱為判別模型。如果是直接對P(x|y)進行建模(有時還需要對P(y)進行建模),即通過樣本資料,分析在已知類別y的情況下x具有某些特徵的概率,稱為生成方法,學習到的模型稱為生成模型,然後使用P(x|y)通過貝葉斯公式求得argmaxP(y|x)=P(x|y)P(y)/P(x)進行預測。
多元高斯分佈
如題,高斯判別分析即是一個生成模型。之前我們都接觸過一元正態分佈,在介紹高斯判別分析之前,我們這裡先介紹下多元正態分佈:

這裡展示幾個均值為0,Σ取不同值的高斯分佈的影象便於直觀上的理解:
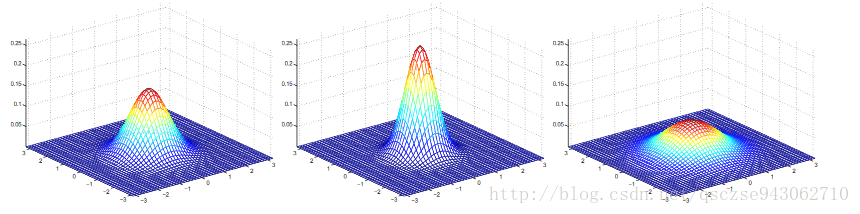
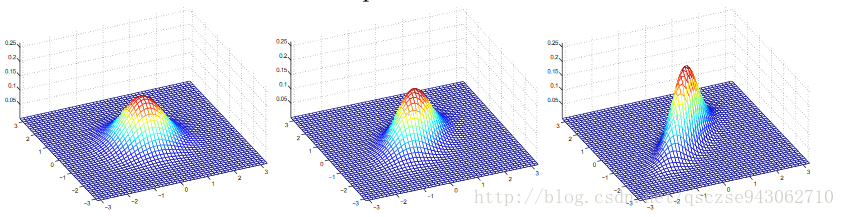
按行數,Σ(2*2)的取值依次為I,0.6I,2I;I,主對角線為1副對角線為0.5,主對角線為1副對角線為0.8。可以看到,主對角線的元素控制整個分佈的“高低”,副對角線的元素控制整個分佈的“扁圓”,當副對角線元素取負值時,將沿著與影象上對稱的方向進行壓縮。均值則控制分佈在水平面的整體位置。
GDA模型
高斯判別分析
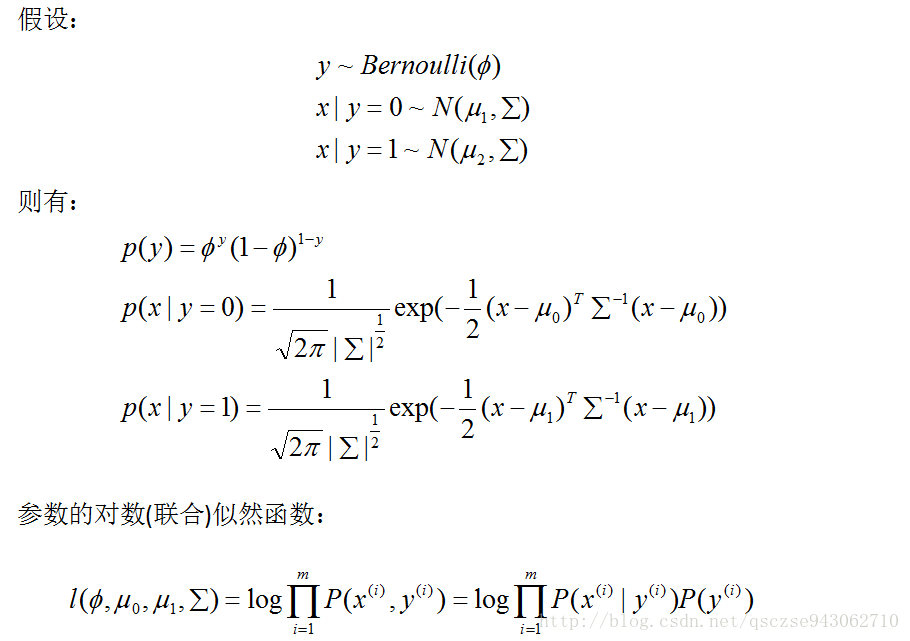
我們對每個引數求導,令導數為0:
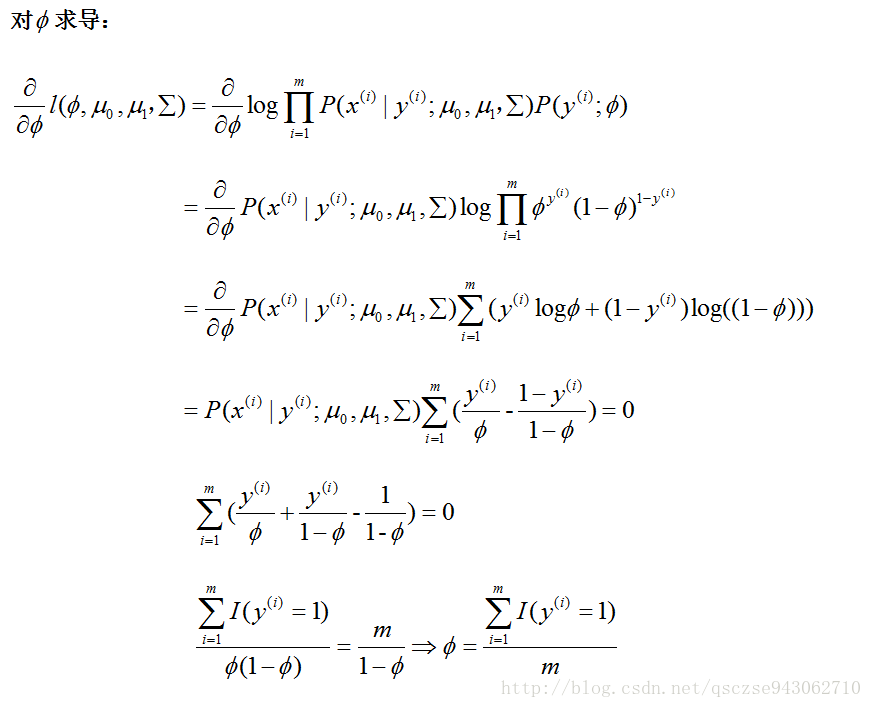
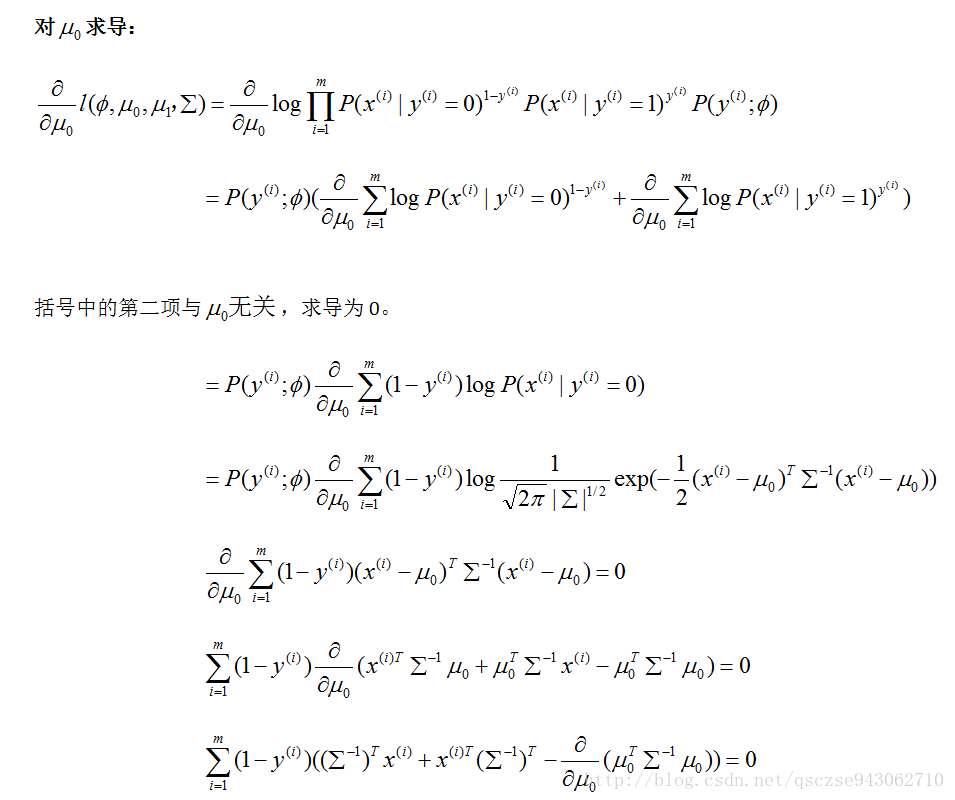
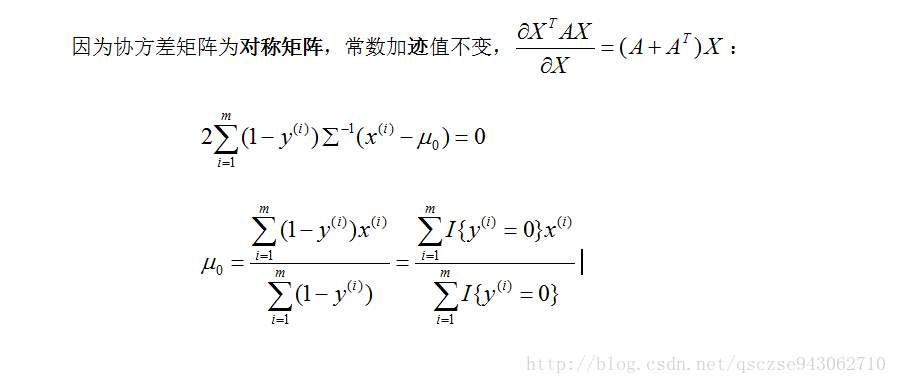
對μ1的求法同μ0
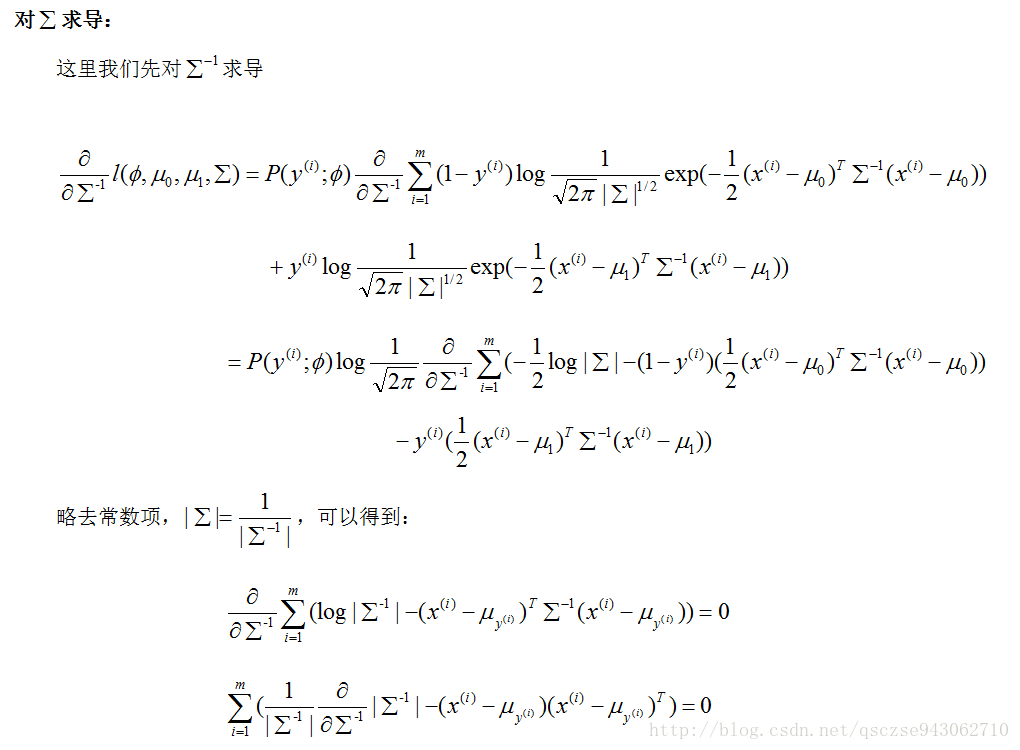
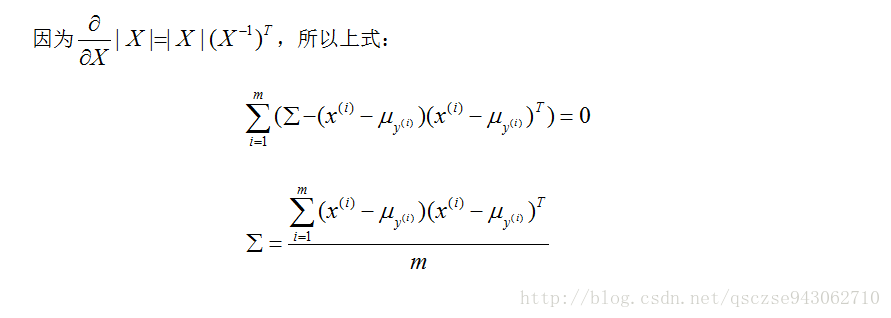
引數求解完畢,接下來我們就要使用模型進行預測,即求解:
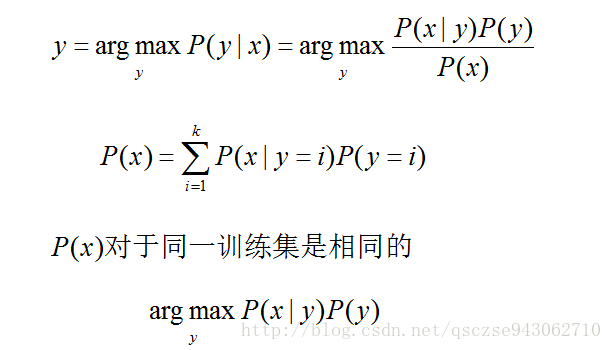
至此,便是高斯判別模型的整個執行流程,直觀上理解:
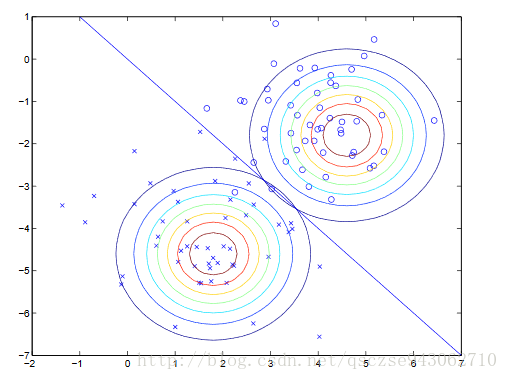
我們根據兩類資料建立了兩個高斯分佈,兩者在概率閾值的交線成為分類的判別線,在圖中,分類線的右上為正類,左下為負類。
其實,如果我們假設x|y服從高斯分佈,則後驗概率y=1|x滿足邏輯斯蒂迴歸。在實際應用中,如果我們不知道資料服從什麼分佈,那麼選用邏輯斯蒂迴歸
個人感覺,如果將P(y)由Bernoulli分佈改為多項式分佈,建立多個高斯分佈也可以用於多分類問題的處理上。
樸素貝葉斯(Naive Bayes)
在垃圾郵件分類器中,我們假設根據某個單詞是否出現來判斷其是否屬於垃圾郵件,假設我們的詞庫共有10000個單詞,則每一封待判定郵件組成一個10000維的特徵向量,每個分量對應於該單詞是否出現:出現為1,不出現為0(這種特徵向量的定義方式說明每個xi是否出現的概率服從Bernoulli分佈)。輸出y∈{0,1},y=1時判定該郵件為垃圾郵件,y=0時判定為正常郵件。
我們假設xi是條件獨立的(在y給定的情況下,xi相互獨立)。直觀理解就是一封郵件某個單詞是否出現不會影響其他單詞出現的概率。用概率公式表述如下:
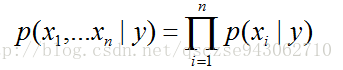
PS:前面我們說過,下標表示向量的某個分量,帶括號的上標表示某個樣本
我們定義:
1)某個郵件是垃圾郵件的**先驗概率**P(y=1)=ϕy
2)垃圾郵件中某個單詞出現的概率P(xi=1|y=1)=ϕi|y=1
3)正常郵件中某個單詞出現的概率P(xi=1|y=0)=ϕi|y=0
同樣,寫出其聯合分佈概率對數似然性函式:
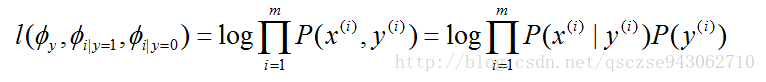
對各個引數求導,令導數為0,解出模型引數:
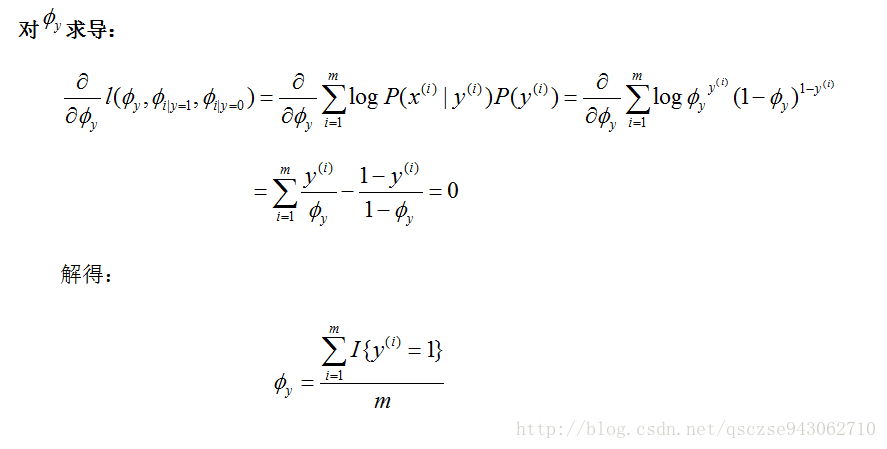
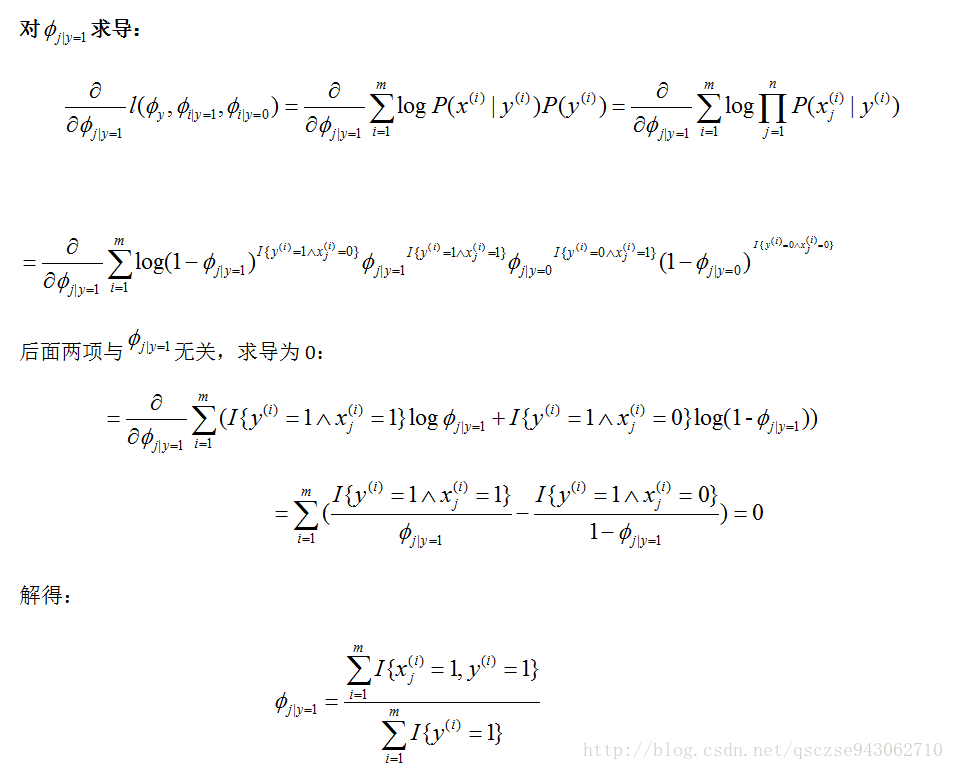
PS:之前推錯了,在此更正!!!!
ϕi|y=0解法同上。
Na.Bayes的執行方式同高斯判別分析。都是求使後驗概率最大的y即是預測樣本的分類。
同理,將特徵向量的每個分量的取值擴充套件為{1,2,…,k},運用多項式分佈也可以用來處理多分類問題。
Laplace平滑
我們使用上述方法生成的模型進行垃圾郵件處理時,會有一個問題:如果我們的詞典用的某個單詞在所有的樣本中都沒有出現過,那麼當我們第一次碰到這個單詞的時候,帶入上述的後驗概率計算公式時會發現,分子和分母都為0!
為了避免這種情況的發生,我們在計算公式的分子和分母個各新增一項來避免這個問題,這種處理方式稱為Laplace平滑:
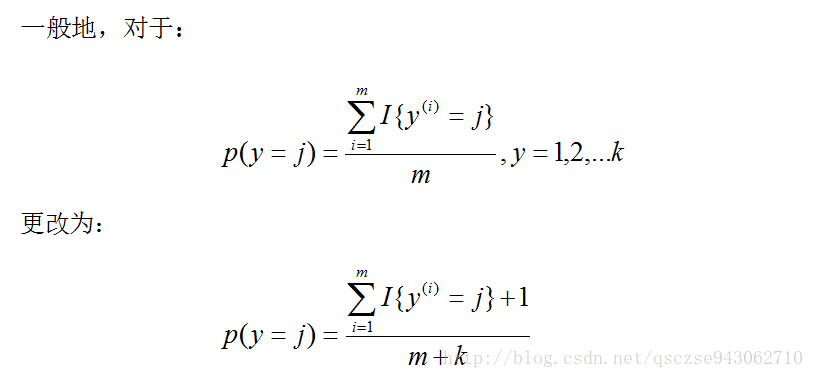
相關推薦
斯坦福機器學習: 網易公開課系列筆記(五)——高斯判別分析、樸素貝葉斯
高斯判別分析(Gaussian discriminant analysis) 判別模型和生成模型 前面我們介紹了Logistic迴歸,通過學習hΘ(x)來對資料的分類進行預測:給定一個特徵向量x→輸出分類y∈{0,1}。這類通過直接
生成學習演算法_高斯判別分析_樸素貝葉斯_斯坦福CS229_學習筆記
Part IV Generative Learning Algorithms 回顧上一部分的內容,我們解決問題的出發點在於直接對p(y|x;)建模:如線性迴歸中y建模為高斯分佈,邏輯迴歸y建模為伯努利分佈。這樣建模的好處在於可以直接得到x到y的對映關係,理解起來也比較直接。這樣建模
scikit-learn機器學習(五)--條件概率,全概率和貝葉斯定理及python實現
在理解貝葉斯之前需要先了解一下條件概率和全概率,這樣才能更好地理解貝葉斯定理 一丶條件概率 條件概率定義:已知事件A發生的條件下,另一個事件B發生的概率成為條件概率,即為P(B|A) 如圖A∩B那一部分的發生的概率即為P(AB), P(AB)=發
網易公開課系列-國防科大公開課-數學建模-第九講-數學建模綜合案例
image ont 建模 科學技術 bubuko http 學技術 所有 數學建模 數學建模----從自然走向理性之路第九講 數學建模綜合案例國防科學技術大學 吳孟達 教授課程鏈接:http://open.163.com/special/cuvocw/shuxuejianm
機器學習:貝葉斯分類器,樸素貝葉斯,拉普拉斯平滑
數學基礎: 數學基礎是貝葉斯決策論Bayesian DecisionTheory,和傳統統計學概率定義不同。 頻率學派認為頻率是是自然屬性,客觀存在的。 貝葉斯學派,從觀察這出發,事物的客觀隨機性只是觀察者不知道結果,也就是觀察者的知識不完備,對於知情者而言,事物沒有隨機性,隨機
《機器學習西瓜書》學習筆記——第七章_貝葉斯分類器_樸素貝葉斯分類器
樸素:特徵條件獨立;貝葉斯:基於貝葉斯定理。 樸素貝葉斯是經典的機器學習演算法之一,也基於概率論的分類演算法,屬於監督學習的生成模型。樸素貝葉斯原理簡單,也很容易實現,多用於文字分類,比如垃圾郵件過濾。 1.演算法思想——基於概率的預測 貝葉斯決策論是概率框架下
機器學習-資料分析之樸素貝葉斯過濾垃圾郵件
資料分析之過濾垃圾郵件 前沿 之前也學了一些資料分析的案例從一直沒有記錄,所有準備從現在開始把所學的都記錄在CSDN中。如果大家看到我的博文有什麼不理解或者還想學習更深入的可以去上面的網站。 樸素貝葉斯之過濾垃圾郵件 使用樸素貝葉斯解決一些生活中的問題。先從文字內容得
【機器學習-西瓜書】七、樸素貝葉斯分類器
推薦閱讀:拉普拉斯修正 7.3樸素貝葉斯分類器 關鍵詞: 樸素貝葉斯;拉普拉斯修正 上一小節我們知道貝葉斯分類器的分類依據是這公式:P(c∣x)=P(x,c)P(x)=P(c)⋅P(c∣x)P(x) ,對於每個樣本而言,分母P(x)=∑mi=1P(
各種機器學習方法(線性迴歸、支援向量機、決策樹、樸素貝葉斯、KNN演算法、邏輯迴歸)實現手寫數字識別並用準確率、召回率、F1進行評估
本文轉自:http://blog.csdn.net/net_wolf_007/article/details/51794254 前面兩章對資料進行了簡單的特徵提取及線性迴歸分析。識別率已經達到了85%, 完成了數字識別的第一步:資料探測。 這一章要做的就各
《Spark機器學習》筆記——Spark分類模型(線性迴歸、樸素貝葉斯、決策樹、支援向量機)
一、分類模型的種類 1.1、線性模型 1.1.1、邏輯迴歸 1.2.3、線性支援向量機 1.2、樸素貝葉斯模型 1.3、決策樹模型 二、從資料中抽取合適的特徵 MLlib中的分類模型通過LabeledPoint(label: Double, features
機器學習之分類器——Matlab中各種分類器的使用總結(隨機森林、支援向量機、K近鄰分類器、樸素貝葉斯等)
Matlab中常用的分類器有隨機森林分類器、支援向量機(SVM)、K近鄰分類器、樸素貝葉斯、整合學習方法和鑑別分析分類器等。各分類器的相關Matlab函式使用方法如下:首先對以下介紹中所用到的一些變數做統一的說明: train_data——訓練樣本,矩陣的每
(參評)機器學習筆記——鳶尾花資料集(KNN、決策樹、樸素貝葉斯分析)
最開始選取鳶尾花資料集來了解決策樹模型時,筆者是按照學習報告的形式來寫得,在這裡將以原形式上傳。格式較為繁複,希望讀者可以耐心看完,謝謝大家。目錄 6.總結 7.問題 1、問題描述 iris是鳶尾植物,這裡儲存了其萼片和花瓣的長寬,共4個屬性,鳶尾
機器學習吳恩達-線性回歸筆記(1)
設置 裏的 更新 sha names value p s itl inf 回歸問題的思想(1)先找到損失函數,(2)求損失函數最小化後的參數 假設我們的數據是(m,n)有m行數據,n個特征(feature) 則我們預測函數為 : 寫成向量形式為(xo=1):
《統計學習方法(李航)》講義 第04章 樸素貝葉斯
ima .cn 效率 常用 1-1 估計 實現 技術 com 樸素貝葉斯(naive Bayes) 法是基於貝葉斯定理與特征條件獨立假設的分類方法。對於給定的訓練數據集,首先基於特征條件獨立假設學習輸入/輸出的聯合概率分布;然後基於此模型,對給定的輸入x,利用貝
【統計學習方法-李航-筆記總結】四、樸素貝葉斯法
本文是李航老師《統計學習方法》第四章的筆記,歡迎大佬巨佬們交流。 主要參考部落格: https://blog.csdn.net/zcg1942/article/details/81205770 https://blog.csdn.net/wds2006sdo/article/detail
斯坦福機器學習網易公開課筆記1
之前在coursera上看了Andrew Ng的機器學習課程,那個課程比較簡明,適合對機器學習有一個整體的印象,但是很多細節的內容和推導都忽略了。現在想要了解機器學習更多,所以開始看Andrew Ng在網易公開課上的機器學習課程,並對每一講整理筆記,以促使自己更好的理解和記
【深度學習】吳恩達網易公開課練習(class2 week1 task2 task3)
公開課 網易公開課 blog 校驗 過擬合 limit 函數 its cos 正則化 定義:正則化就是在計算損失函數時,在損失函數後添加權重相關的正則項。 作用:減少過擬合現象 正則化有多種,有L1範式,L2範式等。一種常用的正則化公式 \[J_{regularized}
網易公開課《Linux核心分析》學習心得-Linux核心如何裝載和啟動一個可執行程式
實驗 設定斷點sys_execeve,並繼續 程式碼執行到了SyS_execve。在QEMU中執行exec,可以看到只能出現兩句,沒有完全執行完畢。 設定斷點load_elf_binary和start_thread,並執行,可以看到程式碼停在了
網易公開課《Linux核心分析》學習心得-理解程序排程時機跟蹤分析程序排程與程序切換的過程
首先在核心程式碼中搜索schedule,發現以下結果 在core.c檔案中是 實驗 設定斷點 跟蹤schedule的程序 可以看到 struct task_struct *tsk = current; sched_subm
斯坦福機器學習公開課--整理筆記(…
跟老闆聊了很久之後,決定換一個研究方向,本來想專門寫一篇博文說說資料探勘與機器學習,後來轉念也想也算了,畢竟之前還是有很多可以用上的知識,這幾天準備把Andrew大牛的機器學習公開課重新刷一遍,簡單做一下筆記好了。 第一課是基本介紹,略過。 第二課:監督學習應用.梯度下降: 這節課主要探究的是監督