
生成學習演算法_高斯判別分析_樸素貝葉斯_斯坦福CS229_學習筆記
Part IV Generative Learning Algorithms
回顧上一部分的內容,我們解決問題的出發點在於直接對p(y|x;)建模:如線性迴歸中y建模為高斯分佈,邏輯迴歸y建模為伯努利分佈。這樣建模的好處在於可以直接得到x到y的對映關係,理解起來也比較直接。這樣建模的演算法,稱為判別學習演算法(discriminative learning algorithms)。除此之外,有另外一種建模的思路,即生成學習方法(generative learning algorithms)的思路,並不是直接對於p(y|x;
)建模,而是對於p(y)和p(x|y)進行建模,當做先驗知識,然後利用貝葉斯公式進行後驗概率p(y|x)的推導。根據貝葉斯公式,對每一類都進行計算,選取後驗概率最大的一類作為資料的類別。
 (1)
(1)
假設在二分類問題中,雖然p(x)可以通過得到:
但是一般都不關注於p(x),因為對於每一類來說,p(x)都是一樣的:

單看上面可以不會很明白,讓我們看看兩種常用的生成學習演算法,會加深我們的理解。
高斯判別分析(Gaussian Discriminant Analysis,GDA)
高斯判別分析(GDA)常用作當x服從於高斯分佈時(也就是連續性變數)的建模。雖然叫做高斯判別分析,但是卻是一個生成演算法。利用二分類問題作為介紹的背景,GDA流程如下。
假設y服從於伯努利分佈,x|y分別服從於二元高斯分佈。

寫出上式分佈的表示式 :
 (2)
(2)
通過這樣建模,引數有,
,
,協方差陣
,共四個引數。這裡兩個二元高斯分佈採用同樣的
,這是需要重點注意的地方,至於為什麼要這樣做,我也沒有搞明白,有可能是為了簡單接下來的引數計算的步驟吧,或許也有更深層次的原因。
進行極大似然估計:
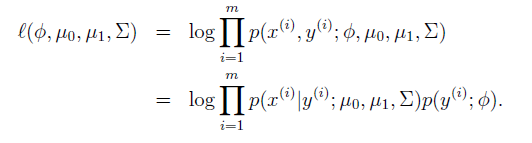
直接求解得到引數:

:正樣本所佔的比例。
:負樣本特徵向量的均值。
:正樣本特徵向量的均值。
:所有樣本計算得到的協方差陣。
有了以上引數,那麼(2)式就得到了。當有新的待判斷的資料來臨時。將該資料分別代入(1)式,計算結果,看屬於哪一類的概率大,就歸入哪一類。至此,模型就建立好了。
講義中,有一張圖,可以幫助理解GDA在做了什麼。

分別以正樣本的均值和負樣本的均值,生成相同協方差的二元高斯函式,雖然在判斷樣本屬於哪一類時,需要帶入貝葉斯公式進行計算,但是本質正如上圖所示,畫出一條直線,直線上方屬於一類而下方屬於另一類。在此情形下,不就和邏輯迴歸、感知機演算法那樣一刀切判別樣本如出一轍嗎?都是需要一條直線作為決策邊界進行決斷。看來判別學習演算法邏輯迴歸和生成學習演算法GDA彷彿又有某種聯絡。
高斯判別分析和邏輯迴歸的思考
那麼高斯判別分析(GDA)和邏輯迴歸(LR)二者是否有某種共性呢?果不其然,你可以接著(2)式往下推(有推出來的夥伴不吝賜教),看看GDA中的後驗概率p(y=1|x)應該是怎麼樣:

根據先驗分佈推斷出來的後驗分佈p(y=1|x)正是邏輯迴歸。這種感覺的確很奇妙。
在GDA中,若先驗概率p(x|y)服從於多元正態分佈且採用相同的 作為引數,那麼可以得到其後驗概率的形式即為邏輯迴歸。但是反之卻不是這樣。後驗概率為邏輯迴歸有可能對應著其他的分佈:例如將上述的先驗分佈改為引數為
和
的泊松分佈,那麼得到的後驗概率形式也仍然為邏輯迴歸形式。
換句話說,GDA是比LR更為強的假設。因為由GDA可以推出LR,單LR卻不一定保證GDA。
因為GDA的假設更強,所以如果x對於高斯分佈擬合的越好,那麼GDA的效果也就越好,因此往往GDA不太需要許多的資料去擬合數據真實的分佈特徵,就能夠得到較好的效果;而反觀如果從判別學習演算法LR出發,由於作為相對較弱的假設,因此對於資料的包容性也就越好,模型的魯棒性也較強,能夠適應於其他分佈的資料,因此也往往需要更多的資料去擬合。這二者的互相權衡,也為我們選擇那種演算法提供了一些參考的地方。一些關於生成學習演算法和判別學習演算法的討論在下文也會涉及。
樸素貝葉斯(Naive Bayes,NB)
上文提到的GDA解決的是連續性變數的問題,那麼如果變數為離散型呢?這裡可以採用樸素貝葉斯的方法進行解決。
以垃圾郵件分類問題作為例子。又是一個二元分類的問題。但是與之前的不同,根據對於特徵向量的建模方式,NB演算法可以有兩種形式。
多元伯努利事件模型
在多元伯努利事件模型中,我們這麼設定特徵向量x,這種思路也是最基本的思路:

x的長度即為詞字典的長度,若字典有50000個單詞,x即為50000維向量,很明顯便會發現這個向量很稀疏,這樣設定很佔記憶體空間。不禁會感到向量維數感覺有點多啊,一個修改辦法便是,你可以選用你的訓練集中所出現過的片語成你的字典,這樣會減少一些維數。通過上述方式設定特徵向量,也就是說一封郵件用一個n維向量(n為字典中詞的個數)表示,若郵件中出現某單詞,那麼該位置上就取值為1,否則為0。這樣看來一封郵件就是一個n元伯努利分佈變數組成的向量啊。
下面,便要開始建模了。按照生成學習演算法的思路,首先,我們應該給p(x|y)建模,為了建模,這裡需要做一個強假設:假設x中的每個元素 互相條件獨立。這個假設的設定,也是樸素貝葉斯演算法這個名稱的由來(真是樸素)。
注意這裡條件獨立與獨立的區別:獨立則條件獨立,反之則不一定對,條件獨立這個假設相對於獨立這個假設要弱一些:
若A,B獨立,則 p(AB)=p(A)p(B)
若A,B條件獨立,則 p(AB|C)=p(A|C)p(B|C)
在樸素貝葉斯假設(Naive Bayes Assumption)的基礎上,首先給p(x|y)建模:
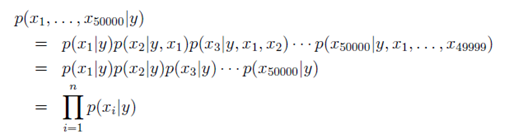
第一個等式由鏈式法則直接推出;第二個等式基於樸素貝葉斯假設推出,因為互相條件獨立,彼此不受影響。
對於垃圾郵件分類來說,其是一個伯努利分佈;而對於每一個 來說,又滿足一個伯努利分佈。因此我們需要求解的引數如下所示。共計 1 + 2 * v 個引數,這裡 v 表示字典中單詞的個數。

構建最大似然方程:

求解引數:

:在垃圾郵件中,j單詞出現的頻率。
:在非垃圾郵件中,j單詞出現的頻率。
:垃圾郵件佔整個郵件的比例。
得到引數後,當有一封郵件來臨需要判斷是否為垃圾郵件時,首先構造該郵件的特徵向量,然後分別計算後驗概率 p(y=1|x)和p(y=0|x)進行判斷,選取概率最大的一類進行歸類(0或1)就可以了。例如計算p(y=1|x),可根據下式進行計算。因為比較的時候分母是相同的,所以實際計算的時候,只計算分子就可以了。

這就是最樸素的貝葉斯分類的原理了,思路清晰,模型不復雜,雖然做了一個較強的假設,但是仍然能夠得到不錯的分類效果。
同樣也可以對於其做一些擴充套件:例如 的取值可以從(0,1)擴充套件為(0,1,2...k),其實就是從伯努利分佈擴充套件為多項分佈。道理是一樣的,這裡就不進行推導了。
記得在上文提到,這樣構造特徵向量感覺有點笨,那麼可以在構造特徵向量這裡出發,引出下面一種建模方式。
多項式事件模型
讓我們再看一下第一種特徵向量的表示方式:字典有多少個單詞,那麼特徵向量就有多少維,這實際上是一個很稀疏的特徵向量。那麼另外一種表現形式,就是從郵件本身的角度出發進行建模,假設郵件由125個單片語成:

那麼這裡的每個 的取值不再為0或者1,而是為該單詞在字典中的序號,若字典中有v個單詞,那麼
的取值為(1,2,3...v)。也就是說現在的
不再是伯努利分佈了,而是多項式分佈。這樣做的話就可以起到大大縮小每個特徵向量的目的,但是應注意由於郵件長度不同,因此每封郵件的特徵向量維度也不同。
同樣應用樸素貝葉斯假設進行p(x|y)建模:

形式上與之前一致,但是注意幾個細節。這裡的n表示郵件的長度而不是字典的長度;這裡的 取值有v個(v=字典中單詞的數量),且
服從於多項分佈而不是伯努利分佈。
需要計算的引數以下,引數數量同樣為 1 + 2*v:
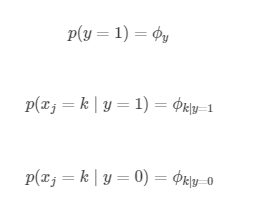
構建似然函式 :

進行引數估計得到結果:

:垃圾郵件中單詞k出現次數除以垃圾郵件中單詞總數。
:非垃圾郵件中單詞k出現次數除以非垃圾郵件中單詞總數。
:垃圾郵件數量除以總郵件數量。
對比多元伯努利事件模型和多項式事件模型,可以發現二者求解的引數一樣多,若字典長度為v,那麼都求解了2*v+1個引數。但是這裡仍然會存在著一些不同。因為在實際中,郵件的長度總是小於字典的長度,甚至於遠遠小於字典長度,這就造成了二者的不同。
其中最明顯的一點在於,多項式事件模型與多元伯努利事件模型的區別在於前者可以用較小的特徵向量表示每封郵件,。
另外一點在於判斷模型歸屬的計算之上。當獲取模型引數建立模型後,在生成模型演算法中,我們會通過分別計算後驗概率來判斷類別的歸屬。那麼二者計算的差異就在於 之上。在多元伯努利事件模型之中,需要計算v次連乘(v代表字典中單詞個數),而多項式事件模型中則需要進行n(n代表郵件長度)次連乘。這就體現了計算差異,因為往往v和n不在於一個數量級,而且v遠遠大於n。雖然在多元伯努利事件模型之中,引數
的計算要比多項式事件模型引數
計算要稍微簡單,但是考慮引數的值只計算了一次,所以引數的計算代價相比而言不會太高。因此,總體上來看,多項式事件模型節約了表示特徵向量的記憶體,同時也減少了後驗概率計算的時間。
拉普拉斯平滑(Laplace Smoothing)
我們可以對樸素貝葉斯演算法做一個改進,從而增強其魯棒性。這個改進稱為拉普拉斯平滑。我們先看會在樸素貝葉斯演算法中存在的一個問題。假設字典為50000維,有一個單詞HAHA,在字典中的序號為35000,但是沒有在你的訓練集合中出現過,也就是說在用來訓練的郵件中,不管是正樣本還是負樣本都沒有出現過HAHA這個單詞,那麼在利用最大似然估計去計算引數時會顯然得到如下結果:
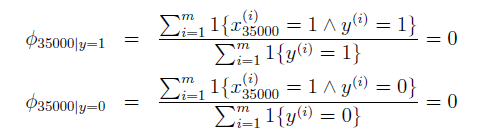
不管是對於垃圾郵件還是非垃圾郵件,引數都會被計算為0。 那麼這會帶來什麼問題呢?
假設現在,有一封郵件需要判斷是否為垃圾郵件,且該郵件中含有HAHA這個單詞。將該郵件帶入後驗概率公式進行判斷:

ZeroDivisionError :因為 ,且
。因此對於連乘的計算,結果都為0。這時候,就無法進行判別了。
解決這個問題的方法也很簡單,既然錯誤的原因是在訓練資料中沒有出現這個單詞,那麼讓每個單詞至少都出現,即給每一個初始的值賦予一個非0的值,就可以解決了。最直接的做法便是假設每個單詞都至少出現了一次。以多項分佈為例,假設 的取值為(1,2,3...k)共k個可能。那麼相應地修改引數表示:

其實這個操作可以理解為多增加了k個樣本,且每個樣本都只在第k的位置為1(以多元伯努利分佈為例)。這樣就使得每個單詞都至少出現一次,因此分母為m+k,從而保證
因此在多元伯努利事件模型中,修改引數為:

在多項事件模型中,修改引數為:
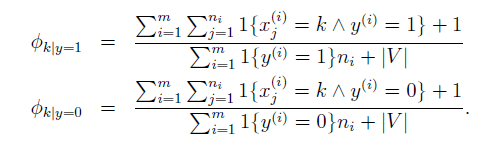
其中 代表單詞的數量 。
小結
在此對於判別學習演算法和生成學習演算法的思路進行小結。
判別學習演算法的思路在於,針對要解決的實際問題,根據先驗知識,可以先對p(y)建模,例如線性迴歸中的高斯分佈和邏輯迴歸中的伯努利分佈;之後根據一些方式(如GLM)對於 進行建模,建模後根據極大似然估計的方式求解引數從而得到模型。這相當於直接建立了x到y的對映關係,因此當有新的資料時,直接通過模型就可以得到結果。
生成學習的思路在於,同樣針對要解決的問題,根據先驗知識,對於p(y)建模,例如GDA和NB中的伯努利分佈;之後同樣是根據先驗知識,對 進行建模,同樣是根據極大似然估計的方式求解引數從而得到模型,此時得到的是p(x|y)的模型,相當於得到先驗概率;如果是分類問題,之後根據貝葉斯公式,推測出屬於每一類的後驗概率,根據得到的最高的後驗概率判斷資料屬於哪一類。
就過程而言,感覺生成學習演算法像是走了一條彎路,實際上我覺得生成學習演算法走的是一條比判別學習演算法更強假設的路:例如GDA中假設p(x|y)每一類服從高斯分類且協方差陣相同;NB中假設各個 條件獨立。這樣做的好處是,當資料的分佈的確接近於假設的那樣,那麼生成學習演算法便會以較少的訓練資料從而取得較好的效果。反觀判別學習演算法,由於其對於資料的包容性較強,魯棒性較好,因此適用於的場合更多,需要更多的資料進行訓練。二者的權衡,將為我們在實際解決問題中,提供一個啟發。