
記錄一次索引優化經歷
表結構如下:
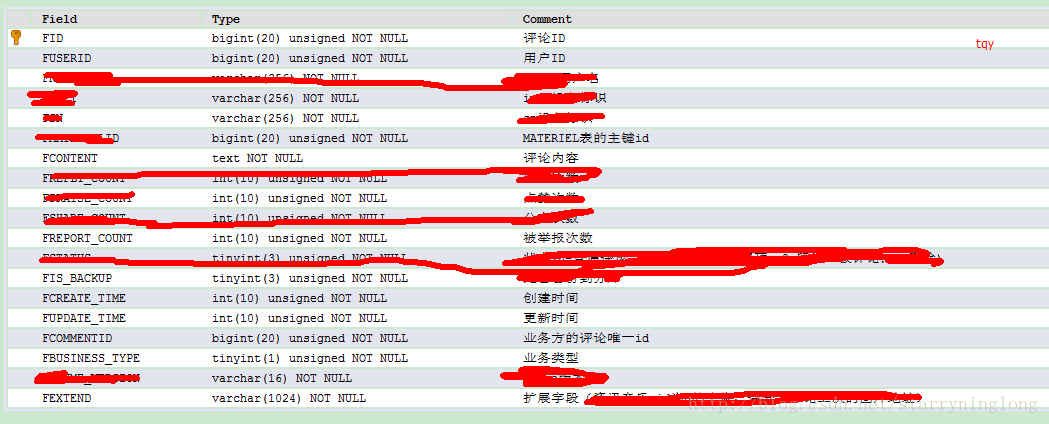
主要用到FIS_BACKUP、FID和FSTATUS幾個欄位做查詢。
索引如下:
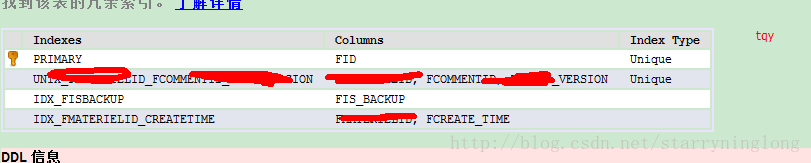
整張表,前半部分資料FIS_BACKUP都是1,後半部分資料FIS_BACKUP都是0,共2000w多條資料
查詢語句如下:
SELECT *
FROM `T_MP_COMMENT` C
WHERE C.FID>=15041538 AND C.FSTATUS!=9 AND C.FIS_BACKUP=0
ORDER BY C.FID
LIMIT 100;
使用count檢視FIS_BACKUP為0 和為1的分別有1000多w條資料。
SELECT COUNT 語句1執行耗時0.003秒,語句如下:
SELECT *
FROM `T_MP_COMMENT` C
WHERE C.FID>=15041538 AND C.FSTATUS!=9 AND C.FIS_BACKUP=0
ORDER BY C.FID
LIMIT 100;執行計劃:
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE C ref PRIMARY,IDX_FISBACKUP IDX_FISBACKUP 1 const 11799193 Using where語句2執行耗時26秒,語句如下:
SELECT *
FROM `T_MP_COMMENT` C
WHERE C.FID>=15041538 AND C.FSTATUS!=9 AND C.FIS_BACKUP=1 執行計劃:
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE C ref PRIMARY,IDX_FISBACKUP IDX_FISBACKUP 1 const 11799193 Using where以上出現原因分析:
- 都使用了FIS_BACKUP索引
- extra都使用了where
- 綜上可知,第二個語句執行的時候,雖然用到了索引,但是一直掃描到最後一條,但是第一個語句執行的時候只掃描了前幾百條就找到了,所以會出現這麼大的偏差。
第二種情況:
語句1耗時0.002秒,語句如下:
SELECT *
FROM `T_MP_COMMENT` C
WHERE C.FID>=0 AND C.FSTATUS!=9 AND C.FIS_BACKUP=1
ORDER BY C.FID
LIMIT 100;執行計劃:
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE C ref PRIMARY,IDX_FISBACKUP IDX_FISBACKUP 1 const 11799193 Using where語句2耗時0.002秒,語句如下:
SELECT *
FROM `T_MP_COMMENT` C
WHERE C.FID>=0 AND C.FSTATUS!=9 AND C.FIS_BACKUP=0
ORDER BY C.FID
LIMIT 100;執行計劃:
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE C ref PRIMARY,IDX_FISBACKUP IDX_FISBACKUP 1 const 11799193 Using where分析:
- 都使用了FIS_BACKUP索引
- extra都使用了where
- 綜上可知:兩者都使用了where查詢,並且兩次查詢都是剛剛掃描了幾百條資料就找到了所需的結果。
所以,若執行計劃中有where,一定要小心全表掃描!
小問題:若是把FIS_BACKUP索引去掉,直接用FID主鍵索引,會有什麼問題呢?????下篇文章繼續。。。
qq:475804848
相關推薦
記錄一次索引優化經歷
表結構如下: 主要用到FIS_BACKUP、FID和FSTATUS幾個欄位做查詢。 索引如下: 整張表,前半部分資料FIS_BACKUP都是1,後半部分資料FIS_BACKUP都是0,共2000w多條資料 查詢語句如下: SELEC
記錄一次效能優化的過程
效能優化: 一、背景 查詢介面,一個複雜條件查詢,符合條件的記錄有17W,查詢首頁的100條,postman測試介面耗時在1.6-2秒不等。 (重複查詢同一個條件,mongodb會將符合條件的記錄載入到記憶體,因此後面查詢會快一些,然後趨於一個比較穩定 的值1.6s 附近) 1
記錄一次gdb debug經歷
目錄 問題描述 檢視core檔案 使用gdb檢視core檔案 總結 問題描述 今天在寫程式碼時,執行時奔潰了。segment fault,而且是在程式退出main()函式後,才報
記錄一次mysql有索引但是沒有用到的經歷
前提:公司測試人員需要連線資料庫取資料,但是併發量高的時候會報等待獲取連線超時,所以經理讓我幫忙處理下,首先想到增大超時等待時間,改為60秒,300百左右併發是沒有問題的,但是提高到500以上時又報辣個錯誤,就在考慮應該優化下查詢sql,增加索引使查詢時間縮短來減少等待時間。 兩個sql很簡
記錄一次經歷的數據庫從單庫到分庫分表的過程
人力 per 靠譜 img center 沒有 tdd 推出 數據 前言 目前所在的的項目組,由於項目正在處於一個業務爆發期,每天數據的增長量已經給我們數據庫乃至系統造成了很多不確定的因數,前期依靠優化業務和SQL等方式暫時還能夠支撐住。但是最近發現某些表數據達到50
多線程系列七:記錄一次學習項目性能優化的過程及心得
安全問題 ota except dex 等等 exception family print 單個 一、項目背景和問題 有一個自適應的考試學習系統,對學員的學習要求經常考試進行檢查,學員的成績出來以後,老師會要求系統根據每個學員的考卷上錯誤的題目從容量為10萬左右的題庫中抽取
記錄一次文件過多的刪除經歷
刪除文件 公司使用的開發語言是PHP,靜態頁面緩存機制是緩存在磁盤的某個目錄下,由於沒有做定時任務對緩存文件進行刪除,於是久而久之,緩存目錄的文件達到了32萬個,此時用rm -rf刪除會報錯。提示-bash: /bin/rm: Argument list too
記錄一次生產環境hadoop集群優化以及pid文件缺失處理
hadoop hbase pid 優化一、優化準備優化需要根據實際情況綜合分析1、關閉系統swap分區(如果未關閉的話)在Hadoop中,如果使用系統默認設置,會導致swap分區被頻繁使用,集群會不斷發出警告。對於每個作業處理的數據量和每個Task中用到的各種緩沖,用戶都是完全可控的。echo "v
簡單的記錄一次簡單的優化
原因 循環 返回 嘗試 場景 業務場景 pre 這才 查看 #大致的業務場景 從一個報警表中查詢數據,報警表中有很多其他表的外鍵,比如報警的設備信息信息,報警的組織信息,報警的原件信息等等,也就是說查詢報警信息的時候可以查出來很多相關的信息,需求是參數傳一個組織id,要求查
記錄一次mybatis查詢返回為空資料庫卻能查詢到資料的經歷
昨晚上測試人員給發了一條測試資料,說是根據這條資料介面返回資訊為空。之後根據給的資訊去資料庫查詢了下,明明是有資料的。但是用mybatis就是查詢不出來。奇了怪了,自己測試的資料都能查詢出來,為何這條資料就是沒有那?查詢條件就是 主鍵+狀態值而已,沒有多餘的查詢。 &
關於js物件中兩個函式互相呼叫,其中一個為定時器宣告,定時器迴圈報錯問題(記錄一次嘗試新寫法的報錯經歷)附帶無縫輪播圖程式碼
先上之前的錯誤程式碼吧,注意計時器這個方法(是想把之前寫的的輪播圖演示重構一下) var obj = { sleepTime: 2000,//輪播延時 cont: 0,//第幾張 origin: document.getElementsByClassName('main-
記錄一次從MinGw轉到MSVC編譯器的錯誤經歷
MinGW和MSVC相容度並不那麼好,由於中文的問題,sa一直使用的是MinGW來進行編譯,但說實話,在windows上MinGW編譯出來的程式在體積和速度上和MSVC還是有點差距的,因此,sa最終版打算使用msvc編譯器。 於是,前幾天用Qt5.9 MSVC2015版進行了一下編譯結果
記錄一次vue-cli專案上線到阿里雲並配置Nginx伺服器的經歷
首先,買一臺雲伺服器是必要的,我使用的是阿里雲伺服器CentOS 7.4 64位作業系統。 在整個vue-cli專案上線過程中,我遇到了很多問題。不過,最終圓滿解決了,因此在這裡記錄一下。 遇到的問題: 雲伺服器連線 vue專案打包上線 nginx安裝配置 雲
記錄一次由屁股決定研發的狗血經歷
大將無能,累死三軍。一個專案的成敗,是整個團隊努力的結果。今天總結的這些經驗教訓,如果對後來人有哪怕一丁點的經驗教訓,那也值了。 2017年的春天,我們團隊接到一個任務,需要開發一套智慧家居產品,產品的開發週期初定為三個月。產品的架構其實不復雜,都是一些現成的技術,應該很快可以拿下。 事實證明,碼農的
記錄一次查詢log的經歷
一大早發現生產資料庫的基礎資料被刪除。 由於每天都做了差異備份,而且是基礎資料,這樣資料就不會擔心找不回來。 首先通過每天的差異本分檔案進行檢視資料丟失的大概時間,查到資料丟失是在17晚上備份過後18丟失的。 然後找18號的資料庫執行記錄 貼上語句: SELECT ST.text AS '執
關於js物件中兩個函式互相呼叫,其中一個為定時器宣告,定時器迴圈報錯問題(記錄一次嘗試新寫法的報錯經歷)
先上之前的錯誤程式碼吧(是想把之前寫的的輪播圖demo重構一下) var obj = { sleepTime: 2000,//輪播延時 cont: 0,//第幾張 origin: document.getElementsByClassName('ma
【記錄一次坑經歷】axios使用x-www-form-urlencoded 伺服器報400(錯誤的請求。 )(後端.Net MVC5 WebApi OAuth,前端Electron-Vue)
首先放上原始碼 electron-vue axios 註冊 axios.defaults.baseURL = 'http://localhost:8888/' axios.defaults.headers.post['Content-Type'] = 'applicatio
記錄一次資料量巨大的表索引損壞處理
簡介:索引損壞的表XSDTM129.RT是個歷史資料表,該表資料是在實時插入的,所以表內資料量巨大,多達6億多條,而由於索引損壞,無法先進行資料的刪除,而傳統的刪索引—重建索引的時間消耗非常大,所以考慮能否用重建RT表來代替原表,並把需要所需資料匯入新RT表,刪除舊錶的方式
一次sql優化的記錄
select a.band,a.name from radio as a where exists ( select radio.id from radio,(select radio_nj.radio_id as radio_id from user,radio_nj where user.rol
記錄一次刪除/建立APEX的Workspace經歷
時間過去的稍微有些久遠,無法記得當時是如何操作的了。這裡只對重點內容進行記述。 命令列刪除Workspace 官方參考文件 實驗的時候建立很多Workspace,所以想要一次性全部刪除,具體的刪除操作可以參考文件: http://docs.oracle.com/cd/E17