
基於深度學習的目標檢測演算法概述
摘要
目標檢測是計算機視覺的一個重要分支,其目的是準確判斷影象或視訊中的物體類別並定位。傳統的目標檢測方法包括這三個步驟:區域選擇、提取特徵和分類迴歸,這樣的檢測方法存在很多問題,現已難以滿足檢測對效能和速度的要求。基於深度學習的目標檢測方法摒棄了傳統檢測演算法適應性不高、對背景模型的更新要求高、提取特徵魯棒性差和檢測的實時性差等缺點,使檢測模型在精度和速度方面都有了很大的提升。
目前,基於深度學習的目標檢測方法主要分為兩大類:一是基於Region Proposal的 two stage目標檢測演算法,二是基於迴歸問題的one stage目標檢測演算法。第一類是先由特定演算法生成一系列樣本的候選框,再通過卷積神經網路對樣本進行分類,最後還要進行邊界框的位置精修,代表作主要有R-CNN[1-4]等一系列的檢測演算法;第二類則不用產生候選框,直接將目標邊框定位的問題轉化為迴歸問題處理,直接對預測的目標物體進行迴歸,經典的演算法有SSD[5]和YOLO[6-8]系列等;還有一類方法是新提出的對one stage和two stage方法進行改進,得到的其升級版的方法,比如Faster R-CNN[4]、YOLO[6-8]、SSD[5] 等經典論文的升級版本,包括Cascade R-CNN[12],DSSD[29]等演算法,但根據網路結構,它們同樣可以歸到前兩類中。正是由於one stage和two stage兩種方法的差異,其在效能上也有不同,前者在檢測準確率和定位精度上佔優,而後者在檢測速度上更具有優勢。到現在,目標檢測演算法仍在進一步更新和演化,許多新的更有效的演算法也在不斷問世。
1引言
目標檢測是為了從影象或視訊中識別和定位出我們需要的目標物體,是後續影象理解和應用的基礎任務。檢測器效能的好壞將直接影響後續的目標跟蹤、動作識別以及行為理解等中高層任務的效能。傳統的目標檢測演算法的發展早在2010年就停滯不前,直到2013年將卷積網路引入到目標檢測中,才突破了傳統檢測瓶頸,掀起了深度學習目標檢測的熱潮。從此以後,基於深度學習的目標檢測快速發展。
基於深度學習的目標檢測方法,是計算機視覺檢測領域的一個重大創新。這
些創新演算法都是把傳統的計算機視覺領域和深度學習合二為一,並取得了良好的檢測效果。準確性和實時性是衡量目標檢測系統性能的重要指標,也是一對矛盾體,如何更好地平衡它們一直是目標檢測演算法研究的一個重要方向。隨著深度學習的不斷髮展,檢測的精度和實效性也逐漸提升。因此,基於深度學習的目標檢測演算法得到了廣大研究者的關注,一躍成為機器學習領域的熱點話題之一。
目標檢測的難點在於:目標形態各異、大小不一,影象的任意位置都可能含有目標,在軍事和航空領域,對於弱小目標和模糊目標的檢測也是一個難點。目標檢測使用矩形框來定位目標,由於目標物體的形態和大小的差異,導致矩形框也具有不同的寬高比,此時,若採用早期的滑動視窗與影象縮放相結合的方法,檢測成本會很高,同時檢測效率也極低。
2013年Girshick等人提出了R-CNN[1]檢測演算法,在基於深度學習的目標檢測領域取得了重大突破,藉助卷積神經網路良好的特徵提取和分類效能,並通過Region Proposal方法實現目標檢測問題的轉化,為後來的深度學習目標檢測方法奠定了基礎,但此方法容易導致影象資訊丟失,資源浪費[1]。2016年,R-CNN系列的最高代表作Faster R-CNN[4]實現了端到端的檢測,檢測精度可以說是達到了最優,但在檢測速度仍有很大的改進空間[4]。這種two-stage的檢測器可以通過減少proposal的數量或降低輸入影象的解析度等方式達到提速,但是速度並沒有得到質的提升。同年,出現了YOLO和SSD等更快速的檢測演算法,將目標檢測轉化為迴歸問題,真正實現了端到端的實時檢測,但精度不如Faster R-CNN高。後來,2017和2018年,作者又在YOLO的基礎上進行改進,形成了第二版和第三版的YOLO,YOLOv3可以達到驚人的檢測效果。同時,也出現了更多高效能的檢測演算法,例如Refine-Det[9] 、Relation Net[10]和RFB-Net[11]等,都取得了更好的檢測效果。近兩年新提出的檢測演算法有很多都是在先前的演算法上進行改進得到的,同樣取得了不錯的檢測效果。
今年CVPR上關於目標檢測的論文數量較往年增加了許多,說明這一研究領域的熱度不減反增,目標檢測演算法正在急速發展。本文在第二章和第三章介紹了2013年至今基於深度學習的目標檢測方法的發展歷程以及幾種經典的檢測演算法,詳細描述了各演算法的重要思想和創新點,並指出了其缺陷以及在以後出現的演算法中關於此問題的改進思路。
2 基於Region Proposal的 two stage檢測演算法
2.1 R-CNN
R-CNN演算法是Region Proposal + CNN這一框架的開山之作,為以後基於CNN的檢測演算法奠定了基礎。該演算法首先採用Selective Search演算法,對一張多目標影象進行分割和聚類,得到大量的目標候選框,然後將候選框裁剪、放縮至統一尺寸,再使用卷積網路對候選框進行特徵提取,提取到的CNN特徵輸入到每一類的SVM進行分類,判別是否屬於該類,最後還要進行邊界框的迴歸,即用線性迴歸微調邊界框的位置和大小[1]。R-CNN的主要缺點是重複計算,需要對每個候選框都進行特徵提取,因此計算量很大,時間消耗多。而且,全連線層需要保證輸入的候選框大小統一,所以網路輸入的一系列圖片需要裁剪和放縮至統一尺寸,這樣可能導致影象畸變,影響檢測效果,下面的SPP-net[2]演算法為這些問題提供瞭解決思路。
2.2 SPP-net
為了解決R-CNN中對候選框進行裁剪、縮放從而影響檢測效果的問題,何凱明提出了SPP-Net,即不進行裁剪、縮放,並且在R-CNN最後一個卷積層後,接入了金字塔池化層( spatial Pyramid Pooling, SPP),使用這種方式,可以讓網路輸入任意的圖片,而且還會生成固定大小的輸出[2]。還有一點,SPP-Net是把整張待檢測的圖片,輸入CNN中,進行一次性特徵提取,得到feature maps,然後在feature maps中找到各個候選框對應的區域,再對各個候選框採用金字塔空間池化,提取出固定長度的特徵向量,所以,檢測速度也會大大提升。
2.3 Fast R-CNN
首先,該演算法借鑑了SPP-net中金字塔池化的思想,對每個候選框所對應的feature map經過一個ROI pooling layer 形成一個固定長度的feature map,可以說是屬於簡化版的金字塔池化(SPP)。其次,採用了多工訓練的模式,將回歸也加入到網路中,使分類和迴歸同時進行訓練,減少硬體快取,並且用soft-max替代SVM進行分類[3]。但該演算法仍然使用Selective Search方法進行候選框的提取,複雜耗時。
2.4 Faster R-CNN
Faster R-CNN可以簡單地看作“區域生成網路RPNs + Fast R-CNN”的系統,該演算法最大的創新就是提出了“區域生成網路(RPN)”,用其代替Fast R-CNN中的Selective Search方法進行候選框提取[4]。RPN的核心思想是使用卷積神經網路直接產生Region Proposal,本質就是滑動視窗。其次,使用四步交替訓練法進行RPN和Fast R-CNN的訓練,RPN與Fast-R-CNN共享卷積層,使提取候選框的成本降為零。
2.5 Cascade R-CNN
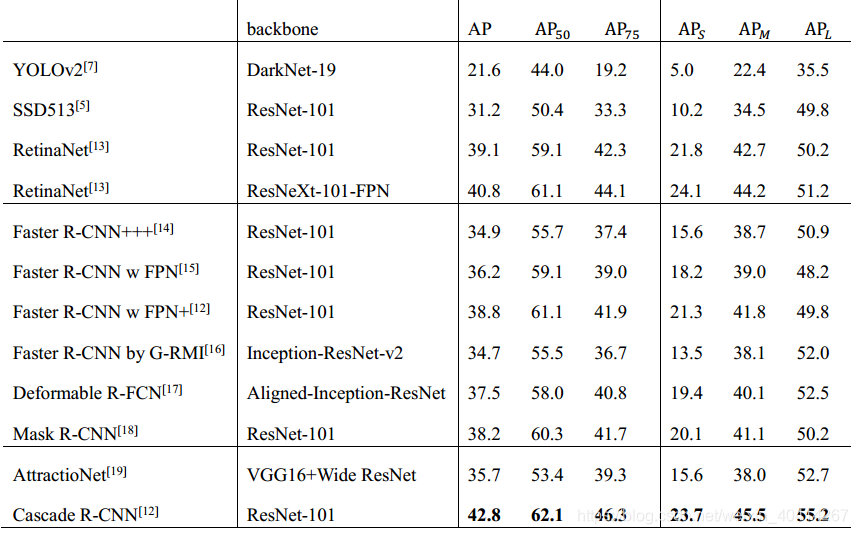
該演算法是針對的是檢測問題中的IoU閾值選取問題[12]。在classification中,每個proposal會根據一個指定的IoU值判斷為正樣本或負樣本,在bounding-box regression中,每個被標記為正樣本的bounding-box會向其ground-truth方向迴歸。閾值選取越高確實越容易得到高質量的樣本,但是一味選取高閾值會引發兩個問題,一是正樣本數量減少引發的過擬合,二是在訓練和測試使用不一樣的閾值很容易導致錯誤匹配,為了解決這些問題,作者提出了Cascade R-CNN stages,用一個stage的輸出去訓練下一個stage,並且每個stage選用不同的閾值。這樣可以保證每一級的header都可以得到足夠多的正樣本,且正樣本的質量可以逐級提升。在訓練和測試時,這個操作也都保持一致。在測試中,使用多個header輸出的均值作為這個proposal最終的分數,這樣檢測效能會有進一步的提升。表1中為Cascade R-CNN與其他演算法的效能比較[12]。
表1 Cascade R-CNN與其他演算法在COCO資料集上的效能比較
3 基於迴歸問題的one stage檢測演算法
3.1 YOLOv1
Redmon等人提出的YOLO演算法,是將目標檢測作為一個迴歸問題來解決,輸入含多個目標的原始影象,便能得到其中物體的位置邊框和其所屬的類別及其相應的置信度[6]。YOLO基於Google-Net影象分類模型,是一個可以一次性預測多個位置和類別的卷積神經網路,真正意義上實現了端到端的目標檢測,檢測速度快,但精度相比Faster R-CNN略有下降。
3.2 YOLOv2&YOLO9000
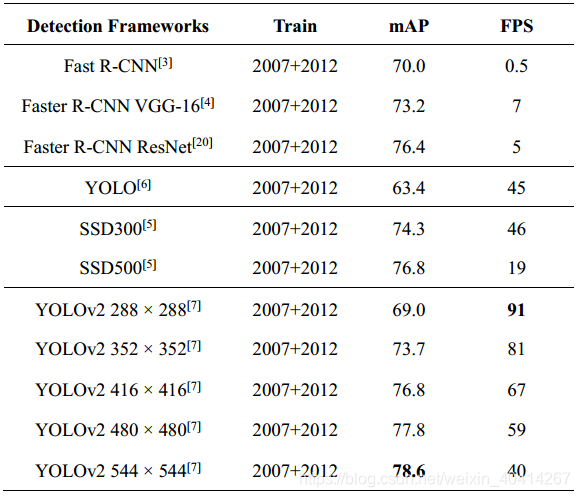
YOLO的第二個版本YOLOv2,在v1的基礎上做了很多的優化。YOLOv1在準確度,速度,容錯率上都有所欠缺,作者採用了一系列的方法優化了YOLOv1的模型結構,產生了YOLOv2[7]。首先,作者在所有卷積層應用了Batch Normalization,Batch Normalization可以提高模型收斂速度,減少過擬合,使map提升了2%;其次,YOLOv1接受影象尺寸為224×224, 在YOLOv2中,作者採用448×448解析度的ImageNet資料微調使網路適應高解析度輸入,高解析度輸入使結果提升了4%的mAP;除此之外,去掉了YOLO的全連線層,採用固定框(anchor boxes)來預測bounding boxes,去除了一個pooling層來提高卷積層輸出解析度,修改網路輸入尺寸,由448×448改為416×416,使得特徵圖只有一箇中心,雖然略降低了map,卻大大提升了召回率;作者還使用多尺度訓練,使模型對不同尺寸的影象具有魯棒性。表2中列舉了YOLOv2和其他檢測框架在PASCAL VOC 2007上的測試效能,可以看出,在高解析度下,YOLOv2在VOC 2007上具有78.6的 mAP,仍然可以達到實時檢測[7]。
YOLO9000通過結合分類和檢測資料集,使得訓練得到的模型可以檢測約9000類物體,網路結構和YOLOv2類似,區別是每個單元格只有3個Anchor Boxes。作者採用word-tree的方法,綜合ImageNet資料集和COCO資料集訓練YOLO9000,使之可以實時檢測超過9000種物品[7]。
表2 各檢測框架在PASCAL VOC 2007上的測試效能比較
3.3 SSD
SSD演算法可直接預測目標的座標和類別,沒有生成候選框的過程。網路直接在VGG16網路的基礎上進行修改得到。SSD首先使用2個卷積層替換VGG16網路的最後2個全連線層,然後在VGG網路的後面增加4個卷積層[5]。為了檢測目標,SSD分別使用兩個卷積核為3×3的卷積層對其中5個卷積層的輸出進行卷積。其中一個卷積層輸出類別作為類別預測結果,另一個卷積層輸出包含迴歸時的目標位置作為位置預測結果[5]。SSD的核心是結合迴歸思想使用一系列檢測器來預測目標的類別和位置。主要從兩個方面實現快速高檢測精度的目標檢測效果,一是對不同尺寸的卷積層輸出進行迴歸,二是通過增加檢測器的寬高比來檢測不同形狀的目標。
3.4 RetinaNet
Two-stage的檢測器精度高,速度慢;One-stage的檢測器速度快,精度低。作者希望one-stage detector可以達到two-stage detector的準確率,同時不影響原有的速度[13]。論文找出了One-stage檢測器精度低的原因,並提出瞭解決辦法。One-stage檢測器精度低,究其原因,就是正負樣本不均衡,只有少數樣本包含目標物體,絕大多數樣本都是背景。負樣本多是容易分類的,其數量過多,佔總loss的大部分,這樣會掩蓋那些少數真正含有目標資訊的正樣本,模型的優化方向會向佔loss比重大的方向更新,這並不是我們所希望的。作者提出一種新的損失函式focal loss,降低易分類樣本的權重,使模型的更新方向向少量有用樣本的方向靠攏[13]。其檢測效能見表1。
3.5 Refine-Det
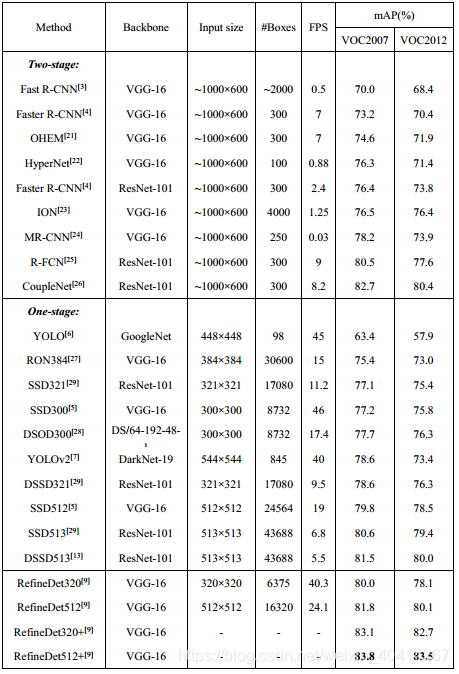
Refine-Det方法,同行繼承了two-stage和one-stage兩者的優點。網路結構由兩個模組構成,一個是anchor細化模組(ARM),另一個是目標檢測模組(ODM)。ARM模組用來減小分類器的搜尋空間,粗略地描述anchor的位置和大小。通過連線模組(TCB)將ARM中的特徵傳輸給ODM模組,以獲取更加準確的目標位置和大小[9]。簡單地說,就是將原來two-stage的序列結構轉化成了並行。RefineDet與其他演算法在VOC資料集上的效能測試見表3[9]。
表3 RefineDet與其他演算法在VOC資料集上的效能測試
3.6 YOLOv3
相對於YOLO v2,YOLOv3的檢測精度大大提升,而檢測速度並沒有下降。改進的地方有:v3替換了v2的soft-max loss,改成了logistic loss;v2作者用了5個anchor,v3用了9個anchor,提高了IOU;其次,YOLO v3採用上取樣和融合的做法,使用檢測層在三種不同尺寸的特徵圖上進行檢測,分別具有stride=32,16,8,這意味著,在輸入416 x 416的情況下,我們使用13 x 13,26 x 26和52 x 52的比例進行檢測,即融合了3個尺度(1313、2626和52*52),在多個尺度的融合特徵圖上分別獨立做檢測,對小目標的檢測效果明顯提升;最後,由於卷積層數量明顯增多,v2的darknet-19變成了v3的darknet-53[8]。表4中列出了YOLOv3和其他一些演算法比較的mAP值和執行時間,可以看出,YOLOv3執行速度明顯比其他演算法快很多[8]。
表4 YOLOv3與其他檢測框架在COCO資料集上的測試效能比較

3.7 Relation Networks
該演算法引入了物體之間的關聯資訊,在神經網路中對物體間的relation進行建模。提出了一種relation module,可以在以往常見的物體特徵中融合進物體之間的關聯性資訊,同時不改變特徵的維數,能很好地嵌入目前各種檢測框架,提高效能[10]。同時,提出了一種特別的代替NMS的去重模組,可以避免NMS需要手動設定引數的問題[10]。
3.8 RFB-Net
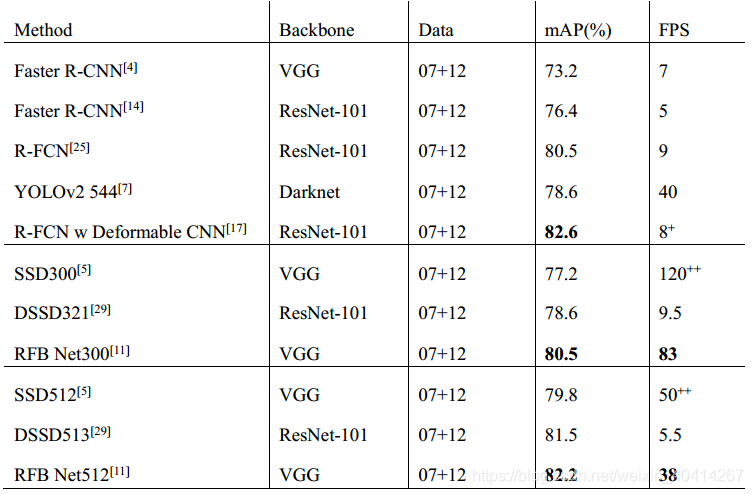
RFB-Net檢測器利用多尺度one-stage檢測框架SSD,在其中嵌入RFB模組,使得輕量級主幹SSD網路也能更快更準[11]。原始SSD,基礎主幹網路後面接一系列重疊的卷積層,得到一系列空間解析度減小而感受野增大的特徵圖。RFB-Net保持了這種結構,並做了些改進,用RFB模組替換了原來的L2歸一化,從前面卷積層獲取包含小目標的底層特徵圖[11]。RFB-Net與各演算法效能比較見表5[11]。
表5 RFB-Net與各演算法在VOC2007資料集上的效能比較
4 總結和展望
本文詳細對基於深度學習的目標檢測演算法進行了較為全面的梳理,總結了各演算法相比於先前演算法的改進策略,及其本身的創新點及不足之處,對於目標檢測領域的研究人員具有重要的參考價值。
目標檢測應用範圍非常廣,例如,在行人檢測、車輛檢測、衛星遙感對地監測、無人駕駛、交通安全等領域。目前,基於深度學習的目標檢測已經取得了很多重要成果,但同時也面臨著諸多挑戰,例如目標背景的多樣性,動態場景的不斷變化,對檢測系統時效性和穩定性的要求也在逐漸提高。無論是在檢測演算法方面,還是硬體加速方面,目標檢測都存在著許多難點和挑戰,等待著我們去進一步突破。
5 參考文獻
[1] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for
accurate object detection and semantic segmentation,” in IEEE Conference on
Computer Vision and Pattern Recognition (CVPR), 2014.
[2] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in European Conference on Computer Vision (ECCV), 2014.
[3] R. B. Girshick. Fast R-CNN. CoRR, abs/1504.08083, 2015.
[4] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object
detection with region proposal networks,” in Neural Information Processing
Systems (NIPS), 2015.
[5] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg. SSD:
single shot multibox detector. In ECCV, pages 21–37, 2016.
[6] J. Redmon, S. K. Divvala, R. B. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, pages 779–788, 2016.
[7] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In Computer Vision and Pattern Recognition (CVPR), 2017 IEEE Conference on, pages 6517–6525. IEEE, 2017.
[8] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv, 2018.
[9] Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, Stan Z. Li. “Single-Shot Refinement Neural Network for Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai and Yichen Wei, “Relation Networks for Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[11] Songtao Liu, Di Huang, and Yunhong Wang, “Receptive Field Block Net for Accurate and Fast Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[12] Zhaowei Cai,and Nuno Vasconcelos,“Cascade R-CNN: Delving into High Quality Object Detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[13] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar. Focal loss for dense object detection. In ICCV, 2017.
[14] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
[15] T.-Y. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
[16] J. Huang, V. Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, and K. Murphy. Speed/accuracy trade-offs for modern convolutional object detectors. CoRR, abs/1611.10012, 2016.
[17] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017.
[18] K. He, G. Gkioxari, P. Doll´ar, and R. Girshick. Mask r-cnn. In ICCV, 2017.
[19] S. Gidaris and N. Komodakis. Attend refine repeat: Active box proposal generation via in-out localization. In BMVC, 2016.
[20] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
[21] A. Shrivastava, A. Gupta, and R. B. Girshick. Training region-based object detectors with online hard example mining. In CVPR, pages 761–769, 2016.
[22] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. In CVPR, pages 845–853, 2016.
[23] S. Bell, C. L. Zitnick, K. Bala, and R. B. Girshick. Insideoutside net: Detecting objects in context with skip pooling and recurrent neural networks. In CVPR, pages 2874–2883, 2016.
[24] S. Gidaris and N. Komodakis. Object detection via a multiregion and semantic segmentation-aware CNN model. In ICCV, pages 1134–1142, 2015.
[25] J. Dai, Y. Li, K. He, and J. Sun. R-FCN: object detection via region-based fully convolutional networks. In NIPS, pages 379–387, 2016.
[26] Y. Zhu, C. Zhao, J. Wang, X. Zhao, Y. Wu, and H. Lu. Couplenet: Coupling global structure with local parts for object detection. In ICCV, 2017.
[27] T. Kong, F. Sun, A. Yao, H. Liu, M. Lu, and Y. Chen. RON: reverse connection with objectness prior networks for object detection. In CVPR, 2017.
[28] Z. Shen, Z. Liu, J. Li, Y. Jiang, Y. Chen, and X. Xue. DSOD: learning deeply supervised object detectors from scratch. In ICCV, 2017.
[29] C. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg. DSSD : Deconvolutional single shot detector. CoRR, abs/1701.06659, 2017.
如有錯誤,歡迎指正~~