
深度學習-目標檢測資料集以及評估指標
資料集和效能指標
目標檢測常用的資料集包括PASCAL VOC,ImageNet,MS COCO等資料集,這些資料集用於研究者測試演算法效能或者用於競賽。目標檢測的效能指標要考慮檢測物體的位置以及預測類別的準確性,下面我們會說到一些常用的效能評估指標。
資料集
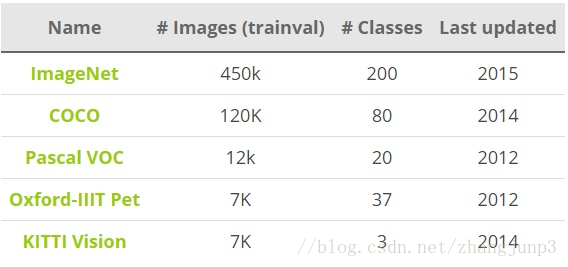
PASCAL VOC(The PASCAL Visual Object Classification)是目標檢測,分類,分割等領域一個有名的資料集。從2005到2012年,共舉辦了8個不同的挑戰賽。PASCAL VOC包含約10,000張帶有邊界框的圖片用於訓練和驗證。但是,PASCAL VOC資料集僅包含20個類別,因此其被看成目標檢測問題的一個基準資料集。
ImageNet在2013年放出了包含邊界框的目標檢測資料集。訓練資料集包含500,000張圖片,屬於200類物體。由於資料集太大,訓練所需計算量很大,因而很少使用。同時,由於類別數也比較多,目標檢測的難度也相當大。2014 ImageNet資料集和2012 PASCAL VOC資料集的對比在這裡。
另外一個有名的資料集是Microsoft公司(見T.-Y.Lin and al. 2015)建立的MS COCO(Common Objects in COntext)資料集。這個資料集用於多種競賽:影象標題生成,目標檢測,關鍵點檢測和物體分割。對於目標檢測任務,COCO共包含80個類別,每年大賽的訓練和驗證資料集包含超過120,000個圖片,超過40,000個測試圖片。測試集最近被劃分為兩類,一類是test-dev資料集用於研究者,一類是test-challenge資料集用於競賽者。測試集的標籤資料沒有公開,以避免在測試集上過擬合。在

效能指標
目標檢測問題同時是一個迴歸和分類問題。首先,為了評估定位精度,需要計算IoU(Intersection over Union,介於0到1之間),其表示預測框與真實框(ground-truth box)之間的重疊程度。IoU越高,預測框的位置越準確。因而,在評估預測框時,通常會設定一個IoU閾值(如0.5),只有當預測框與真實框的IoU值大於這個閾值時,該預測框才被認定為真陽性(True Positive, TP),反之就是假陽性(False Positive,FP)。
對於二分類,AP(Average Precision)是一個重要的指標,這是資訊檢索中的一個概念,基於precision-recall曲線計算出來,詳情見這裡。對於目標檢測,首先要單獨計算各個類別的AP值,這是評估檢測效果的重要指標。取各個類別的AP的平均值,就得到一個綜合指標mAP(Mean Average Precision),mAP指標可以避免某些類別比較極端化而弱化其它類別的效能這個問題。
對於目標檢測,mAP一般在某個固定的IoU上計算,但是不同的IoU值會改變TP和FP的比例,從而造成mAP的差異。COCO資料集提供了官方的評估指標,它的AP是計算一系列IoU下(0.5:0.05:0.9,見說明)AP的平均值,這樣可以消除IoU導致的AP波動。其實對於PASCAL VOC資料集也是這樣,Facebook的Detectron上的有比較清晰的實現。
除了檢測準確度,目標檢測演算法的另外一個重要效能指標是速度,只有速度快,才能實現實時檢測,這對一些應用場景極其重要。評估速度的常用指標是每秒幀率(Frame Per Second,FPS),即每秒內可以處理的圖片數量。當然要對比FPS,你需要在同一硬體上進行。另外也可以使用處理一張圖片所需時間來評估檢測速度,時間越短,速度越快。
如果不太清楚P-R曲線、AP計算以及mAP計算可參考下一篇博文,https://mp.csdn.net/postedit/81051150
轉自:https://blog.csdn.net/zhangjunp3/article/details/79651384