Hadoop核心架構體系(HDFS+MapReduce+Hbase+Hive+Yarn)
一、Hadoop基本概念
1、什麼是Hadoop
專業版解釋
Hadoop是Apache 公司開發的一款可靠的、可擴充套件性的、分散式計算的開源軟體。以Hadoop分散式檔案系統(HDFS)和分散式運算程式設計框架(MapReduce)為核心,允許在叢集伺服器上使用簡單的程式設計模型對大資料集進行分散式處理。Hadoop被設計成能夠從單臺伺服器擴充套件到數以千計的伺服器,每臺伺服器都有本地的計算和儲存資源。Hadoop的高可用性並不依賴硬體,其程式碼庫自身就能在應用層偵測並處理硬體故障,因此能基於伺服器叢集提供高可用性的服務。通俗版解釋
Hadoop是一個開源的框架,可編寫和執行分散式應用處理大規模資料,是專為離線和大規模資料分析而設計的。以分散式檔案系統(HDFS)和分散式運算程式設計框架(MapReduce)為核心,其中HDFS實現將檔案分散式的儲存在多臺伺服器上,MapReduce則實現了在多臺機器上分散式的並行運算。
2、Hadoop用來做什麼?
2.1 儲存了大規模的資料,我們要幹什麼呢,當然是分析資料中的價值,Hadoop+MapReduce用於離線大資料的分析挖掘,比如:電商資料的分析挖掘、社交資料的分析挖掘,企業客戶關係的分析挖掘,最終的目標就是BI了,提高企業運作效率,實現精準營銷,各個垂直領域的推薦系統,發現潛在客戶等等。總結了Hadoop的應用場景如下:
- 大資料量儲存:分散式儲存(各種雲盤,百度,360~還有云平臺均有hadoop應用)
- 日誌處理: Hadoop擅長這個
- 海量計算: 平行計算
- ETL:資料抽取到Oracle、Mysql、DB2、Mongdb及主流資料庫
- 使用HBase做資料分析: 用擴充套件性應對大量讀寫操作—Facebook構建了基於HBase的實時資料分析系統
- 機器學習: 比如Apache Mahout專案(Apache Mahout簡介 常見領域:協作篩選、叢集、歸類)
- 搜尋引擎:hadoop + lucene實現
- 資料探勘:目前比較流行的廣告推薦
- 大量地從檔案中順序讀。HDFS對順序讀進行了優化,代價是對於隨機的訪問負載較高。
- 使用者行為特徵建模
- 個性化廣告推薦
- 智慧儀器推薦
2.2 例如,Facebook公司運行了世界第二大Hadoop叢集,資料超過2PB,每天加入10TB資料,2400個核心,9TB記憶體,大部分時間硬體滿負荷執行。如使用者數,網頁瀏覽次數,網站訪問時間增常情況,廣告活動效果資料,計算使用者喜歡人和應用程式。通過分析歷史資料,以設計和改進產品,以及管理。
二、Hadoop核心架構
HDFS和MapReduce是Hadoop的兩大核心,除此之外Hbase、Hive這兩個核心工具也隨著Hadoop發展變得越來越重要。同時,在Hadoop2.0後,在HDFS的基礎上增加了YARN,是一個資源管理框架,在YARN上既可以放MapReduce,也可以放置其他的計算資源,主要是管理資源的,如CPU,硬碟,記憶體,網路等。
1、HDFS的體系架構
概念
Hadoop分散式檔案系統(HDFS)被設計成適合執行在通用硬體上的分散式檔案系統。HDFS是一個高度容錯性的系統,能提供高吞吐量的資料訪問,非常適合大規模資料集上的應用。
資料塊(block):大檔案會被分割成多個block進行儲存,block大小預設為64MB。每一個block會在多個datanode上儲存多份副本,預設是3份。
NameNode:namenode負責管理檔案目錄、檔案和block的對應關係以及block和datanode的對應關係。
DataNode:datanode就負責儲存了,當然大部分容錯機制都是在datanode上實現的。HDFS的工作機制
(1)客戶把一個檔案存入HDFS,其實HDFS會把這個檔案切塊後,分散儲存在N臺linux機器系統中(負責儲存檔案塊的角色:data node)<準確來說:切塊的行為是由客戶端決定的>
(2)一旦檔案被切塊儲存,那麼,HDFS中就必須有一個機制,來記錄使用者的每一個檔案的切塊資訊,及每一塊的具體儲存機器(負責記錄塊資訊的角色是:name node)
(3)為了保證資料的安全性,HDFS可以將每一個檔案塊在叢集中存放多個副本(到底存幾個副本,是由當時存入該檔案的客戶端指定的)
綜述:一個HDFS系統,由一臺運行了namenode的伺服器,和N臺運行了datanode的伺服器組成!
總結:一個HDFS系統,由一臺運行了namenode的伺服器,和N臺運行了datanode的伺服器組成!
2、MapReduce體系架構
- 概念
MapReduce是Goodle公司的核心計算模型,它執行在大規模叢集的平行計算過程中,並抽象為兩個函式:map和reduce。一個MapReduce作業,會把輸入的資料切分為若干塊,先由map任務(task)一併行的方式處理它們,框架會先對map的輸出進行排序,把所有具有相同的key值的value結合在一起,然後輸入給reduce任務。接下來由reduce任務進行相應的平行計算。最後把計算的結果輸出到HDFS儲存起來。需要我們記憶的幾個點,mapreduce作業執行涉及4個獨立的實體:
(1)客戶端(client):編寫mapreduce程式,配置作業,提交作業,這就是程式設計師完成的工作;
(2)JobTracker:初始化作業,分配作業,與TaskTracker通訊,協調整個作業的執行;
(3)TaskTracker:保持與JobTracker的通訊,在分配的資料片段上執行Map或Reduce任務,TaskTracker和JobTracker的不同有個很重要的方面,就是在執行任務時候TaskTracker可以有n多個,JobTracker則只會有一個(JobTracker只能有一個就和hdfs裡namenode一樣存在單點故障,我會在後面的mapreduce的相關問題裡講到這個問題的)
(4)HDFS:儲存作業的資料、配置資訊等等,最後的結果也是儲存在hdfs上面 - MapReduce執行原理
圖片看不清可以右擊滑鼠,在新連線標籤中開啟圖片。接下來對上邊的MapReduce執行原理進行描述。
(1) 輸入分片(input split):在進行map計算之前,MapReduce會根據輸入檔案計算輸入分片,劃分輸入切片的任務是由job客戶端負責的,每個輸入分片針對一個map任務,輸入分片儲存的並非資料本身,而是一個分片長度和一個記錄資料的位置的陣列,輸入分片往往和HDFS的block(塊)關係很密切,假如我們設定HDFS的塊的大小是64MB,如果我們輸入有三個檔案,大小分別是3MB、65MB和127MB,那麼MapReduce會把3MB檔案分為一個輸入分片,65mb則是兩個輸入分片而127mb也是兩個輸入分片,換句話說我們如果在map計算前做輸入分片調整,例如合併小檔案,那麼就會有5個map任務(物件)將執行,而且每個map執行的資料大小不均,這個也是MapReduce優化計算的一個關鍵點。接下來,job客戶端會把掃描形成的這5個物件放入一個ArrayList中,並序列化成一個檔案job.split。最後由MRAppMaster來讀這個檔案,從而決定起動幾個yarn child(map task),從而決定好哪個yarn child讀哪一塊分片上的檔案。
(2) map task(yarn child)階段:map task先會去調TextInputFormat這個類,拿到一個LineRecordReader物件,通過這個物件反覆的去呼叫next()方法一行行的讀取檔案,從而產生一對對的kv值,k代表行起始偏移量,v代表行內容。然後,它會去呼叫我們自己實現的一個類,這個類是繼承自Mapper的類,裡面有一個map(k,v,context)方法,正好接受一個k,v和一個context,所以它會被next()反覆的去呼叫。同樣的,map()也會產生一個或一些kv值,然後context會呼叫write()方法,把kv序列化後快取起來(在記憶體裡)。快取起來後,也就是第四步shuffle階段要做的事。
(3)combiner階段:combiner階段是程式設計師可以選擇的,combiner其實也是一種reduce操作。Combiner是一個本地化的reduce操作,它是map運算的後續操作,主要是在map計算出中間檔案前做一個簡單的合併重複key值的操作,例如我們對檔案裡的單詞頻率做統計,map計算時候如果碰到一個hadoop的單詞就會記錄為1,但是這篇文章裡hadoop可能會出現n多次,那麼map輸出檔案冗餘就會很多,因此在reduce計算前對相同的key做一個合併操作,那麼檔案會變小,這樣就提高了寬頻的傳輸效率,畢竟hadoop計算力寬頻資源往往是計算的瓶頸也是最為寶貴的資源,但是combiner操作是有風險的,使用它的原則是combiner的輸入不會影響到reduce計算的最終輸入,例如:如果計算只是求總數,最大值,最小值可以使用combiner,但是做平均值計算使用combiner的話,最終的reduce計算結果就會出錯。
(4) shuffle階段:將map task生成的資料傳輸給reduce task的過程就是shuffle了,這個是MapReduce優化的重點地方。這裡我不講怎麼優化shuffle,講講shuffle階段的原理。shuffle一開始就是map階段做輸出操作,一般MapReduce計算的都是海量資料,map輸出時候不可能把所有檔案都放到記憶體操作,因此map寫入磁碟的過程十分的複雜,更何況map輸出時候要對結果進行排序,記憶體開銷是很大的,map在做輸出時候會在記憶體裡開啟一個環形記憶體緩衝區,這個緩衝區專門用來輸出的,預設大小是100MB,並且在配置檔案裡為這個緩衝區設定了一個閥值,預設是0.80(這個大小和閥值都是可以在配置檔案裡進行配置的),同時map還會為輸出操作啟動一個守護執行緒(Spiller),如果緩衝區的記憶體達到了80%時候,這個守護執行緒就會把內容寫到磁碟上,這個過程叫spill,另外的20%記憶體可以繼續寫入要寫進磁碟的資料,寫入磁碟和寫入記憶體操作是互不干擾的,如果快取區被撐滿了,那麼map就會阻塞寫入記憶體的操作,讓寫入磁碟操作完成後再繼續執行寫入記憶體操作。前面我講到過map task是一行行讀檔案的,所以讀檔案到寫入磁碟前還會有個分割槽和排序操作,這個是在寫入磁碟操作時候進行,不是在寫入記憶體時候進行的,如果我們定義了combiner函式,那麼排序前還會執行combiner操作。分割槽會呼叫一個叫Partitioner的元件,排序則會呼叫k上的CompareTo()來比大小。
每次spill操作也就是寫入磁碟操作時候就會寫一個檔案,這個檔案我們一般叫溢位檔案,溢位檔案裡區號小的在前面,同區中按k有序。等map輸出全部做完後,map會合並這些輸出檔案,這些檔案也是分割槽且有序的。合併的過程中還有一個很細節的點,就是合併後會產生一個分割槽索引檔案,用來指明每個分割槽的起始點以及它的偏移量。這個過程裡還會有一個Partitioner操作,對於這個操作很多人都很迷糊,其實Partitioner操作和map階段的輸入分片很像,一個Partitioner對應一個reduce作業,如果我們MapReduce操作只有一個reduce操作,那麼Partitioner就只有一個,如果我們有多個reduce操作,那麼Partitioner對應的就會有多個,Partitioner因此就是reduce的輸入分片,這個程式設計師可以程式設計控制,主要是根據實際key和value的值,根據實際業務型別或者為了更好的reduce負載均衡要求進行,這是提高reduce效率的一個關鍵所在。到了reduce階段就是合併map輸出檔案了,Partitioner會找到對應的map輸出檔案,然後進行復制操作,複製操作時reduce會開啟幾個複製執行緒,這些執行緒默認個數是5個,程式設計師也可以在配置檔案更改複製執行緒的個數,這個複製過程和map寫入磁碟過程類似,也有閥值和記憶體大小,閥值一樣可以在配置檔案裡配置,而記憶體大小是直接使用reduce的tasktracker的記憶體大小,複製時候reduce還會進行排序操作和合並檔案操作,這些操作完了就會進行reduce計算了。
(5) reduce task(yarn child)階段:map task階段完成後,它的程式就會退出,那麼reduce task要去哪裡拿到這些處理完的資料呢?答案是這些檔案會被納入到一個叫NodeManager的web程式的document目錄中,reduce task會通過web伺服器去把相應區號的檔案下載下來,然後將這些檔案合併。接下來,就是處理資料。首先,我們會自己實現一個類,這個類是繼承自Reducer的類,裡面有一個reduce(k,迭代器,context)方法。然後,通過反射構造出一個物件去呼叫reduce(),裡面的引數k和迭代器會分別去建立一個物件,每迭代一次就會按檔案裡的順序去讀一次,然後把讀出來的k傳給物件k,然後把v傳給物件values裡。這個過程也就是從磁碟上把二進位制資料讀取出來,然後反序列化把資料填入物件的一個過程。這迭代的過程中還會有一個分組比較器(GroupingComparator)去判斷迭代的k是否相同,不同則終止迭代。每迭代完一次,context.write()輸出一次聚合後的結果,這個聚合的結果會通過TextOutputFormat類裡的getRecordWriter()拿到一個RecordWriter物件,通過這個物件去調一個write(k,v)方法,將這些資料通過檔案的方式寫到HDFS裡。
3、Hive的體系架構
概念
Hive是基於Hadoop的一個數據倉庫工具(離線),可以將結構化的資料檔案對映為一張資料庫表,並提供類SQL查詢功能。為什麼使用Hive
直接使用hadoop所面臨的問題 :
人員學習成本太高
專案週期要求太短
MapReduce實現複雜查詢邏輯開發難度太大
使用Hive
操作介面採用類SQL語法,提供快速開發的能力。
避免了去寫MapReduce,減少開發人員的學習成本。
功能擴充套件很方便。
4、Hbase資料管理
概念
Hbase就是Hadoop database,可以提供資料的實時隨機讀寫。Hbase與Mysql、Oralce、db2、SQLserver等關係型資料庫不同,它是一個NoSQL資料庫(非關係型資料庫) 。
RowKey:是Byte array,是表中每條記錄的“主鍵”,方便快速查詢,Rowkey的設計非常重要。
Column Family:列族,擁有一個名稱(string),包含一個或者多個相關列
Column:屬於某一個columnfamily,familyName:columnName,每條記錄可動態新增
Version Number:型別為Long,預設值是系統時間戳,可由使用者自定義
Value(Cell):Byte arrayHbase的表模型與關係型資料庫的表模型不同:
Hbase的表沒有固定的欄位定義
Hbase的表中每行儲存的都是一些key-value對
Hbase的表中有列族的劃分,使用者可以指定將哪些kv插入哪個列族
Hbase的表在物理儲存上,是按照列族來分割的,不同列族的資料一定儲存在不同的檔案中
Hbase的表中的每一行都固定有一個行鍵,而且每一行的行鍵在表中不能重複
Hbase中的資料,包含行鍵,包含key,包含value,都是byte[ ]型別,hbase不負責為使用者維護資料型別
HBASE對事務的支援很差Hbase使用場景
大資料量儲存,大資料量高併發操作
需要對資料隨機讀寫操作
讀寫訪問均是非常簡單的操作
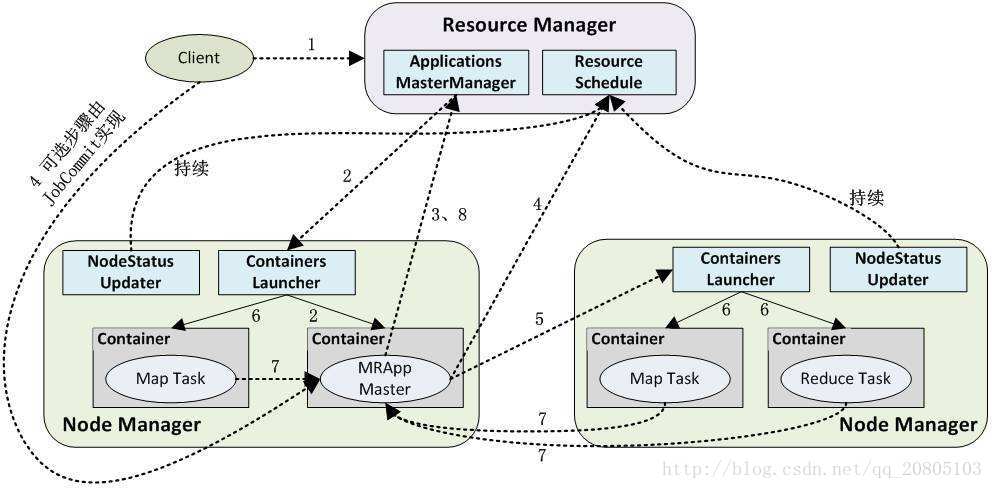
5、Yarn的體系架構
概念
Yarn是一個分散式程式的執行排程平臺,是hadoop2.X版本後新加入的模組。
yarn中有兩大核心角色:
(1)Resource Manager
接受使用者提交的分散式計算程式,併為其劃分資源。
管理、監控各個Node Manager上的資源情況,以便於均衡負載。
(2)Node Manager
管理它所在機器的運算資源(cpu + 記憶體)。
負責接受Resource Manager分配的任務,建立容器、回收資源。Yarn的工作機制
(1)使用者向YARN中提交應用程式,其中包括ApplicationMaster程式、啟動ApplicationMaster的命令、使用者程式等。
(2)ResourceManager為該應用程式分配第一個Container,並與對應的NodeManager通訊,要求它在這個Container中啟動應用程式的ApplicationMaster。
(3)ApplicationMaster首先向ResourceManager註冊,這樣使用者可以直接通過ResourceManager檢視應用程式的執行狀態,然後它將為各個任務申請資源,並監控它的執行狀態,直到執行結束,即重複步驟4~7。
(4)ApplicationMaster採用輪詢的方式通過RPC協議向ResourceManager申請和領取資源。
(5)一旦ApplicationMaster申請到資源後,便與對應的NodeManager通訊,要求它啟動任務。
(6)NodeManager為任務設定好執行環境(包括環境變數、JAR包、二進位制程式等)後,將任務啟動命令寫到一個指令碼中,並通過執行該指令碼啟動任務。
(7)各個任務通過某個RPC協議向ApplicationMaster彙報自己的狀態和進度,以讓ApplicationMaster隨時掌握各個任務的執行狀態,從而可以在任務失敗時重新啟動任務。
在應用程式執行過程中,使用者可隨時通過RPC向ApplicationMaster查詢應用程式的當前執行狀態。
(8)應用程式執行完成後,ApplicationMaster向ResourceManager登出並關閉自己。