
I3D論文解讀(Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset)
阿新 • • 發佈:2019-01-10
論文:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
期刊:CVPR2017
papar:https://arxiv.org/pdf/1705.07750v1.pdf
相關工作:
相關工作就是下面這個圖
文章兩個重大貢獻:1 提出了kinetics資料集。2 提出了雙流3D卷積模型
3D ConvNet
模型細節:是原論文中C3D的變種。8層卷積、5層pooling、2層全連線。與C3D的區別在於這裡的卷積和全連線層後面加BN;且在第一個pooling層使用stride=2,這樣使得batch_size可以更大。輸入是16幀,每幀112*112。
Two-Stream Networks
LSTM缺點:能model高層變化卻不能捕捉低層運動(因為在低層,每個幀都是獨立地被CNN提取特徵),有些低層運動可能是重要的;訓練很昂貴
Two-Stream Networks: 將單獨的一張RGB圖片和一疊計算得到的光流幀分別送入在ImageNet上預訓練的ConvNet中,再把兩個通道的score取平均
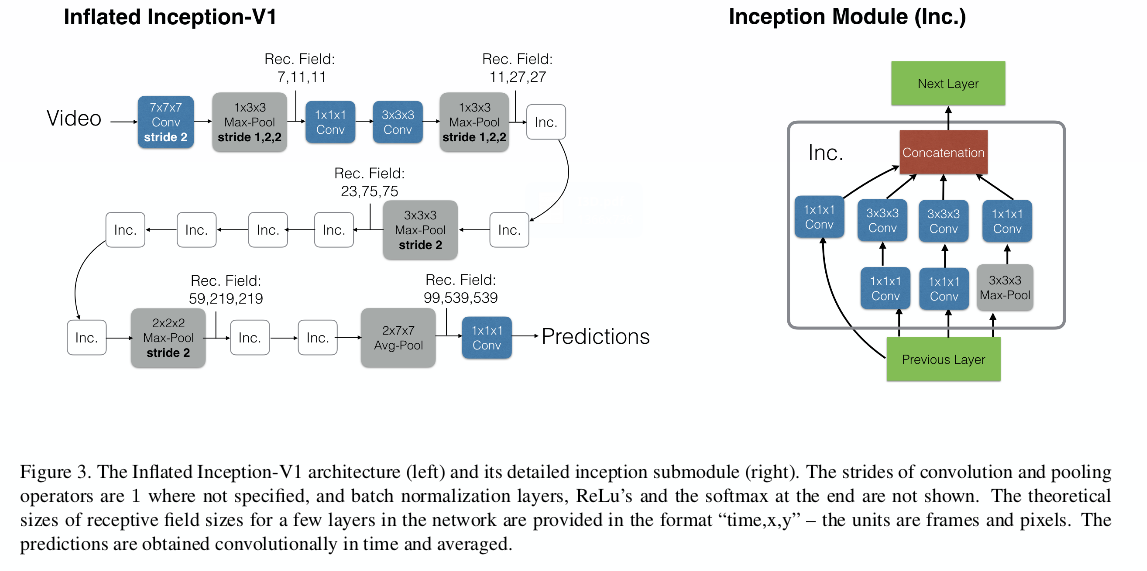
New*: Two-Stream Inflated 3D ConvNets
Implementation Details

模型:
實驗結果,可以看到I3D的準確率提高了許多:

參考文章:
https://blog.csdn.net/paranoid_cnn/article/details/77933316