
一文帶你搭建簡單的酒店推薦系統
阿新 • • 發佈:2019-01-09
1. 資料
資料是匿名使用者的,並且所有欄位都是數字格式。資料可以在Kaggle中下載,train.csv中記錄使用者的行為,destinations.csv包含了使用者的酒店資訊。


import datetime import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from sklearn.model_selection import cross_val_score from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline from sklearn import preprocessing from sklearn.preprocessing import StandardScaler from sklearn import svm
為了能夠在本地執行,我們隨機選取了1%的資料,但仍然有24179條資料。
df = pd.read_csv('train.csv.gz', sep=',').dropna()
dest = pd.read_csv('destinations.csv.gz')
df = df.sample(frac=0.01, random_state=99)
df.shape
輸出:(241179, 24)
2. 探索性分析
該系統的目的是要根據使用者的搜尋資訊,預測使用者將會預定哪種旅館。總共有100種。換言之,我們是要處理一個100分類問題。
plt.figure(figsize=(12, 6)) sns.distplot(df['hotel_cluster'])
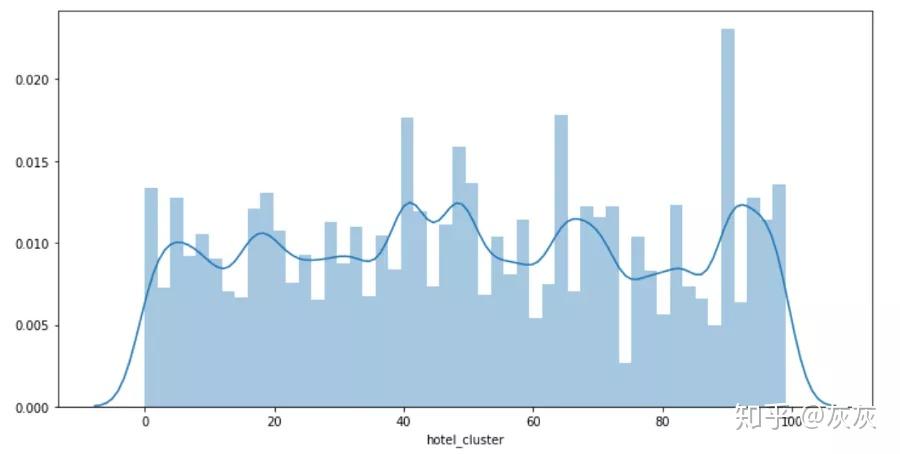
可以看出每個類的分佈很均勻。
3. 特徵工程
Checkin和checkout列的資料是時間格式的資料,不能直接使用。我們將從中提取出年份和月份。通過定義一個函式取抽取,並將他們合併到destination.csv中。
from datetime import datetime def get_year(x): if x is not None and type(x) is not float: try: return datetime.strptime(x, '%Y-%m-%d').year except ValueError: return datetime.strptime(x, '%Y-%m-%d %H:%M:%S').year else: return 2013 pass def get_month(x): if x is not None and type(x) is not float: try: return datetime.strptime(x, '%Y-%m-%d').month except: return datetime.strptime(x, '%Y-%m-%d %H:%M:%S').month else: return 1 pass def left_merge_dataset(left_dframe, right_dframe, merge_column): return pd.merge(left_dframe, right_dframe, on=merge_column, how='left')
處理時間格式的列:
df['date_time_year'] = pd.Series(df.date_time, index = df.index)
df['date_time_month'] = pd.Series(df.date_time, index = df.index)
from datetime import datetime
df.date_time_year = df.date_time_year.apply(lambda x: get_year(x))
df.date_time_month = df.date_time_month.apply(lambda x: get_month(x))
del df['date_time']
處理srch_ci列:
df['srch_ci_year'] = pd.Series(df.srch_ci, index=df.index)
df['srch_ci_month'] = pd.Series(df.srch_ci, index=df.index)
# convert year & months to int
df.srch_ci_year = df.srch_ci_year.apply(lambda x: get_year(x))
df.srch_ci_month = df.srch_ci_month.apply(lambda x: get_month(x))
# remove the srch_ci column
del df['srch_ci']
處理srch_co列:
df['srch_co_year'] = pd.Series(df.srch_co, index=df.index)
df['srch_co_month'] = pd.Series(df.srch_co, index=df.index)
# convert year & months to int
df.srch_co_year = df.srch_co_year.apply(lambda x: get_year(x))
df.srch_co_month = df.srch_co_month.apply(lambda x: get_month(x))
# remove the srch_co column
del df['srch_co']
4. 初步分析
在建立了一些新列和去除一些無用的列後,我們想要知道每一列跟類標是否有線性關係。這可以讓我們更加關注一些特定的特徵。
df.corr()["hotel_cluster"].sort_values()
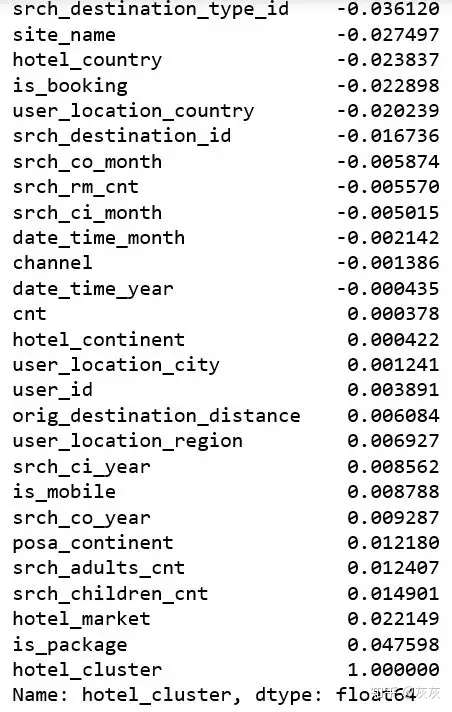
可以看出所有的列都基本跟類標沒什麼線性關係。這意味著剛才的那些方法對這個問題並不合適。
5. 策略
在快速的進行谷歌搜尋之後,我們不難發現將目的地、旅館國家、旅館超市結合起來能夠更加準確的幫助我們找到對應的類標。
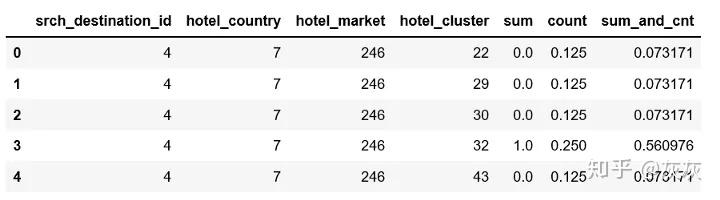
pieces = [df.groupby(['srch_destination_id','hotel_country','hotel_market','hotel_cluster'])['is_booking'].agg(['sum','count'])]
agg = pd.concat(pieces).groupby(level=[0,1,2,3]).sum()
agg.dropna(inplace=True)
agg.head()

agg['sum_and_cnt'] = 0.85*agg['sum'] + 0.15*agg['count']
agg = agg.groupby(level=[0,1,2]).apply(lambda x: x.astype(float)/x.sum())
agg.reset_index(inplace=True)
agg.head()
agg_pivot = agg.pivot_table(index=['srch_destination_id','hotel_country','hotel_market'], columns='hotel_cluster', values='sum_and_cnt').reset_index()
agg_pivot.head()

df = pd.merge(df, dest, how='left', on='srch_destination_id')
df = pd.merge(df, agg_pivot, how='left', on=['srch_destination_id','hotel_country','hotel_market'])
df.fillna(0, inplace=True)
df.shape
輸出:(241179, 276)
6. 實現演算法
我們只對預定的樣本有興趣:
df = df.loc[df['is_booking'] == 1]
得到特徵和類標:
X = df.drop(['user_id', 'hotel_cluster', 'is_booking'], axis=1)
y = df.hotel_cluster
樸素貝葉斯:
from sklearn.naive_bayes import GaussianNB
clf = make_pipeline(preprocessing.StandardScaler(), GaussianNB(priors=None))
np.mean(cross_val_score(clf, X, y, cv=10))
0.10347912437041926
KNN:
from sklearn.neighbors import KNeighborsClassifier
clf = make_pipeline(preprocessing.StandardScaler(), KNeighborsClassifier(n_neighbors=5))
np.mean(cross_val_score(clf, X, y, cv=10, scoring='accuracy'))
0.25631461834732266
隨機森林:
clf = make_pipeline(preprocessing.StandardScaler(), RandomForestClassifier(n_estimators=273,max_depth=10,random_state=0))
np.mean(cross_val_score(clf, X, y, cv=10))
0.24865023372782996
多分類邏輯迴歸:
from sklearn.linear_model import LogisticRegression
clf = make_pipeline(preprocessing.StandardScaler(), LogisticRegression(multi_class='ovr'))
np.mean(cross_val_score(clf, X, y, cv=10))
0.30445543572367767
支援向量機:很耗時,但是效果更好。
from sklearn import svm
clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(decision_function_shape='ovo'))
np.mean(cross_val_score(clf, X, y, cv=10))
0.3228727137315005
看起來我們需要做更多的特徵工程去優化結果。接下來將會進一步調優。
轉自 :磐創AI