
[python3.6]爬蟲實戰之爬取淘女郎圖片
原博主地址:http://cuiqingcai.com/1001.html
原博是python2.7寫的,並且隨著淘寶程式碼的改版,原博爬蟲已經不可用。
參考 http://minstrel.top/TaoBaoMM 這位博主跟我一樣最近正在學習爬蟲。
1 定個小目標
lcw先生聽說我即將爬取美女的照片,兩眼都亮了。沒錯,我要給他福利了(其實女生也很喜歡美女)。
所以,定個最小的目標:
1.在F盤建立美女資料夾
2.資料夾下按照淘女郎美人庫預設美人排序,抓取31個美女的資訊(因為一頁預設是30個人,不至於太少,也能太多要不然抓取時間太多,lcw的破電腦也裝不下)
3.每個以美人名字命名的資料夾下,取10張照片(內容小,別介)
2 抓取過程
進入淘女郎首頁之後,點選找模特,進入我們需要爬取的頁面。可以看到頁面上是預設tag在美人庫上。也即是有30位預設的美人出現在頁面。每一位有相應的照片以及個人資訊。30位美人下方,是頁碼和總美人數的資訊。因為我也是web出身。像這種資訊和數量都有變化的資訊展示,肯定不是靜態頁面。一般都是通過js動態載入而來。通過開發者工具(google瀏覽器,F12,
Json handle外掛 感謝小夥伴告訴我這個外掛),動態監控network.在查詢載入資訊的http時,我犯了個錯誤,一直以為返回的資訊應該是json資訊。這是我們post返回結果最常見的格式,但事實是返回的xhr資訊。這就是抓包工具用得少的下場,哭。
明確了type是xhr後,很快找到了這個:
https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8q=&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=2&pageSize=100我們只需要currentPage這個引數。
https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8¤tPage=2可以立刻看到下一頁的資訊。 輸入這個網址,藉助json handle外掛得到:可以看到頁面上清楚的顯示了當前頁面上30位佳麗的資訊,以及當前頁面,總共美女數目。
其實這些資訊也可以通過正則匹配來得到,不過相對於直接使用js獲取,肯定後者更快捷。
2 目標
1.找到模特總頁數
2.找到所得頁的模特的json格式的資訊,這一步主要為了獲取每個模特的id。只有知道id才能進入到她的主頁。這裡
有一個十分重要的資訊,是之前我忽略了的。就是動態頁面。爬蟲通過url可以得到一個頁面,也無法得到載入該頁面
時通過引數動態載入的內容。所以,這裡想要通過url直接得到模特的資訊內容是不可能的。這是靜態頁面與動態
頁面的區別。
3.找到相簿總頁數
4.找到所得相簿頁的json格式的資訊。與第二步相似。得到每個相簿的id.
5.通過相簿id得到每個相簿的url。通過該url爬取該相簿下的內容。
(身為一個大寫的直男,lcw同學在看到我的目標之後,提出了更進一步的要求:要篩選出理想身高理想顏值的mm。好,
後期為你實現。)
3 按照目標步驟寫程式
3.1 根據https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8¤tPage=1可以得到上述
圖片中展示的資訊。程式如下:
#!usr/bin/env/python
#encoding:UTF-8
import urllib
import requests
import json
import os
import re
import time
currentPage = 1
headers = {
'User-Agent': r'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT) '
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
try:
data = urllib.parse.urlencode({"currentPage":currentPage}).encode('utf-8')
request = urllib.request.Request(url,data = data, headers = headers)
res = urllib.request.urlopen(request).read().decode('gbk')
print(res)
except urllib.error.URLError as e:
if hasattr(e, "reason"):
print("連線失敗,錯誤原因:",e.reason)
注意,這裡的res是使用gbk。這個也是通過network中檢視response得到的。
3.2 點選一位模特(以朱琳為例)的主頁面,得到地址https://mm.taobao.com/self/model_album.htm?
spm=719.7800510.a312r.17.xcy6bS&user_id=176817195。spm不知道是什麼暫時不管。user_id已經通過上面的json
得到了。那麼怎麼得到動態載入得到的相簿資訊呢。F12,重新整理檢視,得到返回值為xhr的一個請求地址:https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20=176817195。
在位址列輸入上面的地址得到圖片:
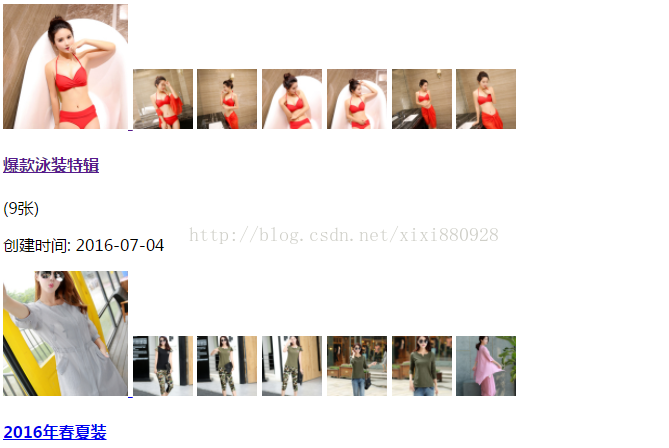
以上資訊雖然不是json格式的資訊,但是我們欣喜的發現,所需要的資訊全部在這裡。用爬蟲獲取上述url的html內容
相簿ID和相簿總頁數都得到了。其實跟json差不多。
多說一句。本來我檢視原始頁面,不是這個中間請求頁面時,想要根據下面這個獲得總的相簿頁數:
檢視:

的原始碼:
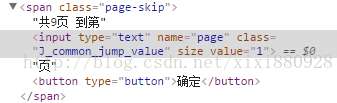
之前是希望通過上述程式碼得到總頁面數'9'. 發現通過https://mm.taobao.com/self/model_album.htm?user_id=17681
7195無法獲取上述Html.
只能找到載入該頁面時的動態請求https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user
_id%20=176817195的原始碼,從而得到:

老實說這種方法真的很笨。不知道有沒有更簡易的方式。
找到相簿ID後。,通過https://mm.taobao.com/self/album_photo.htm?user_id=176817195&album_id=10000962815
點選進入相簿,同樣查詢xhr檔案,找到:https://mm.taobao.com/self/album/album_photo_list.htm?user_id=
176817195&album_id=301783179&album_flag=0,直接開啟該連線原始碼找到:
https://mm.taobao.com/album/json/get_album_photo_list.htm?user_id=176817195&album_id=10000794223&page=1
這總算找到了相簿的資訊。

這個資訊簡直要什麼有什麼啊。
好了。
現在開始寫程式:
#!usr/bin/env/python
#encoding:UTF-8
import urllib
import requests
import json
import os
import re
import time
class MMSpider:
def __init__(self):
self.__code_type = 'gbk'
self.__http = 'http:'
# 美人庫動態載入xhr資料的url
self.__url = 'http://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
# 模特主頁地址
self.__person_url = 'http://mm.taobao.com/self/aiShow.htm?userId='
#相簿地址
self.__all_album_url = 'https://mm.taobao.com/self/album/open_album_list.htm?_charset=utf-8&user_id%20='
# 具體相簿地址
self.__pic_url = "https://mm.taobao.com/album/json/get_album_photo_list.htm?user_id="
# 儲存照片的基地址
self.__save_path = 'F:\Beauty'
# 想要獲取的頁數
self.__total_page = 1
# 當前正在提取的頁數
self.__currentPage = 1
# 找到具體album的id的正則表示式
self.__album_id_pattern = re.compile('''<h4>.*?album_id=(.*?)&''', re.S)
# album有多少的的正則表示式
# 找到具體album的id的正則表示式
self.__album_page_pattern = re.compile('''<input name="totalPage" id="J_Totalpage" value="(.*?)"''', re.S)
#根據動態請求獲取需要的第X頁的json資料,找出userId
def get_person_dict(self, currentPage):
try:
data = {
"currentPage":currentPage
}
data = urllib.parse.urlencode(data).encode('utf-8')
request = urllib.request.Request(self.__url, data=data)
response = urllib.request.urlopen(request)
result = response.read().decode(self.__code_type)
return json.loads(result)
except urllib.error.URLError as e:
print('美人動態載入資訊出錯',e.reason)
# 根據得到的userID,找到相簿的總頁數
def get_album_page(self, userId):
try:
all_album_url = self.__all_album_url+str(userId)
res = urllib.request.urlopen(all_album_url)
html = res.read().decode(self.__code_type)
return re.search(self.__album_page_pattern, html).group(1)
except urllib.error.URLError as e:
print('動態載入相簿總資訊出錯',e.reason)
return None
# 由得到的相簿總頁數範圍內指定的頁數,獲取該頁所有相簿的ID
def get_album_ids(self, userId, page):
try:
all_album_url = self.__all_album_url + str(userId) + "&" + str(page)
request = urllib.request.Request(all_album_url)
response = urllib.request.urlopen(request)
html = response.read().decode(self.__code_type)
# 提取該頁中album的id
return re.findall(self.__album_id_pattern, html)
except urllib.error.URLError as e:
print("提取相簿id出錯了!", e.reason)
# 找到一個相簿內的圖片有多少頁
def get_pic_page(self, userId, albumId):
try:
# 先得到這個相簿一共有多少頁
url = self.__pic_url + str(userId) + "&album_id=" + str(albumId)
response = urllib.request.urlopen(url)
result = json.loads(response.read().decode(self.__code_type))
return result["totalPage"]
except urllib.error.URLError as e:
print(e.reason)
return None
# 根據相簿圖片頁數獲取指定頁數的圖片資訊
def get_img_url(self, person, j, album_id):
url = self.__pic_url + str(person["userId"]) \
+ "&album_id=" + str(album_id) \
+ "&page=" + str(j)
try:
response = urllib.request.urlopen(url, timeout=5)
result = response.read().decode(self.__code_type)
imgs_url = json.loads(result)["picList"]
return imgs_url
except TimeoutError as e:
print('1',e.strerror)
except urllib.error.URLError as e:
print('2',e.reason)
except BaseException as e:
print('3',e.args)
# 儲存model的個人資訊
def save(self, searchDOList):
for person in searchDOList:
dir_path = self.__save_path+'\\'+person['realName']
if self.mkdir(dir_path):
txt_path = dir_path+'\\'+person['realName']+'.txt'
self.write_txt(txt_path, person)
self.save_imgs(person,dir_path)
def mkdir(self, dir_path):
if(os.path.exists(dir_path)):
return False
else:
os.mkdir(dir_path)
return True
def write_txt(self,txt_path, person):
person_url = self.__person_url+str(person['userId'])
content = "姓名:" + person["realName"] + " 城市:" + person["city"] \
+ "\n身高:" + str(person["height"]) + " 體重:" + str(person["weight"]) \
+ "\n喜歡:" + str(person["totalFavorNum"]) \
+ "\n個人主頁:" + person_url
with open(txt_path, 'w',encoding='utf-8')as file:
print('正在儲存%s的文字資訊'%(person['realName']))
file.write(content)
file.close()
def save_imgs(self, person, dir_path):
album_page = self.get_album_page(person['userId'])
print(album_page)
img_index = 1
for i in range(1, int(album_page)+1):
album_ids =self.get_album_ids(person["userId"],i)
for album_id in album_ids:
pic_page = self.get_pic_page(person["userId"],album_id)
for j in range(1, int(pic_page)+1):
img_urls = self.get_img_url(person,j,album_id)
for img_url in img_urls:
try:
url = self.__http+img_url["picUrl"]
res = urllib.request.urlopen(url, timeout =5)
with open(dir_path+'\\'+str(img_index)+'.jpg','wb') as file:
file.write(res.read())
if img_index % 10 ==0:
print('sleep 1 second')
time.sleep(1)
if img_index>=11:
print('%s已儲存11張辣照'%person['realName'])
file.close()
return
img_index +=1
except TimeoutError as e:
print('1',e.strerror)
except urllib.error.URLError as e:
print('2',e.reason)
def start(self):
print("開始!")
opener = urllib.request.build_opener()
opener.addheaders = [("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36")]
urllib.request.install_opener(opener)
for i in range(self.__total_page):
dict_result = self.get_person_dict(self.__currentPage)
searchDOList = dict_result["data"]["searchDOList"]
# 儲存所有本頁中MM的資訊
self.save(searchDOList)
self.__currentPage += 1
if __name__=="__main__":
spider = MMSpider()
spider.start()