
機器學習實戰系列(五):SVM支援向量機
課程的所有資料和程式碼在我的Github:Machine learning in Action,目前剛開始做,有不對的歡迎指正,也歡迎大家star。除了 版本差異,程式碼裡的部分函式以及程式碼正規化也和原書不一樣(因為作者的程式碼實在讓人看的彆扭,我改過後看起來舒服多了)。在這個系列之後,我還會寫一個scikit-learn機器學習系列,因為在實現了原始碼之後,帶大家看看SKT框架如何使用也是非常重要的。
1、支援向量機概述
1.1 原理簡述
所謂支援向量機,顧名思義,分為兩個部分了解,一什麼是支援向量(簡單來說,就是支援(或支撐)平面上把兩類類別劃分開來的超平面的向量點),二這裡的“機(machine,機器)
用一個二維空間裡僅有兩類樣本的分類問題來舉個小例子。 如圖所示

正方形和圓圈是要區分的兩個類別,在二維平面中它們的樣本如上圖所示。中間的直線就是一個分類函式,它可以將兩類樣本完全分開。在這種情況下邊緣實心的幾個資料點就叫做支援向量,這也是支援向量機這個分類演算法名字的來源。在SVM中,我們尋找一條最優的分界線使得它到兩邊的邊界都最大(最大化支援向量到分隔線(面)的距離)。
一般的,如果一個線性函式能夠將樣本完全正確的分開,就稱這些資料是線性可分的,否則稱為非線性可分的。什麼叫線性函式呢?在一維空間裡就是一個點,在二維空間裡就是一條直線,三維空間裡就是一個平面,可以如此想象下去,如果不關注空間的維數,這種線性函式還有一個統一的名稱——超平面
在實際中,我們經常會遇到線性不可分的樣例,此時,我們的常用做法是把樣例特徵通過某種核函式對映到高維空間中去,使其線性可分。下圖即是對映前後的結果,將座標軸經過適當的旋轉,就可以很明顯地看出,資料是可以通過一個平面來分開的。
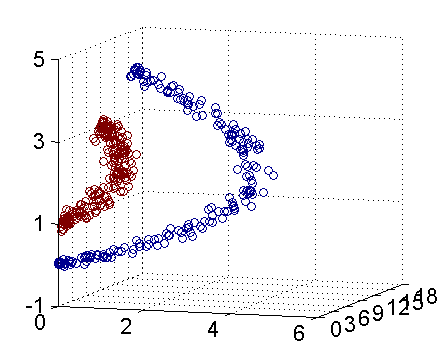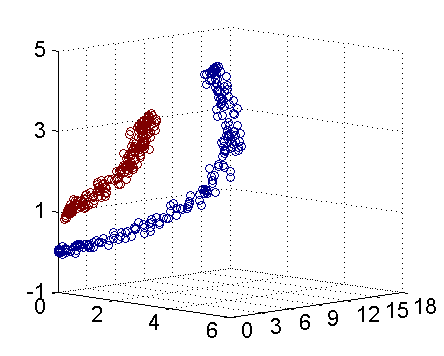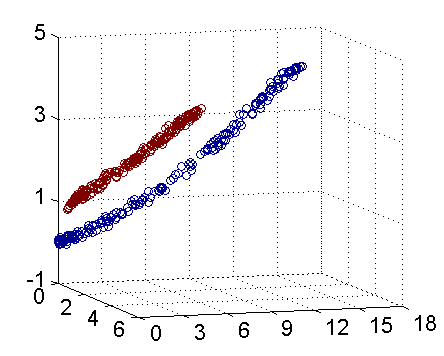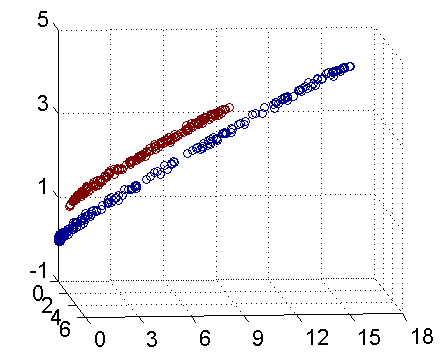
核函式的價值在於它雖然也是將特徵進行從低維到高維的轉換,但核函式厲害在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,避免了直接在高維空間中的複雜計算。
1.2 特點
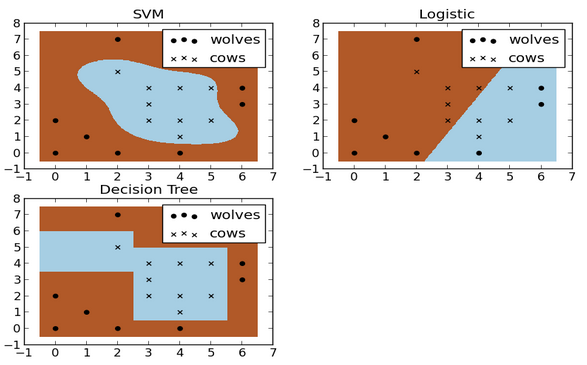
將SVM演算法和前面介紹的Logistic迴歸和決策樹演算法作對比,如下圖所示,我們能直觀看到SVM作為非線性分類器的優勢。
優點:泛化錯誤率低,計算開銷不大,結果易解釋
缺點:對引數調節和核函式的選擇敏感,原始分類器不加修改僅適用於處理二類問題
適用資料型別:數值型和標稱型資料,類別標籤為+1和-1
2、尋找最大分類間隔
2.1 關於線性分類器
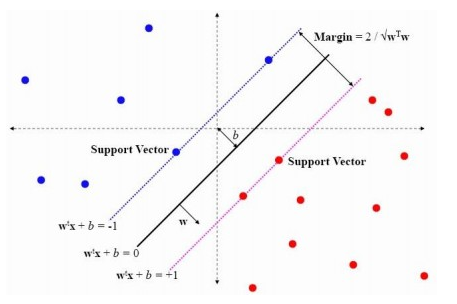
上圖中紅藍兩類資料點可以用線性函式 g(x)=w*x+b 區分開,關於這個線性函式要注意一下三點
- 式中的 x 不是二維座標系中的橫軸,而是樣本的向量表示,例如一個樣本點的座標是(3,8),則x=(3,8),而不是x=3
- 這個形式並不侷限於二維的情況,在 n 維空間中仍然可以使用這個表示式,只是式中的 w 成為了 n 維向量
- g(x) 不是中間那條直線的表示式,中間那條直線的表示式是g(x)=0,即 w*x+b = 0,也把這個函式叫做分類面
易知中間那條分界線並不是唯一的,把它稍微旋轉或平移一下,仍然可以達到上面說的效果。那就牽涉到一個問題,對同一個問題,哪一個函式更好?通常的衡量指標叫做分類間隔。
2.2 分類間隔
在監督學習中,每一個樣本由一個特徵向量和一個類別標籤組成,如下:
Di=(xi,yi)
xi 就是特徵向量,就是yi 分類標記。
在二元的線性分類中, 這個表示分類的標記只有兩個值,+1和-1。有了這種表示法,我們就可以定義一個樣本點到某個超平面的間隔(函式間隔):
![]()
注意到如果某個樣本屬於該類別的話,那麼wi*x+b > 0(這是因為我們所選的g(x)=wx+b就是通過大於0還是小於0來判斷分類),而yi也大於0;若不屬於該類別的話,那麼wi*x+b < 0 ,而yi也小於0,這意味著yi(w*xi+b)總是大於0,而它的值就等於|wxi+b|, 也即|g(xi)|.
現在把w和b進行歸一化,即用w/||w||和b/||w||分別代替原來的w和b,那麼間隔就可以寫成如下形式,叫做幾何間隔,幾何間隔所表示的正是點到超平面的歐式距離。
![]()
其中,||w|| 叫做向量w的範數,範數是對向量長度的一種度量。我們常說的向量長度其實指的是它的2-範數,範數最一般的表示形式為p-範數,可以寫成如下形式:
![]()
好,到這現在的目標就是找出分離器定義中的w和b。而前面我們知道SVM依據最大化支援向量到分隔線(面)的距離,為此我們必須找到具有最小間隔的資料點,而這些資料點也就是前面提到的支援向量。一旦找到具有最小間隔的資料點,我們就需要對該間隔最大化。這就可以寫作:
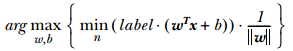
直接求解上述問題相當困難,可以將它轉換成為另一種更容易求解的形式。考察上式中大括號內的部分,我們可以固定其中一個因子而最大化其他因子。如果令所有支援向量 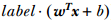 的都為1,那麼就可以通過求 ||w|| 的最小值來得到最終解。但是, 並非所有資料點的
的都為1,那麼就可以通過求 ||w|| 的最小值來得到最終解。但是, 並非所有資料點的 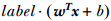 都等於1,只有那些離分隔超平面最近的點得到的值才為1。而離超平面越遠的資料點,其值也就越大。
都等於1,只有那些離分隔超平面最近的點得到的值才為1。而離超平面越遠的資料點,其值也就越大。
上述問題是一個帶約束條件的優化問題,這裡的約束條件是 大於等於1,對於這類問題可以引入拉格朗日乘子法求解。由於這裡的約束條件都是基於資料點的,因此我們就可以將超平面寫成資料點的形式。於是,優化目標函式最後可以寫成:
大於等於1,對於這類問題可以引入拉格朗日乘子法求解。由於這裡的約束條件都是基於資料點的,因此我們就可以將超平面寫成資料點的形式。於是,優化目標函式最後可以寫成:
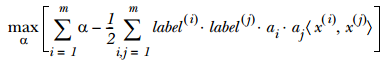
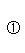
其約束條件為:
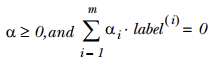
這裡我們有個假設即資料100%線性可分,但是實際上並不是所有資料都能達到該要求,因此我們可以通過引入所謂鬆弛變數——C,來允許有些資料點可以處於分隔面的錯誤一側,這時約束條件變為:
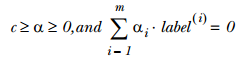
這裡的常數C用於控制 “最大化間隔” 和 “保證大部分點的函式間隔小於1.0” 這兩個目標的權重。在優化演算法的實現程式碼中,常數C是一個引數,因此我們就可以通過調節該引數得到不同的結果。一旦求出了所有的alpha,那麼分隔超平面就可以通過這些alpha來表達。
3、SMO演算法
本節對前面的兩個式子進行優化,一個是最小化的目標函式,一個是遵循的約束條件。優化的方法有很多種,但本章只關注其中最流行的一種實現,即序列最小優化(SMO)演算法。SMO演算法的目標是求出一系列alpha和b,一旦求出了這些alpha,就很容易計算出權重向量w並得到分隔超平面(2維平面中就是直線),再能夠將之用於資料分類。
SMO演算法的工作原理是:每次迴圈中選擇兩個alpha進行優化處理。一旦找到一對合適的alpha,那麼就增大其中一個同時減小另一個。這裡所謂的“合適” 就是指兩個alpha必須要符合一定的條件,即這兩個alpha必須要在間隔邊界之外,且這兩個alpha還沒有進行過區間化處理或者不在邊界上。
3.1 簡化版SMO演算法處理小規模資料集
SMO演算法的完整實現需要大量程式碼。在接下來的第一個例子中,我們將會對演算法進行簡化處理,以便了解演算法的基本工作思路,之後再基於簡化版給出完整版。
該演算法虛擬碼大致如下:
建立一個alpha向量並將其初始化為O向量
當迭代次數小於最大迭代次數時(外迴圈)
對資料集中的每個資料向量(內迴圈):
如果該資料向量可以被優化:
隨機選擇另外一個數據向量
同時優化這兩個向量
如果兩個向量都不能被優化,退出內迴圈
如果所有向量都沒被優化,增加迭代數目,繼續下一次迴圈載入資料集
import random
# SMO演算法相關輔助中的輔助函式
# 解析文字資料函式,提取每個樣本的特徵組成向量,新增到資料矩陣
# 新增樣本標籤到標籤向量
def loadDataSet(filename):
dataMat=[];labelMat=[]
fr=open(filename)
for line in fr.readlines():
lineArr=line.strip().split('\t')
dataMat.append([float(lineArr[0]),float(lineArr[1])])
#if int(lineArr[2]) == 0 :
# labelMat.append((float(lineArr[2]) - 1))
#else:
labelMat.append((float(lineArr[2] )))
return dataMat,labelMat
#2 在樣本集中採取隨機選擇的方法選取第二個不等於第一個alphai的
#優化向量alphaj
def selectJrand(i,m):
j=i
while(j==i):
j=int(random.uniform(0,m))
return j
#3 約束範圍L<=alphaj<=H內的更新後的alphaj值
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return ajSMO演算法(簡單版)
def smoSimple(dataMat,classLabels,C,toler,maxIter):
'''
@dataMat :資料列表
@classLabels:標籤列表
@C :權衡因子(增加鬆弛因子而在目標優化函式中引入了懲罰項)
@toler :容錯率
@maxIter :最大迭代次數
'''
#將列表形式轉為矩陣或向量形式
dataMatrix=mat(dataMat);labelMat=mat(classLabels).transpose()
#初始化b=0,獲取矩陣行列
b=0;m,n=shape(dataMatrix)
#新建一個m行1列的向量
alphas=mat(zeros((m,1)))
#迭代次數為0
iters=0
while(iters<maxIter):
#改變的alpha對數
alphaPairsChanged=0
#遍歷樣本集中樣本
for i in range(m):
#計算支援向量機演算法的預測值
fXi=float(multiply(alphas,labelMat).T*\
(dataMatrix*dataMatrix[i,:].T))+b
#計算預測值與實際值的誤差
Ei=fXi-float(labelMat[i])
#如果不滿足KKT條件,即labelMat[i]*fXi<1(labelMat[i]*fXi-1<-toler)
#and alpha<C 或者labelMat[i]*fXi>1(labelMat[i]*fXi-1>toler)and alpha>0
if(((labelMat[i]*Ei < -toler)and(alphas[i] < C)) or \
((labelMat[i]*Ei>toler) and (alphas[i]>0))):
#隨機選擇第二個變數alphaj
j = selectJrand(i,m)
#計算第二個變數對應資料的預測值
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*\
dataMatrix[j,:].T)) + b
#計算與測試與實際值的差值
Ej = fXj - float(labelMat[j])
#記錄alphai和alphaj的原始值,便於後續的比較
alphaIold=alphas[i].copy()
alphaJold=alphas[j].copy()
#如何兩個alpha對應樣本的標籤不相同
if(labelMat[i]!=labelMat[j]):
#求出相應的上下邊界
L=max(0,alphas[j]-alphas[i])
H=min(C,C+alphas[j]-alphas[i])
else:
L=max(0,alphas[j]+alphas[i]-C)
H=min(C,alphas[j]+alphas[i])
if L==H: print("L==H");continue
#根據公式計算未經剪輯的alphaj
#------------------------------------------
eta=2.0*dataMatrix[i,:]*dataMatrix[j,:].T-\
dataMatrix[i,:]*dataMatrix[i,:].T-\
dataMatrix[j,:]*dataMatrix[j,:].T
#如果eta>=0,跳出本次迴圈
if eta>=0:print("eta>=0"); continue
alphas[j]-=labelMat[j]*(Ei-Ej)/eta
alphas[j]=clipAlpha(alphas[j],H,L)
#------------------------------------------
#如果改變後的alphaj值變化不大,跳出本次迴圈
if(abs(alphas[j]-alphaJold)<0.00001):print("j not moving\
enough");continue
#否則,計算相應的alphai值
alphas[i]+=labelMat[j]*labelMat[i]*(alphaJold-alphas[j])
#再分別計算兩個alpha情況下對於的b值
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]\
*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[i,:]*dataMatrix[j,:].T
b2=b-Ej-labelMat[i]*(alphas[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[j,:].T-\
labelMat[j]*(alphas[j]-alphaJold)*\
dataMatrix[j,:]*dataMatrix[j,:].T
#如果0<alphai<C,那麼b=b1
if(0<alphas[i]) and (C>alphas[i]):b=b1
#否則如果0<alphai<C,那麼b=b1
elif (0<alphas[j]) and (C>alphas[j]):b=b2
#否則,alphai,alphaj=0或C
else:b=(b1+b2)/2.0
#如果走到此步,表面改變了一對alpha值
alphaPairsChanged+=1
print("iters: %d i:%d,paird changed %d" %(iters,i,alphaPairsChanged))
#最後判斷是否有改變的alpha對,沒有就進行下一次迭代
if(alphaPairsChanged==0):iters+=1
#否則,迭代次數置0,繼續迴圈
else:iters=0
print("iteration number: %d" %iters)
#返回最後的b值和alpha向量
return b,alphasSMO演算法(完全版)
#內迴圈尋找alphaj
def innerL(i, oS):
Ei = Opt_smo.calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = Opt_smo.selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print("L==H"); return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
Opt_smo.updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
Opt_smo.updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = Opt_smo.optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas核函式
def kernelTrans( X, A, kTup):
'''
RBF kernel function
'''
m ,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0] == 'lin': K = X * A.T
elif kTup[0] == 'rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow * deltaRow.T
K = numpy.exp(K / (-1 * kTup[1] ** 2))
else: raise NameError('huston ---')
return K
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = SMO_platt.smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print("there are %d Support Vectors" % shape(sVs)[0])
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m))
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the test error rate is: %f" % (float(errorCount)/m)) 手寫數字識別
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def loadImages(dirName):
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName) #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
if classNumStr == 9: hwLabels.append(-1)
else: hwLabels.append(1)
trainingMat[i,:] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
def testDigits(kTup=('rbf', 10)):
dataArr,labelArr = loadImages('digits/trainingDigits')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
print ("there are %d Support Vectors" % shape(sVs)[0])
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print ("the training error rate is: %f" % (float(errorCount)/m))
dataArr,labelArr = loadImages('testDigits')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print ("the test error rate is: %f" % (float(errorCount)/m))