
排序演算法--選擇篇(簡單選擇,樹形選擇,堆排序)
選擇類排序的基本思想是每一趟在n-i+1(i=1,2,...,n-1)個記錄中選取關鍵字最小的記錄作為有序序列中第i個記錄。本篇在介紹簡單選擇排序的基礎上,給出了其改進演算法--樹形選擇排序和堆排序。
1.簡單選擇排序
演算法思想:第一趟簡單選擇排序時,從第一個記錄開始,通過N-1次關鍵字的比較,從n個記錄中選出關鍵字最小的記錄,並和第一個記錄進行交換。第二趟簡單選擇排序時,從第二個記錄開始,通過n-2次關鍵字的比較,從n-1個記錄中選出關鍵字最小的記錄,並和第二個記錄表進行交換。......第i趟簡單選擇排序時,從第i個記錄開始,通過n-i次關鍵字的比較,從n-i+1個記錄中選出關鍵字最小的記錄,並和第i個記錄進行交換。如此反覆,經過n-1趟簡單選擇排序,將n-1個記錄排到位,剩下一個最小記錄直接在最後,所以共需進行n-1趟簡單選擇排序。
private static void SelectSort(int[] a) {
int k=0,temp;
for (int i = 0; i < a.length-1; i++) {
k=i;
for (int j = i+1; j < a.length; j++) {
if(a[j]<a[k]) k=j;
}
if(k!=i){
temp=a[i];
a[i]=a[k];
a[k]=temp;
}
}
}演算法分析:i=1時需要進行n-1此比較,i=2時需進行n-2次比較,依次總需要n-1+n-2+..+1=n(n-1)/2,即進行比較操作的時間複雜度為O(n^2),空間複雜度為O(1),不穩定
2.樹形選擇排序
演算法思想:樹形選擇排序也稱作錦標賽排序。基本思想是先把待排序的n個記錄的關鍵字兩兩比較,取出較小者,然後再在[n/2]個較小者中,採用同樣的方法進行比較,選出每兩個中的較小者,如此反覆,直至選出最小關鍵字記錄為止。這個過程可以用一棵滿二叉樹來表示,不滿時用關鍵字為∞的節點填滿,選擇的最小關鍵字記錄就是這棵樹的根節點。在輸出最小關鍵字之後,為選出次小關鍵字,將最小關鍵字記錄所對應的葉子結點的關鍵字值置為∞,然後從該葉節點開始和其兄弟結點的關鍵字比較,修改從該葉結點到根結點路徑上各結點的值,則根結點的值即為次小關鍵字。重複進行上述過程,直到所有的記錄全部輸出為止,如圖所示給出了選取最小及次小關鍵字的過程。
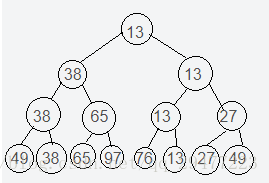

(a)選出最小關鍵字 (b)選出次小關鍵字
private static void treeSelectSort(int[] a){
int len = a.length;
int treeSize = 2 * len - 1; //完全二叉樹的節點數
int low = 0;
Object[] tree = new Object[treeSize]; //臨時的樹儲存空間
//由後向前填充此樹,索引從0開始
for(int i = len-1,j=0 ;i >= 0; --i,j++){
//填充葉子節點
tree[treeSize-1-j] = a[i];
}
for(int i = treeSize-1;i>0;i-=2){
//填充非終端節點
tree[(i-1)/2] = ((Comparable)tree[i-1]).compareTo(tree[i]) < 0 ? tree[i-1]:tree[i];
} //不斷移走最小節點
int minIndex;
while(low < len){
Object min = tree[0]; //最小值
a[low++] = (int) min;
minIndex = treeSize-1;
//找到最小值的索引
while(((Comparable)tree[minIndex]).compareTo(min)!=0){
minIndex--;
}
tree[minIndex] = Integer.MAX_VALUE; //設定一個最大值標誌
//找到其兄弟節點
while(minIndex > 0){ //如果其還有父節點
if(minIndex % 2 == 0){ //如果是右節點
tree[(minIndex-1)/2] = ((Comparable)tree[minIndex-1]).compareTo(tree[minIndex]) < 0 ? tree[minIndex-1]:tree[minIndex];
minIndex = (minIndex-1)/2;
}else{ //如果是左節點
tree[minIndex/2] = ((Comparable)tree[minIndex]).compareTo(tree[minIndex+1]) < 0 ? tree[minIndex]:tree[minIndex+1];
minIndex = minIndex/2;
}
}
}
}演算法分析:假設排序所用滿二叉樹的深度為h,在樹形選擇排序中,除了最小關鍵字,被選出的其他較小關鍵字都是走了一條有葉子結點到根結點的比較的過程且均需比較h-1次。可證明含有n個葉子結點的完全二叉樹的深度h=log2n+1,因此在樹形選擇排序中,每選出一個較小關鍵字需要進行log2n次比較,所以其時間複雜度O(nlog2n) 空間複雜度O(n) 穩定
3.堆排序
威洛母斯對樹形選擇排序進一步的改進方法,堆排序,用以彌補樹形選擇排序佔用空間多的缺憾。採用堆排序時,只需要一個記錄大小的輔助空間。堆排序是在排序過程中,將向量中儲存的資料看成一棵完全二叉樹,利用完全二叉樹中雙親結點和孩子結點之間的內在關係來選擇關鍵字最小的記錄,即待排序記錄仍採用向量陣列方式儲存,並非採用樹的儲存結構,而僅僅是採用完全二叉樹的順序結構的特徵進行分析而已。
演算法思想:在待排序的記錄的關鍵字存放在陣列a[1,...,n]之中,將a看成一棵完全二叉樹的順序表示,每個結點表示一個記錄,第一個記錄a[0]作為二叉樹的根,以下各記錄a[1]~a[n-1]依次逐層從左到右順序排列,任意結點a[i]的左孩子是a[2i],右孩子是a[2i+1],雙親是a[i/2]。對這棵完全二叉樹進行調整建堆。
堆定義:稱各結點的關鍵字值滿足條件:a[i]>=a[2i]切a[i]>a[2i+1]的完全二叉樹為大根堆。反之就是根結點小於孩子結點對應的堆稱為小根堆。例如
98 14
77 35 48 35
62 55 14 35 62 55 98 35
48 77
(a).大根堆 (b).小根堆
實現原理:
1.首先將序列看成一個樹形結構,
構建堆的過程:找到最後一個非終端節點n/2,與它的左右子節點比較,
比較結果使此父節點為這三個節點的最小值。再找n/2-1這個節點,
與其左右子節點比較,得到最小值,以此類推....,最後根節點即為最小值
49 38 65 97 76 13 27 49
初始樹為:
49
38 65
97 76 13 27
49
構造堆後的樹為
13
38 27
49 76 65 49
97
交換資料的順序為:97<——>49, 13<--->65,38不用換,49<-->13,13<-->27
2.輸出堆頂元素並調整建新堆的過程
輸出堆頂最小值後,假設以最後一個值替代之,由於其左右子樹的堆結構並沒有被破壞
只需要自上而下進行調整。比如把上圖的13輸出後以97替代,然後可以把97與27交換,
然後97又與49交換,此時最小值為根元素27,輸出27後以又用最後一個值替換根元素,
以此類推,則最終得到有序序列
private static void HeapSort(int[] a) {
crt_heap(a);
int temp;
for (int i = a.length-1; i >=1; i--) {
temp=a[0];
a[0]=a[i];
a[i]=temp;
sift(a,0,i-1);//使a[0,..,i-1]變成堆
}
}
//重建堆
private static void sift(int[] a, int k, int m) {
int t,x,i,j;
t=a[k];//暫存根記錄a[k]
x=a[k];
i=k;
j=2*i;
boolean finished=false;
while(j<=m&&!finished){//若存在右子樹,且右子樹根的關鍵字大,則沿右分支篩選
if(j<m&&a[j]<a[j+1]) j=j+1;
if(x>=a[j]) finished=true;//篩選完畢
else{//繼續篩選
a[i]=a[j];
i=j;
j=2*i;
}
}
a[i]=t;//a[k]填入到恰當的位置
}
//建立初堆
private static void crt_heap(int[] a) {
int n=a.length-1;
for(int i=n/2;i>=0;--i){//從第[n/2]個記錄開始進行篩選建堆
sift(a,i,n);
}
}演算法分析:在每次迴圈時,左、右子樹先比較一次,然後左、右子樹較大者再與被篩元素比較一次,所以對深度為H的堆,篩選演算法中的關鍵比較次數至多為2(h-1)次。時間複雜度O(nlog2n) 空間複雜度O(1) 不穩定