
word2vec詞向量訓練及中文文字相似度計算
阿新 • • 發佈:2019-01-04
本文是講述如何使用word2vec的基礎教程,文章比較基礎,希望對你有所幫助!
官網C語言下載地址:http://word2vec.googlecode.com/svn/trunk/
官網Python下載地址:http://radimrehurek.com/gensim/models/word2vec.html
參考:《Word2vec的核心架構及其應用 · 熊富林,鄧怡豪,唐曉晟 · 北郵2015年》
《Word2vec的工作原理及應用探究 · 周練 · 西安電子科技大學2014年》
《Word2vec對中文詞進行聚類的研究 · 鄭文超,徐鵬 · 北京郵電大學2013年》
PS:第一部分主要是給大家引入基礎內容作鋪墊,這類文章很多,希望大家自己去學習更多更好的基礎內容,這篇部落格主要是介紹Word2Vec對中文文字的用法。
(1) 統計語言模型
統計語言模型的一般形式是給定已知的一組詞,求解下一個詞的條件概率。形式如下:
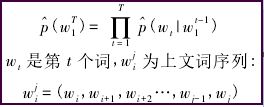
統計語言模型的一般形式直觀、準確,n元模型中假設在不改變詞語在上下文中的順序前提下,距離相近的詞語關係越近,距離較遠的關聯度越遠,當距離足夠遠時,詞語之間則沒有關聯度。
但該模型沒有完全利用語料的資訊:
1) 沒有考慮距離更遠的詞語與當前詞的關係,即超出範圍n的詞被忽略了,而這兩者很可能有關係的。
例如,“華盛頓是美國的首都”是當前語句,隔了大於n個詞的地方又出現了“北京是中國的首都”,在n元模型中“華盛頓”和“北京”是沒有關係的,然而這兩個句子卻隱含了語法及語義關係,即”華盛頓“和“北京”都是名詞,並且分別是美國和中國的首都。
2) 忽略了詞語之間的相似性,即上述模型無法考慮詞語的語法關係。
例如,語料中的“魚在水中游”應該能夠幫助我們產生“馬在草原上跑”這樣的句子,因為兩個句子中“魚”和“馬”、“水”和“草原”、“遊”和“跑”、“中”和“上”具有相同的語法特性。
而在神經網路概率語言模型中,這兩種資訊將充分利用到。
(2) 神經網路概率語言模型
神經網路概率語言模型是一種新興的自然語言處理演算法,該模型通過學習訓練語料獲取詞向量和概率密度函式,詞向量是多維實數向量,向量中包含了自然語言中的語義和語法關係,詞向量之間餘弦距離的大小代表了詞語之間關係的遠近,詞向量的加減運算則是計算機在"遣詞造句"。
神經網路概率語言模型經歷了很長的發展階段,由Bengio等人2003年提出的神經網路語言模型NNLM(Neural network language model)最為知名,以後的發展工作都參照此模型進行。歷經十餘年的研究,神經網路概率語言模型有了很大發展。
如今在架構方面有比NNLM更簡單的CBOW模型、Skip-gram模型;其次在訓練方面,出現了Hierarchical Softmax演算法、負取樣演算法(Negative Sampling),以及為了減小頻繁詞對結果準確性和訓練速度的影響而引入的欠取樣(Subsumpling)技術。
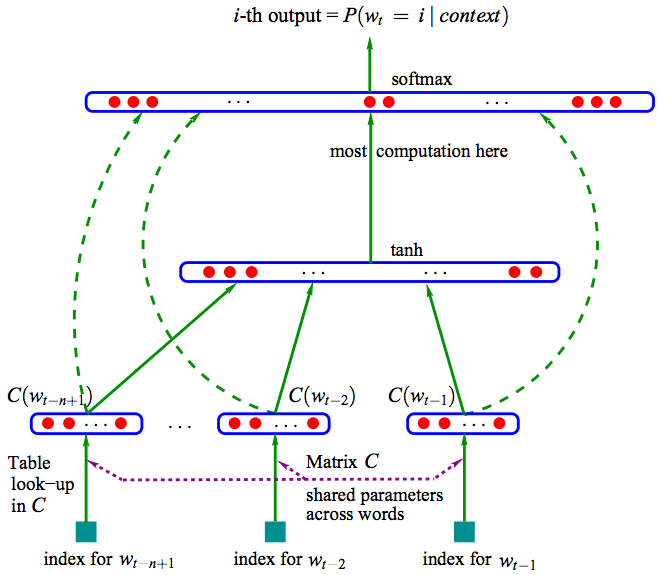
上圖是基於三層神經網路的自然語言估計模型NNLM(Neural Network Language Model)。NNLM可以計算某一個上下文的下一個詞為wi的概率,即(wi=i|context),詞向量是其訓練的副產物。NNLM根據語料庫C生成對應的詞彙表V。
神將網路知識可以參考我的前文部落格:神經網路和機器學習基礎入門分享
NNLM推薦Rachel-Zhang大神文章:word2vec——高效word特徵求取
近年來,神經網路概率語言模型發展迅速,Word2vec是最新技術理論的合集。
Word2vec是Google公司在2013年開放的一款用於訓練詞向量的軟體工具。所以,在講述word2vec之前,先給大家介紹詞向量的概念。
(3) 詞向量
參考:licstar大神的NLP文章 Deep Learning in NLP (一)詞向量和語言模型
正如作者所說:Deep Learning 演算法已經在影象和音訊領域取得了驚人的成果,但是在 NLP 領域中尚未見到如此激動人心的結果。有一種說法是,語言(詞、句子、篇章等)屬於人類認知過程中產生的高層認知抽象實體,而語音和影象屬於較為底層的原始輸入訊號,所以後兩者更適合做deep learning來學習特徵。
但是將詞用“詞向量”的方式表示可謂是將 Deep Learning 演算法引入 NLP 領域的一個核心技術。自然語言理解問題轉化為機器學習問題的第一步都是通過一種方法把這些符號數學化。
詞向量具有良好的語義特性,是表示詞語特徵的常用方式。詞向量的每一維的值代表一個具有一定的語義和語法上解釋的特徵。故可以將詞向量的每一維稱為一個詞語特徵。詞向量用Distributed Representation表示,一種低維實數向量。
例如,NLP中最直觀、最常用的詞表示方法是One-hot Representation。每個詞用一個很長的向量表示,向量的維度表示詞表大小,絕大多數是0,只有一個維度是1,代表當前詞。
“話筒”表示為 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] 即從0開始話筒記為3。
但這種One-hot Representation採用稀疏矩陣的方式表示詞,在解決某些任務時會造成維數災難,而使用低維的詞向量就很好的解決了該問題。同時從實踐上看,高維的特徵如果要套用Deep Learning,其複雜度幾乎是難以接受的,因此低維的詞向量在這裡也飽受追捧。
Distributed Representation低維實數向量,如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。它讓相似或相關的詞在距離上更加接近。
總之,Distributed Representation是一個稠密、低維的實數限量,它的每一維表示詞語的一個潛在特徵,該特徵捕獲了有用的句法和語義特徵。其特點是將詞語的不同句法和語義特徵分佈到它的每一個維度上去表示。
推薦我前面的基礎文章:Python簡單實現基於VSM的餘弦相似度計算
(4) Word2vec
參考:Word2vec的核心架構及其應用 · 熊富林,鄧怡豪,唐曉晟 · 北郵2015年
Word2vec是Google公司在2013年開放的一款用於訓練詞向量的軟體工具。它根據給定的語料庫,通過優化後的訓練模型快速有效的將一個詞語表達成向量形式,其核心架構包括CBOW和Skip-gram。
在開始之前,引入模型複雜度,定義如下:
O = E * T * Q
其中,E表示訓練的次數,T表示訓練語料中詞的個數,Q因模型而異。E值不是我們關心的內容,T與訓練語料有關,其值越大模型就越準確,Q在下面講述具體模型是討論。
NNLM模型是神經網路概率語言模型的基礎模型。在NNLM模型中,從隱含層到輸出層的計算時主要影響訓練效率的地方,CBOW和Skip-gram模型考慮去掉隱含層。實踐證明新訓練的詞向量的精確度可能不如NNLM模型(具有隱含層),但可以通過增加訓練語料的方法來完善。
Word2vec包含兩種訓練模型,分別是CBOW和Skip_gram(輸入層、發射層、輸出層),如下圖所示:
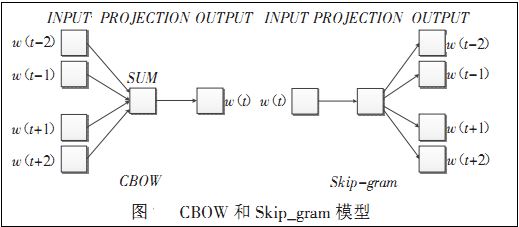
CBOW模型:
理解為上下文決定當前詞出現的概率。在CBOW模型中,上下文所有的詞對當前詞出現概率的影響的權重是一樣的,因此叫CBOW(continuous bag-of-words model)模型。如在袋子中取詞,取出數量足夠的詞就可以了,至於取出的先後順序是無關緊要的。
Skip-gram模型:
Skip-gram模型是一個簡單實用的模型。為什麼會提出該問題呢?
在NLP中,語料的選取是一個相當重要的問題。
首先,語料必須充分。一方面詞典的詞量要足夠大,另一方面儘可能地包含反映詞語之間關係的句子,如“魚在水中游”這種句式在語料中儘可能地多,模型才能學習到該句中的語義和語法關係,這和人類學習自然語言是一個道理,重複次數多了,也就會模型了。
其次,語料必須準確。所選取的語料能夠正確反映該語言的語義和語法關係。如中文的《人民日報》比較準確。但更多時候不是語料選取引發準確性問題,而是處理的方法。
由於視窗大小的限制,這會導致超出視窗的詞語與當前詞之間的關係不能正確地反映到模型中,如果單純擴大視窗大小會增加訓練的複雜度。Skip-gram模型的提出很好解決了這些問題。
Skip-gram表示“跳過某些符號”。例如句子“中國足球踢得真是太爛了”有4個3元片語,分別是“中國足球踢得”、“足球踢得真是”、“踢得真是太爛”、“真是太爛了”,句子的本意都是“中國足球太爛”,可是上面4個3元組並不能反映出這個資訊。
此時,使用Skip-gram模型允許某些詞被跳過,因此可組成“中國足球太爛”這個3元片語。如果允許跳過2個詞,即2-Skip-gram,那麼上句話組成的3元片語為:

由上表可知:一方面Skip-gram反映了句子的真實意思,在新組成的這18個3元片語中,有8個片語能夠正確反映例句中的真實意思;另一方面,擴大了語料,3元片語由原來的4個擴充套件到了18個。
語料的擴充套件能夠提高訓練的準確度,獲得的詞向量更能反映真實的文字含義。
PS:最後附有word2vec原始碼、三大百科語料、騰訊新聞語料和分詞python程式碼。
中文語料可以參考我的文章,通過Python下載百度百科、互動百科、維基百科的內容。
[python] lantern訪問中文維基百科及selenium爬取維基百科語料
[Python爬蟲] Selenium獲取百度百科旅遊景點的InfoBox訊息盒
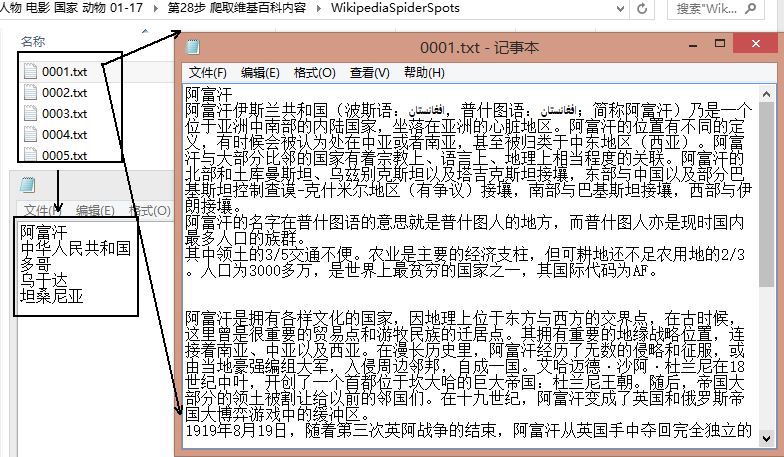
下載結果如下圖所示,共300個國家,百度百科、互動百科、維基百科各自100個,對應的編號都是0001.txt~0100.txt,每個txt中包含一個實體(國家)的資訊。
然後再使用Jieba分詞工具對齊進行中文分詞和文件合併。
上面只顯示了對百度百科100個國家進行分詞的程式碼,但核心程式碼一樣。同時,如果需要對停用詞過濾或標點符號過濾可以自定義實現。
分詞詳見: [python] 使用Jieba工具中文分詞及文字聚類概念
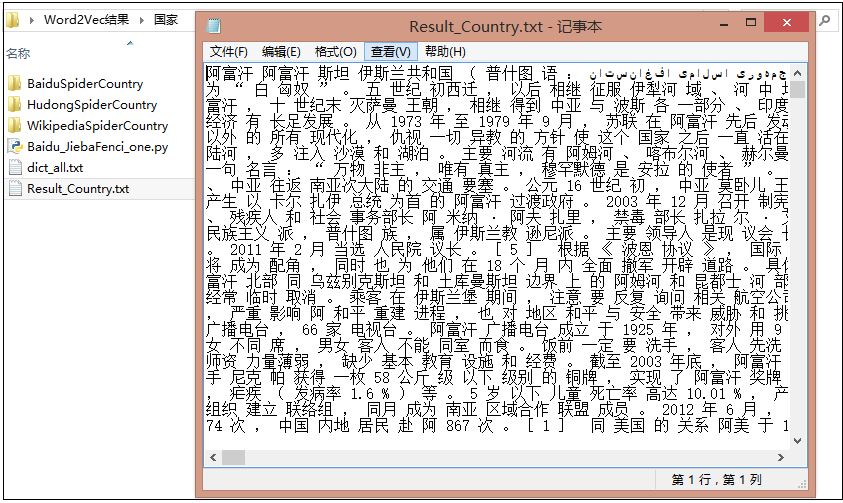
分詞合併後的結果為Result_Country.txt,相當於600行,每行對應一個分詞後的國家。
因為word2vec需要linux環境,所有首先在windows下安裝linux環境模擬器,推薦cygwin。然後把語料Result_Country.txt放入word2vec目錄下,修改demo-word.sh檔案,該檔案預設情況下使用自帶的text8資料進行訓練,如果訓練資料不存在,則會進行下載,因為需要使用自己的資料進行訓練,故註釋掉下載程式碼。
demo-word.sh檔案修改如下:

執行命令sh demo-word.sh,等待訓練完成。模型訓練完成之後,得到了vectors.bin這個詞向量檔案,可以直接運用。
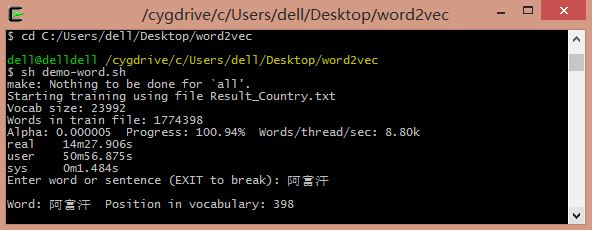
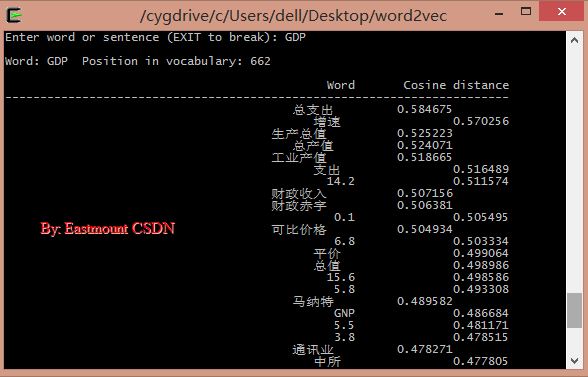
輸入阿富汗:喀布林(首都)、坎大哈(主要城市)、吉爾吉斯斯坦、伊拉克等。
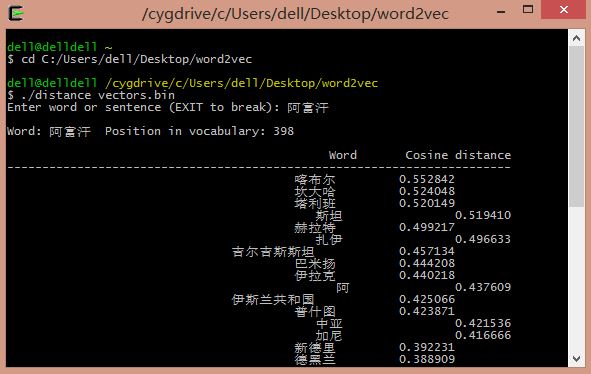
輸入國歌:
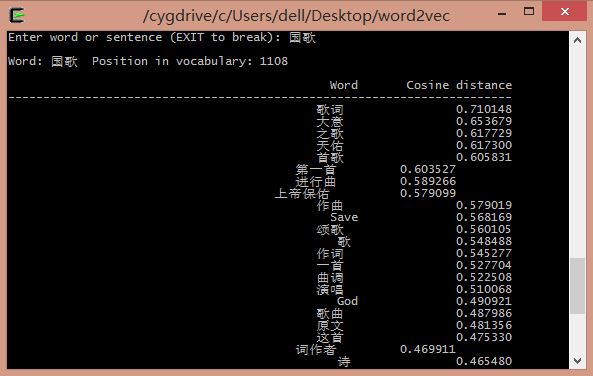
輸入首都:
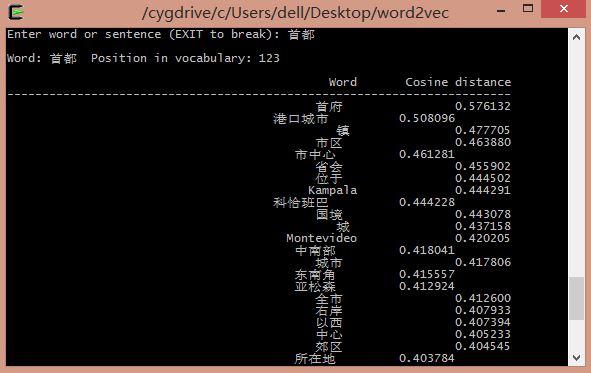
輸入GDP:
官網C語言下載地址:http://word2vec.googlecode.com/svn/trunk/
官網Python下載地址:http://radimrehurek.com/gensim/models/word2vec.html
1.簡單介紹
參考:《Word2vec的核心架構及其應用 · 熊富林,鄧怡豪,唐曉晟 · 北郵2015年》
《Word2vec的工作原理及應用探究 · 周練 · 西安電子科技大學2014年》
《Word2vec對中文詞進行聚類的研究 · 鄭文超,徐鵬 · 北京郵電大學2013年》
PS:第一部分主要是給大家引入基礎內容作鋪墊,這類文章很多,希望大家自己去學習更多更好的基礎內容,這篇部落格主要是介紹Word2Vec對中文文字的用法。
(1) 統計語言模型
統計語言模型的一般形式是給定已知的一組詞,求解下一個詞的條件概率。形式如下:
統計語言模型的一般形式直觀、準確,n元模型中假設在不改變詞語在上下文中的順序前提下,距離相近的詞語關係越近,距離較遠的關聯度越遠,當距離足夠遠時,詞語之間則沒有關聯度。
但該模型沒有完全利用語料的資訊:
1) 沒有考慮距離更遠的詞語與當前詞的關係,即超出範圍n的詞被忽略了,而這兩者很可能有關係的。
例如,“華盛頓是美國的首都”是當前語句,隔了大於n個詞的地方又出現了“北京是中國的首都”,在n元模型中“華盛頓”和“北京”是沒有關係的,然而這兩個句子卻隱含了語法及語義關係,即”華盛頓“和“北京”都是名詞,並且分別是美國和中國的首都。
2) 忽略了詞語之間的相似性,即上述模型無法考慮詞語的語法關係。
例如,語料中的“魚在水中游”應該能夠幫助我們產生“馬在草原上跑”這樣的句子,因為兩個句子中“魚”和“馬”、“水”和“草原”、“遊”和“跑”、“中”和“上”具有相同的語法特性。
而在神經網路概率語言模型中,這兩種資訊將充分利用到。
(2) 神經網路概率語言模型
神經網路概率語言模型是一種新興的自然語言處理演算法,該模型通過學習訓練語料獲取詞向量和概率密度函式,詞向量是多維實數向量,向量中包含了自然語言中的語義和語法關係,詞向量之間餘弦距離的大小代表了詞語之間關係的遠近,詞向量的加減運算則是計算機在"遣詞造句"。
神經網路概率語言模型經歷了很長的發展階段,由Bengio等人2003年提出的神經網路語言模型NNLM(Neural network language model)最為知名,以後的發展工作都參照此模型進行。歷經十餘年的研究,神經網路概率語言模型有了很大發展。
如今在架構方面有比NNLM更簡單的CBOW模型、Skip-gram模型;其次在訓練方面,出現了Hierarchical Softmax演算法、負取樣演算法(Negative Sampling),以及為了減小頻繁詞對結果準確性和訓練速度的影響而引入的欠取樣(Subsumpling)技術。
上圖是基於三層神經網路的自然語言估計模型NNLM(Neural Network Language Model)。NNLM可以計算某一個上下文的下一個詞為wi的概率,即(wi=i|context),詞向量是其訓練的副產物。NNLM根據語料庫C生成對應的詞彙表V。
神將網路知識可以參考我的前文部落格:神經網路和機器學習基礎入門分享
NNLM推薦Rachel-Zhang大神文章:word2vec——高效word特徵求取
近年來,神經網路概率語言模型發展迅速,Word2vec是最新技術理論的合集。
Word2vec是Google公司在2013年開放的一款用於訓練詞向量的軟體工具。所以,在講述word2vec之前,先給大家介紹詞向量的概念。
(3) 詞向量
參考:licstar大神的NLP文章 Deep Learning in NLP (一)詞向量和語言模型
正如作者所說:Deep Learning 演算法已經在影象和音訊領域取得了驚人的成果,但是在 NLP 領域中尚未見到如此激動人心的結果。有一種說法是,語言(詞、句子、篇章等)屬於人類認知過程中產生的高層認知抽象實體,而語音和影象屬於較為底層的原始輸入訊號,所以後兩者更適合做deep learning來學習特徵。
但是將詞用“詞向量”的方式表示可謂是將 Deep Learning 演算法引入 NLP 領域的一個核心技術。自然語言理解問題轉化為機器學習問題的第一步都是通過一種方法把這些符號數學化。
詞向量具有良好的語義特性,是表示詞語特徵的常用方式。詞向量的每一維的值代表一個具有一定的語義和語法上解釋的特徵。故可以將詞向量的每一維稱為一個詞語特徵。詞向量用Distributed Representation表示,一種低維實數向量。
例如,NLP中最直觀、最常用的詞表示方法是One-hot Representation。每個詞用一個很長的向量表示,向量的維度表示詞表大小,絕大多數是0,只有一個維度是1,代表當前詞。
“話筒”表示為 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] 即從0開始話筒記為3。
但這種One-hot Representation採用稀疏矩陣的方式表示詞,在解決某些任務時會造成維數災難,而使用低維的詞向量就很好的解決了該問題。同時從實踐上看,高維的特徵如果要套用Deep Learning,其複雜度幾乎是難以接受的,因此低維的詞向量在這裡也飽受追捧。
Distributed Representation低維實數向量,如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。它讓相似或相關的詞在距離上更加接近。
總之,Distributed Representation是一個稠密、低維的實數限量,它的每一維表示詞語的一個潛在特徵,該特徵捕獲了有用的句法和語義特徵。其特點是將詞語的不同句法和語義特徵分佈到它的每一個維度上去表示。
推薦我前面的基礎文章:Python簡單實現基於VSM的餘弦相似度計算
(4) Word2vec
參考:Word2vec的核心架構及其應用 · 熊富林,鄧怡豪,唐曉晟 · 北郵2015年
Word2vec是Google公司在2013年開放的一款用於訓練詞向量的軟體工具。它根據給定的語料庫,通過優化後的訓練模型快速有效的將一個詞語表達成向量形式,其核心架構包括CBOW和Skip-gram。
在開始之前,引入模型複雜度,定義如下:
O = E * T * Q
其中,E表示訓練的次數,T表示訓練語料中詞的個數,Q因模型而異。E值不是我們關心的內容,T與訓練語料有關,其值越大模型就越準確,Q在下面講述具體模型是討論。
NNLM模型是神經網路概率語言模型的基礎模型。在NNLM模型中,從隱含層到輸出層的計算時主要影響訓練效率的地方,CBOW和Skip-gram模型考慮去掉隱含層。實踐證明新訓練的詞向量的精確度可能不如NNLM模型(具有隱含層),但可以通過增加訓練語料的方法來完善。
Word2vec包含兩種訓練模型,分別是CBOW和Skip_gram(輸入層、發射層、輸出層),如下圖所示:
CBOW模型:
理解為上下文決定當前詞出現的概率。在CBOW模型中,上下文所有的詞對當前詞出現概率的影響的權重是一樣的,因此叫CBOW(continuous bag-of-words model)模型。如在袋子中取詞,取出數量足夠的詞就可以了,至於取出的先後順序是無關緊要的。
Skip-gram模型:
Skip-gram模型是一個簡單實用的模型。為什麼會提出該問題呢?
在NLP中,語料的選取是一個相當重要的問題。
首先,語料必須充分。一方面詞典的詞量要足夠大,另一方面儘可能地包含反映詞語之間關係的句子,如“魚在水中游”這種句式在語料中儘可能地多,模型才能學習到該句中的語義和語法關係,這和人類學習自然語言是一個道理,重複次數多了,也就會模型了。
其次,語料必須準確。所選取的語料能夠正確反映該語言的語義和語法關係。如中文的《人民日報》比較準確。但更多時候不是語料選取引發準確性問題,而是處理的方法。
由於視窗大小的限制,這會導致超出視窗的詞語與當前詞之間的關係不能正確地反映到模型中,如果單純擴大視窗大小會增加訓練的複雜度。Skip-gram模型的提出很好解決了這些問題。
Skip-gram表示“跳過某些符號”。例如句子“中國足球踢得真是太爛了”有4個3元片語,分別是“中國足球踢得”、“足球踢得真是”、“踢得真是太爛”、“真是太爛了”,句子的本意都是“中國足球太爛”,可是上面4個3元組並不能反映出這個資訊。
此時,使用Skip-gram模型允許某些詞被跳過,因此可組成“中國足球太爛”這個3元片語。如果允許跳過2個詞,即2-Skip-gram,那麼上句話組成的3元片語為:
由上表可知:一方面Skip-gram反映了句子的真實意思,在新組成的這18個3元片語中,有8個片語能夠正確反映例句中的真實意思;另一方面,擴大了語料,3元片語由原來的4個擴充套件到了18個。
語料的擴充套件能夠提高訓練的準確度,獲得的詞向量更能反映真實的文字含義。
2.下載原始碼
3.中文語料
PS:最後附有word2vec原始碼、三大百科語料、騰訊新聞語料和分詞python程式碼。
中文語料可以參考我的文章,通過Python下載百度百科、互動百科、維基百科的內容。
[python] lantern訪問中文維基百科及selenium爬取維基百科語料
[Python爬蟲] Selenium獲取百度百科旅遊景點的InfoBox訊息盒
下載結果如下圖所示,共300個國家,百度百科、互動百科、維基百科各自100個,對應的編號都是0001.txt~0100.txt,每個txt中包含一個實體(國家)的資訊。
然後再使用Jieba分詞工具對齊進行中文分詞和文件合併。
#encoding=utf-8
import sys
import re
import codecs
import os
import shutil
import jieba
import jieba.analyse
#匯入自定義詞典
jieba.load_userdict("dict_all.txt")
#Read file and cut
def read_file_cut():
#create path
pathBaidu = "BaiduSpiderCountry\\"
resName = "Result_Country.txt"
if os.path.exists(resName):
os.remove(resName)
result = codecs.open(resName, 'w', 'utf-8')
num = 1
while num<=100: #5A 200 其它100
name = "%04d" % num
fileName = pathBaidu + str(name) + ".txt"
source = open(fileName, 'r')
line = source.readline()
while line!="":
line = line.rstrip('\n')
#line = unicode(line, "utf-8")
seglist = jieba.cut(line,cut_all=False) #精確模式
output = ' '.join(list(seglist)) #空格拼接
#print output
result.write(output + ' ') #空格取代換行'\r\n'
line = source.readline()
else:
print 'End file: ' + str(num)
result.write('\r\n')
source.close()
num = num + 1
else:
print 'End Baidu'
result.close()
#Run function
if __name__ == '__main__':
read_file_cut()
上面只顯示了對百度百科100個國家進行分詞的程式碼,但核心程式碼一樣。同時,如果需要對停用詞過濾或標點符號過濾可以自定義實現。
分詞詳見: [python] 使用Jieba工具中文分詞及文字聚類概念
分詞合併後的結果為Result_Country.txt,相當於600行,每行對應一個分詞後的國家。
4.執行原始碼
因為word2vec需要linux環境,所有首先在windows下安裝linux環境模擬器,推薦cygwin。然後把語料Result_Country.txt放入word2vec目錄下,修改demo-word.sh檔案,該檔案預設情況下使用自帶的text8資料進行訓練,如果訓練資料不存在,則會進行下載,因為需要使用自己的資料進行訓練,故註釋掉下載程式碼。
demo-word.sh檔案修改如下:
make
#if [ ! -e text8 ]; then
# wget http://mattmahoney.net/dc/text8.zip -O text8.gz
# gzip -d text8.gz -f
#fi
time ./word2vec -train Result_Country.txt -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
./distance vectors.bin
執行命令sh demo-word.sh,等待訓練完成。模型訓練完成之後,得到了vectors.bin這個詞向量檔案,可以直接運用。
5.結果展示
通過訓練得到的詞向量我們可以進行相應的自然語言處理工作,比如求相似詞、關鍵詞聚類等。其中word2vec中提供了distance求詞的cosine相似度,並排序。也可以在訓練時,設定-classes引數來指定聚類的簇個數,使用kmeans進行聚類。cd C:/Users/dell/Desktop/word2vec
sh demo-word.sh
./distance vectors.bin 輸入阿富汗:喀布林(首都)、坎大哈(主要城市)、吉爾吉斯斯坦、伊拉克等。
輸入國歌:
輸入首都:
輸入GDP: