
python 評分卡建模記錄---使用到的各種函式(1)
用python評分卡建模過程中使用到的numpy 和pandas中的方法
(一)python選取特定列——pandas的iloc和loc以及icol使用(列切片及行切片)
df是一個dataframe,列名為A B C D
具體值如下:
A B C D
0 ss 小紅 8
1 aa 小明 d
4 f f
6 ak 小紫 7
dataframe裡的屬性是不定的,空值預設為NA。
一、選取標籤為A和C的列,並且選完型別還是dataframe
df = df.loc[:, ['A', 'C']]
df = df.iloc[:, [0, 2]]
二、選取標籤為A/C並且只取前兩行,選完型別還是dataframe
df = df.loc[0:2, ['A', 'C']]
df = df.iloc[0:2, [0, 2]]
聰明的朋友已經看出iloc和loc的不同了:loc是根據dataframe的具體標籤選取列,而iloc是根據標籤所在的位置
","前面的":"表示選取整列,第二個示例中的的0:2表示選取第0行到第二行,這裡的0:2相當於[0,2)前閉後開,2是不在範圍之內
的。
需要注意的是,如果是df = df.loc[0:2, ['A', 'C']]或者df = df.loc[0:2, ['A', 'C']],切片之後型別依舊是dataframe,不能直接進行
加減乘除等操作的,比如dataframe的一列是數學成績(shuxue),另一列為語文成績(yuwen),現在需要求兩門課程的總和。
可以使用df['shuxue'] + df['yuwen'](選取完之後型別為series)來獲得總分,而不能使用df.iloc[:,[2]]+df.iloc[:,[1]]或
df.iloc[:,['shuxue']]+df.iloc[:,['yuwen']],這會產生錯誤結果。
還有一種方式是使用df.icol(i)來選取列,選取完的也不是dataframe而是series,i為該列所在的位置,從0開始計數。
如果你想要選取某一行的資料,可以使用df.loc[[i]]或者df.iloc[[i]]。
三、條件選擇子集(後進行計算)
1.如選擇列‘feature’為‘key’的列‘woe’
feature_bin_woe[feature_bin_woe['feature']=='key']['WOE']
2. 對同一列滿足不同條件行做不同計算
df['a1'] = np.where(df.a1 >0,df['a2']-df['a3'],0)
(二)merge 通過鍵拼接列
pandas提供了一個類似於關係資料庫的連線(join)操作的方法<Strong>merage</Strong>,可以根據一個或多個鍵將不同DataFrame中的行連線起來
語法如下
- merge(left, right, how='inner', on=None, left_on=None, right_on=None,
- left_index=False, right_index=False, sort=True,
- suffixes=('_x', '_y'), copy=True, indicator=False)
用於通過一個或多個鍵將兩個資料集的行連線起來,類似於 SQL 中的 JOIN。該函式的典型應用場景是,針對同一個主鍵存在兩張包含不同欄位的表,現在我們想把他們整合到一張表裡。在此典型情況下,結果集的行數並沒有增加,列數則為兩個元資料的列數和減去連線鍵的數量。
on=None 用於顯示指定列名(鍵名),如果該列在兩個物件上的列名不同,則可以通過 left_on=None, right_on=None 來分別指定。或者想直接使用行索引作為連線鍵的話,就將 left_index=False, right_index=False 設為 True。
how='inner' 引數指的是當左右兩個物件中存在不重合的鍵時,取結果的方式:inner 代表交集;outer 代表並集;left 和 right 分別為取一邊。
suffixes=('_x','_y') 指的是當左右物件中存在除連線鍵外的同名列時,結果集中的區分方式,可以各加一個小尾巴。
對於多對多連線,結果採用的是行的笛卡爾積。
引數說明:
left與right:兩個不同的DataFrame
how:指的是合併(連線)的方式有inner(內連線),left(左外連線),right(右外連線),outer(全外連線);預設為inner
on : 指的是用於連線的列索引名稱。必須存在右右兩個DataFrame物件中,如果沒有指定且其他引數也未指定則以兩個DataFrame的列名交集做為連線鍵
left_on:左則DataFrame中用作連線鍵的列名;這個引數中左右列名不相同,但代表的含義相同時非常有用。
right_on:右則DataFrame中用作 連線鍵的列名
left_index:使用左則DataFrame中的行索引做為連線鍵
right_index:使用右則DataFrame中的行索引做為連線鍵
sort:預設為True,將合併的資料進行排序。在大多數情況下設定為False可以提高效能
suffixes:字串值組成的元組,用於指定當左右DataFrame存在相同列名時在列名後面附加的字尾名稱,預設為('_x','_y')
copy:預設為True,總是將資料複製到資料結構中;大多數情況下設定為False可以提高效能
indicator:在 0.17.0中還增加了一個顯示合併資料中來源情況;如只來自己於左邊(left_only)、兩者(both)
(三)dataframe 分組求和和計數
根據temp列分組後組內對target變數內的列名所指的列計數、求和
total = df2.groupby(['temp'])[target].count()
total = df2.groupby(['temp'])[target].sum()
map根據現有列對映產生新列
df2['temp'] = df2[feature].map(lambda x: AssignGroup(x, split_x))
(四)python DataFrame的apply方法
- #函式應用和對映
- import numpy as np
- import pandas as pd
- df=pd.DataFrame(np.random.randn(4,3),columns=list('bde'),index=['utah','ohio','texas','oregon'])
- print(df)
b d e
utah -0.451195 -0.183451 -0.297182
ohio 0.443792 0.925751 -1.320857
texas 1.039534 -0.927392 0.611482
oregon 0.938760 1.265244 0.313582
- #將函式應用到由各列或行形成的一維陣列上。DataFrame的apply方法可以實現此功能
- f=lambda x:x.max()-x.min()
- #預設情況下會以列為單位,分別對列應用函式
- t1=df.apply(f)
- print(t1)
- t2=df.apply(f,axis=1)
- print(t2)
b 1.490729
d 2.192636
e 1.932339
dtype: float64
utah 0.267744
ohio 2.246608
texas 1.966925
oregon 0.951662
dtype: float64- #除標量外,傳遞給apply的函式還可以返回由多個值組成的Series
- def f(x):
- return pd.Series([x.min(),x.max()],index=['min','max'])
- t3=df.apply(f)
- #從執行的結果可以看出,按列呼叫的順序,呼叫函式執行的結果在右邊依次追加
- print(t3)
b d e
min -0.451195 -0.927392 -1.320857
max 1.039534 1.265244 0.611482
- #元素級的python函式,將函式應用到每一個元素
- #將DataFrame中的各個浮點值保留兩位小數
- f=lambda x: '%.2f'%x
- t3=df.applymap(f)
- print(t3)
b d e
utah -0.45 -0.18 -0.30
ohio 0.44 0.93 -1.32
texas 1.04 -0.93 0.61
oregon 0.94 1.27 0.31
- #注意,這裡之所以叫applymap,是因為Series有一個永遠元素級函式的map方法
- t4=df['e'].map(f)
- print(t4)
utah -0.30
ohio -1.32
texas 0.61
oregon 0.31
Name: e, dtype: object(五)dataframe的set_index和reset_index
1.set_index
DataFrame可以通過set_index方法,可以設定單索引和複合索引。
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
append新增新索引,drop為False,inplace為True時,索引將會還原為列
- In [307]: data
- Out[307]:
- a b c d
- 0 bar one z 1.0
- 1 bar two y 2.0
- 2 foo one x 3.0
- 3 foo two w 4.0
- In [308]: indexed1 = data.set_index('c')
- In [309]: indexed1
- Out[309]:
- a b d
- c
- z bar one 1.0
- y bar two 2.0
- x foo one 3.0
- w foo two 4.0
- In [310]: indexed2 = data.set_index(['a', 'b'])
- In [311]: indexed2
- Out[311]:
- c d
- a b
- bar one z 1.0
- two y 2.0
- foo one x 3.0
- two w 4.0
2.reset_index
reset_index可以還原索引,從新變為預設的整型索引
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
level控制了具體要還原的那個等級的索引
drop為False則索引列會被還原為普通列,否則會丟失
- In [318]: data
- Out[318]:
- c d
- a b
- bar one z 1.0
- two y 2.0
- foo one x 3.0
- two w 4.0
- In [319]: data.reset_index()
- Out[319]:
- a b c d
- 0 bar one z 1.0
- 1 bar two y 2.0
- 2 foo one x 3.0
- 3 foo two w 4.0
pandas contact 之後,一定要記得用reset_index去處理index,不然容易出現莫名的邏輯錯誤
如下:
- # -*- coding: utf-8 -*-
- import pandas as pd
- import sys
- df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],
- 'B': ['B0', 'B1', 'B2', 'B3'],
- 'C': ['C0', 'C1', 'C2', 'C3'],
- 'D': ['D0', 'D1', 'D2', 'D3']})
- df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
- 'B': ['B4', 'B5', 'B6', 'B7'],
- 'C': ['C4', 'C5', 'C6', 'C7'],
- 'D': ['D4', 'D5', 'D6', 'D7']})
- df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
- 'B': ['B8', 'B9', 'B10', 'B11'],
- 'C': ['C8', 'C9', 'C10', 'C11'],
- 'D': ['D8', 'D9', 'D10', 'D11']})
- frames = [df1, df2, df3]
- result = pd.concat(frames)
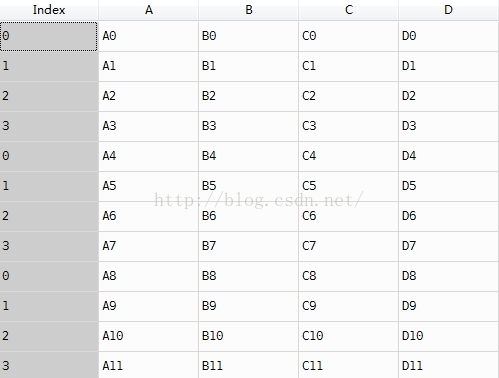
說明:直接contact之後,index只是重複,而不是變成我們希望的那樣,這樣在後續的操作中,容易出現邏輯錯誤。
使用result = result.reset_index(drop=True)來改變index就可以了,
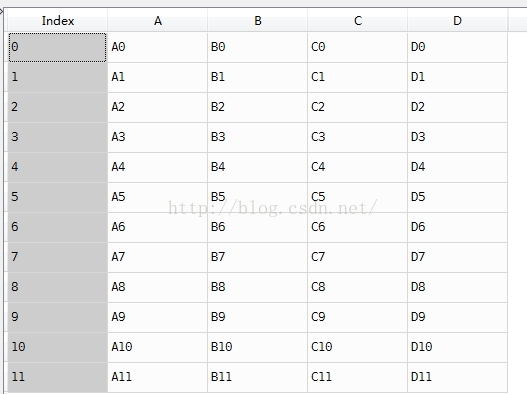
或者也可以將 result = pd.concat(frames)
這句話改成 result = pd.concat(frames,ignore_index=True),就可以解決了
(六)DataFrame.to_dict(orient='dict')
將DataFrame格式的資料轉化成字典形式
引數:當然引數orient可以是字串{'dict', 'list', 'series', 'split', 'records', 'index'}中的任意一種來決定字典中值的型別
字典dict(預設):類似於{列:{索引:值}}這樣格式的字典
列表list:類似於{列:[值]}這種形式的字典
序列series:類似於{列:序列(值)}這種形式的字典
分解split:類似於{索引:[索引],列:[列],資料:[值]}這種形式的字典
記錄records:類似於[{列:值},...,{列:值}]這種形式的列表
索引index:類似於{索引:{列:值}}這種形式的字典
在新版本0.17.0中,允許縮寫,s表示序列,sp表示分裂
返回:結果:像{列:{索引:值}}這種形式的字典
比如當關鍵字orient=’index’ 時
形成{index -> {column -> value}}的結構,呼叫格式正好和’dict’ 對應的反過來,
data_index=data.to_dict(orient='index')
data_index
Out[43]:
{12: {'age': 31.19418104265403,
'embarked': 'Cherbourg',
'home.dest': 'Paris, France',
'pclass': '1st',
'sex': 'female'},
437: {'age': 48.0,
'embarked': 'Southampton',
'home.dest': 'Somerset / Bernardsville, NJ',
'pclass': '2nd',
'sex': 'female'},
507: {'age': 31.19418104265403,
'embarked': 'Southampton',
'home.dest': 'Petworth, Sussex',
'pclass': '2nd',
'sex': 'male'}}