
論文筆記:Feature Pyramid Networks for Object Detection
初衷
Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, we exploit the inherent multi-scale,pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost.
簡而言之就是特徵金字塔一直很好用,只是費時費力,我們提出了一直很好的方法可以高效地使用特徵金字塔。
介紹
一些用feature pyramid的方法:
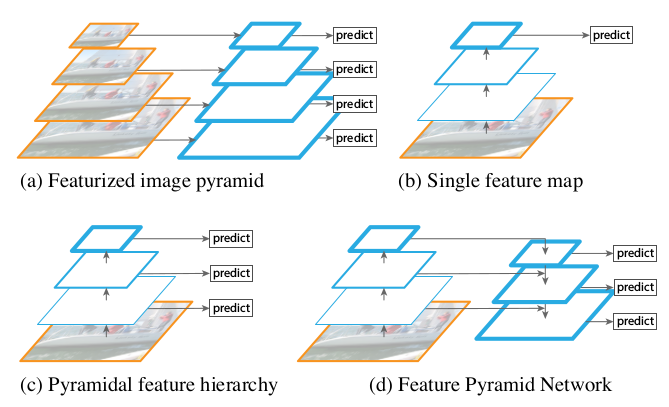
- 用圖片金字塔生成特徵金字塔
- 只在特徵最上層預測
- 特徵層分層預測
- FPN從高層攜帶資訊傳給底層,再分層預測
We rely on an architecture that combines low-resolution, semantically strong features with high-resolution, semantically weak features via a top-down pathway and lateral connections .
作者闡釋他這樣做的好處,就是融合底層細節和高層概括。
Similar architectures adopting top-down and skip connections are popular in recent research. Their goals are to produce a single high-level feature map of a fine resolution, on which the predictions are to be made.
很多人多想到過融合,但是他們沒有分層預測。。。。
Feature Pyramid Networks
目標
Our method takes a single-scale image of an arbitrary size as input, and outputs proportionally sized feature maps at multiple levels, in a fully convolutional fashion.
實現
Bottom-up pathway

Specifically, for ResNets we use the feature activations output by each stage’s last residual block. We denote the output of these last residual blocks as {C 2 , C 3 , C 4 , C 5 } for conv2, conv3, conv4, and conv5 outputs, and note that they have strides of {4, 8, 16, 32} pixels with respect to the input image. We do not include conv1 into the pyramid due to its large memory footprint.
自底向上的過程就是神經網路普通的正向傳播。考慮到後的步驟,要逐層抽取特徵。那些feature map大小相同的地方,只抽取最上層。在試驗中,用的ResNets的卷積層,分為了{C1,C2,C3,C4,C5}用了C2,C3,C4,C5的feature map。不用C1,因為太大了。
Top-down pathway and lateral connections

With a coarser-resolution feature map, we upsample the spatial resolution by a factor of 2 (using nearest neighbor upsampling for simplicity). The upsampled map is then merged with the corresponding bottom-up map (which undergoes a 1×1 convolutional layer to reduce channel dimensions) by element-wise addition.
上層feature map上取樣和下層一樣大,下層的經過1×1卷積核使得維度和上層一樣,之後按元素相加。
To start the iteration, we simply attach a 1×1 convolutional layer on C 5 to produce the coarsest resolution map.
為了開始這個操作,我們的最上面的feature map是通過1×1的卷積核生成的。
Finally, we append a 3×3 convolution on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling. This final set of feature maps is called {P 2 , P 3 , P 4 , P 5 }, corresponding to {C 2 , C 3 , C 4 , C 5 } that are respectively of the same spatial sizes.
為了減少混疊效應帶來的影響,每層還經過一個3×3的卷積核生成最後的feature map,記作{P 2 , P 3 , P 4 , P 5 }。
應用
RPN
We adapt RPN by replacing the single-scale feature map with our FPN. We attach a head of the same design (3×3 conv and two sibling 1×1 convs) to each level on our feature pyramid.
將原來的小網路接在每一層上。引數共享
Because the head slides densely over all locations in all pyramid levels, it is not necessary to have multi-scale anchors on a specific level. Instead, we assign anchors of a single scale to each level. Formally, we define the anchors to have areas of {
322,642,1282,2562,5122 } pixels on {P 2 , P 3 , P 4 , P 5 , P 6 } respectively. 1 As in [28] we also use anchors of multiple aspect ratios {1:2, 1:1, 2:1} at each level. So in total there are 15 anchors over the pyramid.
anchor 的長寬比就不用改了,因為每層都不一樣大。其實這樣有15anchors,比之前的9個還要多呢。
Fast R-CNN
選取合適大小的feature map。通過下面的式子計算用哪一層的特徵: