
Feature Pyramid Networks for Object Detection論文筆記
阿新 • • 發佈:2018-11-17
1、摘要
Feature pyramids are a basic component in recognition systems for detecting objects at diferent scales.But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive.In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost.【好用但是開銷大,paper提出一個方法來少開銷的使用】
2、簡介
一些使用pyramid方法
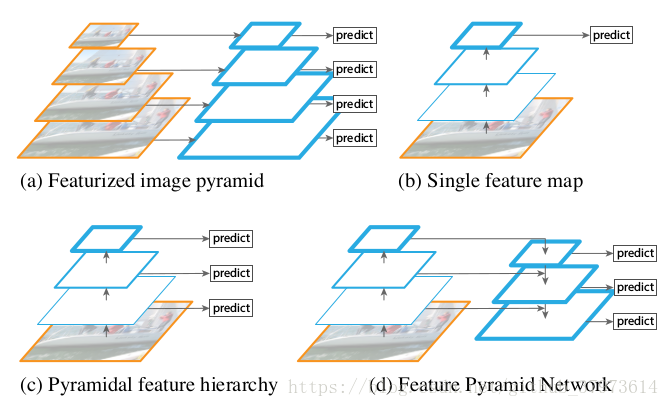
藍色框代表feature map,框的線條越粗,其語義表達能力越強。我們可以獲取輸入影象的不同的尺寸,並在不同尺度上提取特徵(如:SIFT、HOG),然後進行目標的預測。【參考】
- (a)用圖片金字塔生成特徵金字塔,在非深度的方法中比較常見,通過將圖片放縮到不同的大小,這樣一些類似於固定滑窗的方法就可以檢測到不同大小的物體,這個記憶體和時間上有巨大的開銷。因為CNN提取特徵十分的耗時。
- (b)只在特徵最上層進行預測【(b)展示了現在深度學習方法的常用策略,用深度網路提取feature maps代替了傳統方法提取feature maps,深度網路提取的特徵表達能力更強,從低層到高層的過程中,語義逐漸加強,我們直接在且僅在最後一層進行predict。CNN卷積操作考察的是區域性畫素之間的關聯性、池化操作則是對區域性資訊進行統計,因此CNN越top,feature map中的每個單元格的感受野就越大,相對的,就沒有淺層那麼精細,解析度就會下降得比較厲害,這個問題將在小目標比較突出。】
- (c)特徵層分層預測【SSD-Style的單線,每層分別predict;沒能重複利用上大的feature map,對小目標檢測效果不好。在高層這種感受野比較大的層上預測scale比較大的物體,在淺層這種感受野比較小的層上預測scale比較小的物體,但是這樣會導致一個問題,淺層解析度雖然比較高,但是語義化層度不高,去預測小目標的效果還是不好。】
- (d)FPN從高層攜帶資訊傳給底層,再分層預測,本文所使用的【we rely on an architecture that combines low-resolution, semantically strong feature with high-resolution, semantically weak features via a top-down pathway and lateral connections. The result is a feature pyramid that has rich semantics at all levels and is built quickly from a single input image scale.】鑑於(c),FPN使用d,就是在達到了top層高語義後,再通過不斷地進行upsample,然後和CNN網路中的淺層的特徵融合,融合後的特徵既有較高的語義性,也有較高的解析度,這樣再去分別預測不同scale的物體就會有比較好的效果。在實際使用的時候,作者的特徵是across scales的,換句話說,在預測某個scale目標的時候,其他scale的特徵也會起到一定的作用,這就是FPN的整體思路。
3、FPN building block
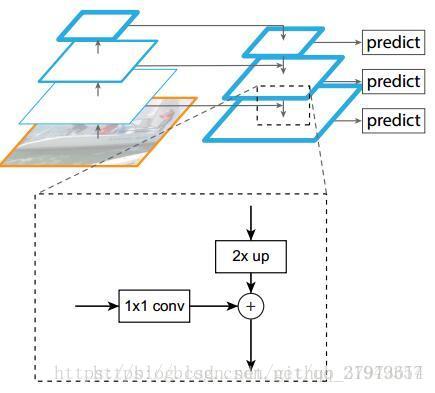
很明顯有三條線,分別為:左邊是Bottom-up pathway,上面是top-down pathway,最後將他們融合起來得到下面的lateral connections:
- bottom-up路線:作者使用了ResNet作為基礎網路,對於本文的特徵金字塔, 作者為每個階段定義一個金字塔級別,然後選擇每個階段的最後一層的輸出作為特徵圖的參考集【因為ResNet網路有非常多的層(20 or 101),那麼將所有層分成幾個階段,取每個階段的最後一個層來最為金字塔中的
】。這種選擇很自然的,因為每個階段的最深層應該具有最強的特徵。具體來說,對於ResNets,作者使用了每個階段的最後一個殘差結構的特徵啟用輸出。將這些殘差模組輸出表示為{C2, C3, C4, C5},對應於conv2, conv3, conv4和conv5的輸出,並且注意它們相對於輸入影象具有{4, 8, 16, 32}畫素的步長。考慮到記憶體佔用,沒有將conv1包含在金字塔裡。
- Top-down路線和橫向連線:如何去結合低層高解析度的特徵,方法就是把更加抽象、語義更強的高層特徵圖進行上取樣(upsample),然後把該特徵橫向連線(lateral connections)至前一個特徵,因此高層特徵得到加強。值得注意的是,橫向連線的兩層特徵在空間尺寸上要相同。這樣做應該主要是為了利用底層的定位細節資訊。
- 上面圖中顯示了連線細節,把高層特徵做2倍上取樣(最近鄰上取樣法),然後將其和對應的bottom-up上的特徵結合(bottom-up上的特徵需要經過1*1卷積處理,目的是為了改變channels,和Top-down上的相同),結合方式是做畫素間的加法。重複迭代此過程,直至生成最精細的特徵圖。迭代開始階段,作者在C5層後面加上一個1*1的卷積核來產生最粗略的特徵圖,最後,作者用3*3的卷積核去處理已經融合的特徵圖(為了消除上取樣的混疊效應),以生成最後需要的特徵圖。{C2,C3,C4,C5}層對應的融合特徵層為{P2,P3,P4,P5},對應的層空間尺寸是相通的。
- 金字塔結構中所有層級共享分類層(迴歸層),就像featurized image pyramid中所做的那樣。作者固定所有特徵圖中的維度(通道數,表示為d)。作者在本文中設定d=256,因此所有核外的卷積層(比如P2)具有256通道輸出。這些額外層沒有用非線性,而非線性會帶來一些影響。
4、還有個FPN與fast RCNN部分【摘自here】


在程式碼中的一些實現過程(tensorflow):

(實際中的層數可能不是圖中所表示,一般因為C1佔用記憶體太多而不包括進金字塔層)
- 怎麼做上取樣?
- 首先上面的block左邊是一個resnet的過程,右邊是一個upsample,兩個部分有特徵融合。C5是ResNet最頂層的輸出,它會通過一個1*1的卷積層,把通道數轉為256,得到FPN的最上面一層P5。
- 如何做橫向連線以及作用?
- P4是上取樣之後的P5與1*1卷積之後的C4的畫素相加。先要把P5和C4轉換到一樣的尺度,再直接進行相加。
- 作用:如果不進行特徵的融合(即去掉所有的側連線,雖然理論上解析度是沒有變的,語義也增強了,但是AR下降了10%左右,作者認為這是因為特徵上下采樣他多次,導致他們不適於定位。Bottom-up即左邊的ResNet部分包含了更加精確的位置資訊。)
- P2-P5最後又作了一次3*3的卷積,作用是消除上取樣帶來的混疊效應。
- 金字塔結構中所有層級共享分類層是怎麼回事?
- 每個ROI都在P2-P5中的某一層得到了一個特徵,然後送到了同一個分類和迴歸網路得到最終結果。
- FPN中每一層的heads引數都是共享的,作者認為共享引數的效果也不錯就說明FPN中所有層的語義都相似。
- 本文的思想?
- 把高層的特徵傳下來,補充低層的語義,這樣就可以獲得高解析度和強語義,有利於對各種scale的目標的檢測。
- 不同尺度的ROI,使用不同特徵層作為ROI pooling層的輸入,大尺度ROI就用後面一些的金字塔層,比如P5【因為同樣大小的anchor,如果在高語義部分,即在如P5這種上層,那麼映射回原圖的部分會更大】,小尺度ROI就用前面一點的特徵層,比如P4(因為上面說過了,要用感受野比較大的高層去預測scale大的物體,而感受野比較小的去預測比較小的物體)。那如何判斷ROI該用哪個層的輸出呢?paper中用瞭如下公式,但是程式碼做了更改,替換為roi_level:
- FPN是基於一個主幹模型的,比如ResNet。常見的命名方式是:主幹網路-層數-FPN,例如:ResNet-101-FPN。