
【123】TensorFlow 多個特徵值線性迴歸,並且使用訓練集、驗證集和測試集的例子
阿新 • • 發佈:2018-12-26
我們的目標是構建數學模型來預測房價。通常情況下,會有多個因素影響房價,因此使用多個特徵值做線性迴歸。數學上,每個特徵值視為一個自變數,相當與構建一個包含多個自變數的函式。

我寫了兩個 python 檔案,一個是用來訓練模型,並使用驗證集驗證模型。另一個是用測試集測試我的數學模型。
在程式中,使用到的特徵值是這些:latitude、 longitude、
housing_median_age、total_rooms、 total_bedrooms、population、 households、 median_income 和 rooms_per_person
訓練模型的檔案:
import 執行結果如下
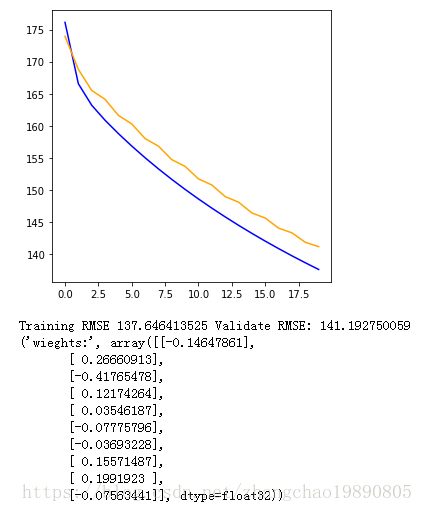
然後我們用測試集來測試模型:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from sklearn import metrics
# 從CSV檔案中讀取資料,返回DataFrame型別的資料集合。
def zc_func_read_csv(zc_param_csv_url):
# zc_var_dataframe = pd.read_csv("http://49.4.2.82/california_housing_train.csv", sep=",")
zc_var_dataframe = pd.read_csv(zc_param_csv_url, sep=",")
# 打亂資料集合的順序。有時候資料檔案有可能是根據某種順序排列的,會影響到我們對資料的處理。
zc_var_dataframe = zc_var_dataframe.reindex(np.random.permutation(zc_var_dataframe.index))
return zc_var_dataframe
# 預處理特徵值
def preprocess_features(california_housing_dataframe):
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]
]
processed_features = selected_features.copy()
# 增加一個新屬性:人均房屋數量。
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
# 預處理標籤
def preprocess_targets(california_housing_dataframe):
output_targets = pd.DataFrame()
# Scale the target to be in units of thousands of dollars.
output_targets["median_house_value"] = (
california_housing_dataframe["median_house_value"] / 1000.0)
return output_targets
# 根據數學模型計算預測值。公式是 y = w0 + w1 * x1 + w2 * x2 .... + w9 * x9
def zc_func_predict(zc_param_dataframe, zc_param_weight_arr):
zc_var_result = []
for var_row_index in zc_param_dataframe.index:
y = zc_param_weight_arr[0]
y = y + zc_param_weight_arr[1] * zc_param_dataframe.loc[var_row_index].values[0]
y = y + zc_param_weight_arr[2] * zc_param_dataframe.loc[var_row_index].values[1]
y = y + zc_param_weight_arr[3] * zc_param_dataframe.loc[var_row_index].values[2]
y = y + zc_param_weight_arr[4] * zc_param_dataframe.loc[var_row_index].values[3]
y = y + zc_param_weight_arr[5] * zc_param_dataframe.loc[var_row_index].values[4]
y = y + zc_param_weight_arr[6] * zc_param_dataframe.loc[var_row_index].values[5]
y = y + zc_param_weight_arr[7] * zc_param_dataframe.loc[var_row_index].values[6]
y = y + zc_param_weight_arr[8] * zc_param_dataframe.loc[var_row_index].values[7]
y = y + zc_param_weight_arr[9] * zc_param_dataframe.loc[var_row_index].values[8]
zc_var_result.append(y)
return zc_var_result
def zc_func_main():
california_housing_dataframe = zc_func_read_csv("http://114.115.223.20/california_housing_train.csv")
# 對於驗證集,我們從共 17000 個樣本中選擇後 5000 個樣本。
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
#print(validation_examples.describe())
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
# 通過訓練得到的模型權重
zc_param_weight_arr = [-0.19103946,0.37296584,-0.7998271,0.25258455,0.03940793,-0.13476478,
-0.04755316,0.20973271,0.00714895,0.02928887]
# 根據已經訓練得到的模型係數,計算預驗證集的測值。
zc_var_validate_predict_arr = zc_func_predict(validation_examples, zc_param_weight_arr)
# 計算驗證集的預測值和標籤之間的均方根誤差。
validation_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(zc_var_validate_predict_arr, validation_targets["median_house_value"]))
print("validation RMSE:", validation_root_mean_squared_error)
# 基於測試集資料進行評估
test_dataframe = zc_func_read_csv("http://114.115.223.20/california_housing_test.csv")
# 測試集的樣本
test_examples = preprocess_features(test_dataframe)
test_targets = preprocess_targets(test_dataframe)
# 計算測試集的預測值
zc_var_test_predict_arr = zc_func_predict(test_examples, zc_param_weight_arr)
# 計算測試集的預測值和標籤之間的均方根誤差。
test_root_mean_squared_error = math.sqrt(
metrics.mean_squared_error(zc_var_test_predict_arr, test_targets["median_house_value"]))
print("test RMSE:", test_root_mean_squared_error)
zc_func_main()執行結果:
('validation RMSE:', 120.00240785178423)
('test RMSE:', 116.6171534701997)