
索引技術--B Tree、B-Tree、B+Tree、紅黑樹、B*Tree
B樹(B-Tree,並不是B“減”樹,橫槓為連線符,容易被誤導)
是一種多路搜尋樹(並不是二叉的):
1.定義任意非葉子結點最多隻有M個兒子;且M>2;
2.根結點的兒子數為[2, M];
3.除根結點以外的非葉子結點的兒子數為[M/2, M];
4.每個結點存放至少M/2-1(取上整)和至多M-1個關鍵字;(至少2個關鍵字)
5.非葉子結點的關鍵字個數=指向兒子的指標個數-1;
6.非葉子結點的關鍵字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非葉子結點的指標:P[1], P[2], …, P[M];其中P[1]指向關鍵字小於K[1]的
子樹,P[M]指向關鍵字大於K[M-1]的子樹,其它P[i]指向關鍵字屬於(K[i-1], K[i])的子樹;
8.所有葉子結點位於同一層;
如:(M=3)
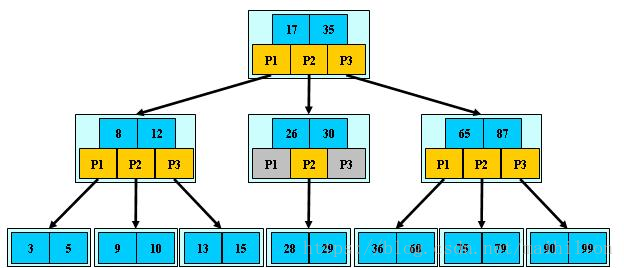
B 樹的搜尋,從根結點開始,對結點內的關鍵字(有序)序列進行二分查詢,如果
命中則結束,否則進入查詢關鍵字所屬範圍的兒子結點;重複,直到所對應的兒子指標為
空,或已經是葉子結點;
B 樹的特性:
1.關鍵字集合分佈在整顆樹中;
2.任何一個關鍵字出現且只出現在一個結點中;
3.搜尋有可能在非葉子結點結束;
4.其搜尋效能等價於在關鍵字全集內做一次二分查詢;
5.自動層次控制;
由於限制了除根結點以外的非葉子結點,至少含有M/2個兒子,確保了結點的至少
利用率,其最底搜尋效能為:
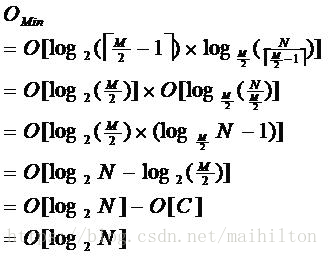
其中,M為設定的非葉子結點最多子樹個數,N為關鍵字總數;
所以B-樹的效能總是等價於二分查詢(與M值無關),也就沒有B樹平衡的問題;
由於M/2的限制,在插入結點時,如果結點已滿,需要將結點分裂為兩個各佔
M/2的結點;刪除結點時,需將兩個不足M/2的兄弟結點合併;
B+樹
B+樹是B-樹的變體,也是一種多路搜尋樹:
其定義基本與B-樹同,除了:
1.非葉子結點的子樹指標與關鍵字個數相同;
2.非葉子結點的子樹指標P[i],指向關鍵字值屬於[K[i], K[i+1])的子樹
(B-樹是開區間);
3.為所有葉子結點增加一個鏈指標;
4.所有關鍵字都在葉子結點出現;
如:(M=3)
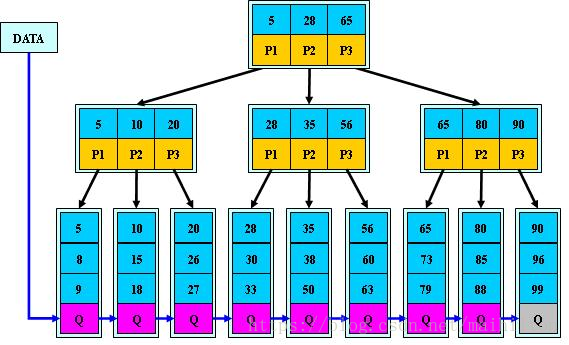
B+的搜尋與B-樹也基本相同,區別是B+樹只有達到葉子結點才命中(B-樹可以在
非葉子結點命中),其效能也等價於在關鍵字全集做一次二分查詢;
B+的特性:
1.所有關鍵字都出現在葉子結點的連結串列中(稠密索引, 聚集索引),且連結串列中的關鍵字恰好
是有序的;
2.不可能在非葉子結點命中;
3.非葉子結點相當於是葉子結點的索引(稀疏索引,非聚集索引),葉子結點相當於是儲存
(關鍵字)資料的資料層;
4.更適合檔案索引系統;
B*樹
是B+樹的變體,在B+樹的非根和非葉子結點再增加指向兄弟的指標;
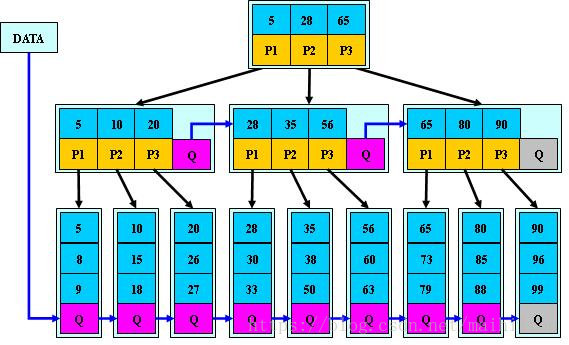
B*樹定義了非葉子結點關鍵字個數至少為(2/3)*M,即塊的最低使用率為2/3
(代替B+樹的1/2);
B+樹的分裂:當一個結點滿時,分配一個新的結點,並將原結點中1/2的資料
複製到新結點,最後在父結點中增加新結點的指標;B+樹的分裂隻影響原結點和父
結點,而不會影響兄弟結點,所以它不需要指向兄弟的指標;
B*樹的分裂:當一個結點滿時,如果它的下一個兄弟結點未滿,那麼將一部分
資料移到兄弟結點中,再在原結點插入關鍵字,最後修改父結點中兄弟結點的關鍵字
(因為兄弟結點的關鍵字範圍改變了);如果兄弟也滿了,則在原結點與兄弟結點之
間增加新結點,並各複製1/3的資料到新結點,最後在父結點增加新結點的指標;
所以,B*樹分配新結點的概率比B+樹要低,空間使用率更高;
紅黑樹
紅黑樹(Red-Black Tree)是二叉搜尋樹(Binary Search Tree)的一種改進。我們知道二叉搜尋樹在最壞的情況下可能會變成一個連結串列(當所有節點按從小到大的順序依次插入後)。而紅黑樹在每一次插入或刪除節點之後都會花O(log N)的時間來對樹的結構作修改,以保持樹的平衡。也就是說,紅黑樹的查詢方法與二叉搜尋樹完全一樣;插入和刪除節點的的方法前半部分節與二叉搜尋樹完全一樣,而後半部分添加了一些修改樹的結構的操作。
紅黑樹的每個節點上的屬性除了有一個key、3個指標:parent、lchild、rchild以外,還多了一個屬性:color。它只能是兩種顏色:紅或黑。而紅黑樹除了具有二叉搜尋樹的所有性質之外,還具有以下4點性質:
1. 根節點是黑色的。
2. 空節點是黑色的(紅黑樹中,根節點的parent以及所有葉節點lchild、rchild都不指向NULL,而是指向一個定義好的空節點)。
3. 紅色節點的父、左子、右子節點都是黑色。
4. 在任何一棵子樹中,每一條從根節點向下走到空節點的路徑上包含的黑色節點數量都相同。
小結
B樹:二叉樹,每個結點只儲存一個關鍵字,等於則命中,小於走左結點,大於
走右結點;
B-樹:多路搜尋樹,每個結點儲存M/2到M個關鍵字,非葉子結點儲存指向關鍵
字範圍的子結點;
所有關鍵字在整顆樹中出現,且只出現一次,非葉子結點可以命中;
B+樹:在B-樹基礎上,為葉子結點增加連結串列指標,所有關鍵字都在葉子結點
中出現,非葉子結點作為葉子結點的索引;B+樹總是到葉子結點才命中;
B*樹:在B+樹基礎上,為非葉子結點也增加連結串列指標,將結點的最低利用率
從1/2提高到2/3;