
資料結構之重要樹總結(紅黑樹、B/B+樹等)
眾所周知,二叉樹在資料結構中的分量舉足輕重。之所以分量如此重,是因為在實際中有很多情況用此資料結構會產生很多好處。本文主要對二叉搜尋樹、平衡二叉樹、紅黑樹、B(B+、B*)樹進行總結,因為這幾種樹的概念十分重要,瞭解它們對於其他學科的知識將會有更進一步的理解。
樹結構優劣最重要的衡量標準就是操作的時間複雜度,而這些操作的時間複雜度與樹的高度成正比。
首先看一張圖
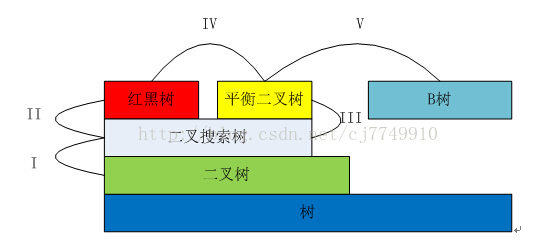
圖1 多種樹的關係概略圖
這張圖概略地描繪了這些樹的關係,I、II、III、IV、V均表示兩種樹之間的關係。以下我會一點一點地講述為什麼會出現這些樹。
首先是樹和二叉樹,這個概念很簡單也很基礎,在此不再贅述,只提一點
從這裡開始進入本文主要內容。
接下來介紹二叉搜尋樹。二叉搜尋樹又稱二叉排序樹、二叉查詢樹。
一、為什麼會出現二叉搜尋樹?
對於資料的操作來說,最主要的無非就是查詢、插入和刪除。
假設我們有一個數據集,它是順序儲存(包括線性表和連結串列兩種方式)的,那麼插入和刪除操作對於這種結構來說,效率是可以接受的,但 是查詢效率呢?一旦資料集中資料無序將使查詢效率很低。那自然我們就想到讓資料集有序,好,請繼續看......
如果資料集是有序的也是順序儲存的,查詢我們就可以採取二分法等來實現,效率確實很提高很多,但 是,也正是因為有序,在插入和刪 除操作上就需要耗費大量時間。這就迫使我們尋找能兼顧查詢、插入和刪除操作效率的方法,於是二叉搜尋樹登場了。
二、二叉搜尋樹與二叉樹的關係(這裡也就是圖1中關係I)
圖1中關係I表示二叉搜尋樹是在二叉樹的基礎上定義的,只不過附加了以下條件(二叉搜尋樹不為空時):
對於任意結點
1、若其左子樹不空,左子樹上所有結點的值均不大於此結點的值;
2、若其右子樹不空,右子樹上所有結點的值均不小於此結點的值;
3、其左右子樹也分別為二叉搜尋樹。
三、二叉搜尋樹效能
最好的時候是完全二叉樹,時間複雜度是O(log2n);最差的時候線性連線的情況,時間複雜度O(n)。
四、二叉搜尋樹操作(操作程式碼此文不表,以下所有同)
操作中查詢和插入都很簡單,難點在於刪除操作,刪除有三種情況: 1、刪除葉子結點; 2、刪除僅有左子樹或者右子樹的結點; 3、刪除既有左子樹又有右子樹的結點。 情況1直接刪除就行,情況2在刪除後將其所存在的那個子樹直接移到刪除結點的位置即可,情況3選取刪除結點的直接前驅(也就是其左子樹中最大值)或者直接後繼(右子樹中最小者)替換刪除結點,習慣上選取直接前驅。 二叉搜尋樹介紹完了,下面開始介紹平衡二叉樹(AVL樹)。一、為什麼需要平衡二叉樹?
由於二叉搜尋樹的最差情況效率並不高,所以想把它構建成一個平衡的二叉搜尋樹,一旦平衡,樹的高度自然降低,操作的時間複雜度也會 降低。二、平衡二叉樹與二叉搜尋樹的關係(這裡也就是圖1中關係III)
圖1中關係II表示平衡二叉樹是在二叉搜尋樹的基礎上定義的,當然也一定是附加了條件: 1、每個結點的左子樹與右子樹的高度差至多等於1。三、平衡二叉樹的效能
是平衡二叉樹查詢、插入和刪除的時間複雜度都是O(log2n),這已經是一種比較理想的一種動態查詢表演算法。目前平衡二叉樹與紅黑樹 在二叉樹中效率已是最佳。四、平衡二叉樹的操作
1、平衡二叉樹有兩個名詞:平衡因子與最小不平衡子樹。這裡解釋一下: 1)平衡因子(BF):二叉樹上結點左子樹深度減去右子樹深度的值。平衡二叉樹上任意結點的BF只可能為-1、0和1。 2)最小不平衡子樹:以距離插入節點最近的且平衡因子的絕對值大於1的結點為根的子樹。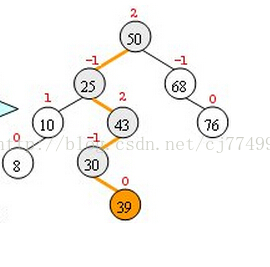 圖2 新插入結點的平衡二叉樹
圖2是我從網上擷取的一個圖片,除開結點39,其他結點構成一個平衡二叉樹。圖2中每個結點上方都有一個數字,這就是平衡因子,如此時 結點50的平衡因子就是2。按照定義結點43、30、39組成了最小不平衡子樹。
2、查詢、插入和刪除
這裡給一個連結,我覺得還是挺好的,挺容易明白的。點選這裡
繼平衡二叉樹之後,下面要講一個和平衡二叉樹關係極為密切的一種樹——紅黑樹。
圖2 新插入結點的平衡二叉樹
圖2是我從網上擷取的一個圖片,除開結點39,其他結點構成一個平衡二叉樹。圖2中每個結點上方都有一個數字,這就是平衡因子,如此時 結點50的平衡因子就是2。按照定義結點43、30、39組成了最小不平衡子樹。
2、查詢、插入和刪除
這裡給一個連結,我覺得還是挺好的,挺容易明白的。點選這裡
繼平衡二叉樹之後,下面要講一個和平衡二叉樹關係極為密切的一種樹——紅黑樹。
一、紅黑樹與二叉搜尋樹的關係(這裡也就是圖1中關係II)
圖1中的關係II表示紅黑樹是在二叉搜尋樹的基礎上定義的,附加的條件如下: 1、結點要麼是黑的,要麼是紅的; 2、根節點是黑的; 3、葉子結點,即NIL結點是黑的; 4、如果一個結點是紅色的,那麼它的兩個兒子幾點是黑色的; 5、對任意結點,從它到葉子結點(NIL)的所有路徑上都有相同數目的黑色結點。二、紅黑樹與平衡二叉樹的關係(這裡也就是圖1中關係IV)
1、紅黑樹與平衡二叉樹整體類似,平衡二叉樹是嚴格的平衡,而紅黑樹放寬了平衡二叉樹的平衡條件,不要求“完全平衡”。平衡二叉樹的平 衡在於平衡因子,而紅黑樹的平衡主要體現在上面的第5條,即基於顏色。引入“顏色”的概念也就是為了簡化平衡條件,降低旋轉的要求,任何不平衡都能在三次旋轉以內解決,所以相對於平衡二叉樹,給我們提供了“比較便宜”的方案。 2、二者的插入、刪除和查詢操作的時間複雜度均為O(log2n)。 3、紅黑樹的統計效能要好於平衡二叉樹,這也是STL中map和set使用紅黑樹實現的原因;平衡二叉樹在一些極端情況下效能要比紅黑樹好。 下面介紹一下B樹以及B+樹。它們並不是二叉樹,而是多叉樹。 一、為什麼需要B樹呢? 引入這個新型別的樹你的第一反應一定是要它何用。其實在理解了B樹的性質後你就能一下子明白了。這裡還是先說明一下B樹因何而生。 其實,B樹主要用於內外存交換資料,如資料庫中的索引。因為它的特性極大地減少了磁碟I/O訪問次數,節省了這輩分的消耗,提高了效率。 二、B樹的性質 先來了解下“階”的概念,一個結點最多可以有m個孩子結點,就稱此樹是m階的。 對於一個m階B樹,性質如下: 1、如果根節點不是葉子結點,則至少應該有兩顆子樹; 2、m/2向上取整 <= 每個結點的孩子個數的取值 <= m,即要求至少半滿;關鍵字個數比孩子數少1; 3、所有的葉子結點在同一層次; 4、每個結點都包含三個屬性:n、K、A。n是這個結點包含的關鍵字個數,如下圖每個結點第一個數字都代表個數;K就是關鍵字,如圖中的 K1、K2、K3分別代表3、5、8;A是這個結點指向孩子結點的指標,如圖中的A0~A3。每個關鍵字的左邊的A指向的子結點上所有關鍵字都比它小,右邊的都比它大,如5左邊的是A1,A1指向的是4比5小,右邊的是A2,A2指向的是6、7組成的結點,都比5大。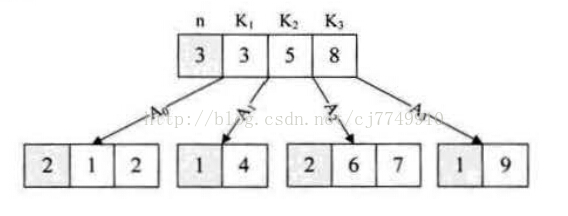 三、B樹與平衡二叉樹的關係(圖1中的關係V)
它們二者的關係並不如前所述的一系列關係密切,B樹是在平衡二叉樹的思想上的一個擴充套件,從平衡二叉樹到平衡多叉樹。
B樹與平衡二叉樹、紅黑樹有一個相似點:高度是O(lgn)。但是B樹其實是O(logmn)。這個m一般來說要比2大很多,所以B樹的高度一般不高,不高才有在內外存資料互動過程中大展拳腳的機會,你所做的查詢次數總不會超過這個高度,極大減少了內外存互動次數。
B樹的插入、刪除和查詢操作的時間複雜度也為O(lgn)。
四、B+樹
既然說到B樹,那麼勢必要說一下B+樹,因為B+樹與B樹關係太密切了,現在資料庫中多用B+樹實現索引,取代了B樹實現索引,原因看完下面的知識就一目瞭然了。
B+樹與B樹的關係
B+樹產生的原因在於:B樹的中序遍歷需要太多次I/O訪問次數了。你每次中序遍歷只能從根節點第一個關鍵字開始,遍歷了該關鍵字左孩子以 後要返回到父結點遍歷它的右孩子,如此反覆,直到結束。所以需要有一種方法解決這個問題。那麼問題來了,為什麼要這麼在意中序遍歷?就是 因為你中序遍歷以後的序列是整個樹的所有關鍵字的一個從小到大排序的序列,現在你明白為什麼B+樹更適合做索引了麼?它更適合範圍查詢。
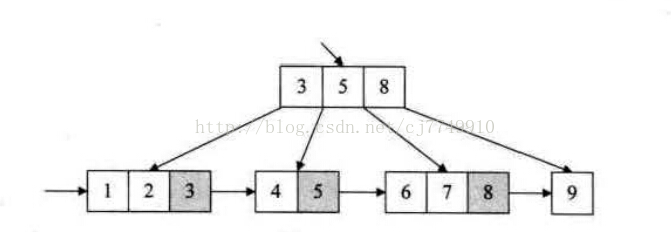
B+樹與B樹差異在於:
1、每個結點除了自身關鍵字外,還需要將父結點關鍵字儲存起來;
2、所有的葉子結點包含所有的關鍵字資訊,以及指向這些關鍵字記錄的指標,葉子結點本身按照自小而大的順序連線(每個葉子結點都有一 個指標指向下一個葉子結點);
3、所有的分支結點都可以看做是索引,它只是其孩子結點的最大或者最小的關鍵字。
看了下圖你就明白了
三、B樹與平衡二叉樹的關係(圖1中的關係V)
它們二者的關係並不如前所述的一系列關係密切,B樹是在平衡二叉樹的思想上的一個擴充套件,從平衡二叉樹到平衡多叉樹。
B樹與平衡二叉樹、紅黑樹有一個相似點:高度是O(lgn)。但是B樹其實是O(logmn)。這個m一般來說要比2大很多,所以B樹的高度一般不高,不高才有在內外存資料互動過程中大展拳腳的機會,你所做的查詢次數總不會超過這個高度,極大減少了內外存互動次數。
B樹的插入、刪除和查詢操作的時間複雜度也為O(lgn)。
四、B+樹
既然說到B樹,那麼勢必要說一下B+樹,因為B+樹與B樹關係太密切了,現在資料庫中多用B+樹實現索引,取代了B樹實現索引,原因看完下面的知識就一目瞭然了。
B+樹與B樹的關係
B+樹產生的原因在於:B樹的中序遍歷需要太多次I/O訪問次數了。你每次中序遍歷只能從根節點第一個關鍵字開始,遍歷了該關鍵字左孩子以 後要返回到父結點遍歷它的右孩子,如此反覆,直到結束。所以需要有一種方法解決這個問題。那麼問題來了,為什麼要這麼在意中序遍歷?就是 因為你中序遍歷以後的序列是整個樹的所有關鍵字的一個從小到大排序的序列,現在你明白為什麼B+樹更適合做索引了麼?它更適合範圍查詢。
B+樹與B樹差異在於:
1、每個結點除了自身關鍵字外,還需要將父結點關鍵字儲存起來;
2、所有的葉子結點包含所有的關鍵字資訊,以及指向這些關鍵字記錄的指標,葉子結點本身按照自小而大的順序連線(每個葉子結點都有一 個指標指向下一個葉子結點);
3、所有的分支結點都可以看做是索引,它只是其孩子結點的最大或者最小的關鍵字。
看了下圖你就明白了
學習B樹可以先看一下2-3樹和2-3-4樹,這裡不詳細介紹了。
以下是我覺得很不錯的幾篇部落格
http://blog.csdn.net/v_JULY_v/article/details/6530142
http://blog.csdn.net/eric491179912/article/details/6179908