
資料庫索引背後的資料結構之B-樹和B+樹
前言:索引結構有B樹索引、Hash索引、Fulltext索引等,關於樹結構的索引又分為B-Tree、B+Tree、B*Tree、R樹、R+樹等。本文重點探討B樹的前兩種結構。
資料庫查詢為什麼要使用索引
從理論上講,假設資料庫中的某一個表有
索引資料結構剖析
索引是一種加快檢索速度的資料結構。在很多資料庫管理系統中都大量使用了B+Tree,B+Tree是由B-Tree改進而來的。只有徹底地理解了這兩種資料結構,才能做好基於索引的資料庫查詢優化。下面通過計算機的儲存機制來詳細介紹這兩種資料結構。
B-Tree
B-Tree是一棵多路搜尋樹,對於每個非葉子結點都存在關鍵字和指標,關鍵字的作用是對目標資料進行比對,以縮小目標資料的搜尋範圍,指標用來指向下一層的某個結點。對於
- 樹的任意結點最多有
- 根結點的子樹個數必須滿足
- 所有葉子節點處在同一高度,所以稱之為特殊
- 處在中間層的結點(除根結點和葉子結點)的子樹個數必須滿足
- 關鍵字數=指標數+1,因為在一維空間上
- 非葉子結點的關鍵字有
- 指標
圖1為一棵三階的B-Tree示意圖。
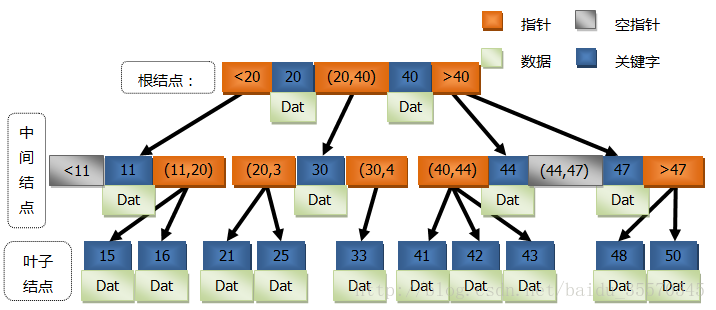
注意:在每個關鍵字上都會附有所要查詢的資料
這意味著當你正在搜尋某個資料的時候,無需每次都從根結點訪問到葉子結點,比如當需要搜尋關鍵字11所代表的資料時,只要檢索到中間結點即可。當然,這就是它相對於B+Tree的優點,在某種程度上提高了搜尋的效率。
由於B-Tree的每個結點上的關鍵字排列有序,因此搜尋資料可以借鑑於折半查詢(二分查詢)。
問:為什麼要這樣去設計B樹呢?
由於計算機的記憶體是有限的,所以我們要充分利用留在記憶體中的索引頁面。為什麼這麼說?當儲存的資料量達到巨大的時候,很難保證索引頁面都留在記憶體中,當然這也是極不可能的,總會有一部分索引頁面儲存在磁碟上,當所要查詢的資料的索引不在記憶體時才去排程磁碟上的索引頁面。CPU處理作業時只和記憶體打交道,記憶體的頁面排程時間相對於外存要小好幾個數量級,可是對於外存與記憶體之間的頁面排程(I/O操作)是相當耗時的,所以我們要儘量使I/O操作次數最少,同時又能達到搜尋資料的目的,這就是我所說的“充分利用”。
B樹相比較二叉平衡樹或者紅黑樹而言最大的優點是利用盡可能大的度數來降低樹高。B-樹上大部分基本操作所需訪問盤的次數均取決於樹高。具體計算如下:
若n≥1,m≥3,則對任意一棵具有n個關鍵字的m階B-樹,其樹高h至多為
B+Tree
B+Tree是對B-Tree的改進,並且廣泛應用於資料庫管理系統中。其與B-Tree在資料結構上有兩點區別:
- 每個非葉子結點的關鍵字數等於其孩子數,也就是說關鍵字數等於指標數;
- 所有資料都在葉子結點上.
B+Tree的指標所指的區間是左閉右開或左開右閉,圖2為一棵二階的B+Tree示意圖,圖中的指標所指向的數都比其左邊的關鍵字大。
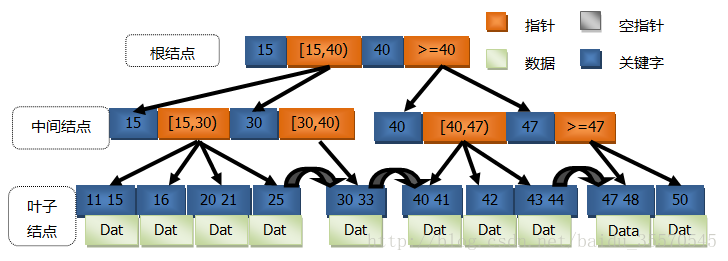
在DBMS中通常會將葉子結點通過指標相連線,為什麼要這麼做呢?這是為了方便相鄰葉子結點之間的訪問,不必每次都從根結點開始訪問。例如,有這樣一條sql語句:
select field_name from table where field_name > 24 and field_name < 31.知道根據圖2的資料,不管全表掃描也好,走索引也好,最終都會返回25和30,而B+Tree是效率最高的,它的搜尋路徑是先從根結點索引到25,緊接著根據指向下一個葉子結點的指標可以迅速找到30。針對這種連續資料塊的搜尋,這種資料結構是正是其優勢所在。
聯合索引與最左字首原則
聯合索引
上文所講的索引樹是對於同一個欄位的資料,這裡講解多個欄位的聯合索引。為了清晰的描述問題,給出表1資料:
| 職稱 | 月薪 | 姓名 |
|---|---|---|
| 講師 | 3100 | 孫權 |
| 副教授 | 8000 | 曹操 |
| 講師 | 9000 | 于吉 |
| 教授 | 5000 | 周瑜 |
| 副教授 | 4500 | 關羽 |
| 副教授 | 5600 | 張飛 |
| 教授 | 7600 | 黃蓋 |
| 講師 | 4000 | 諸葛亮 |
| 教授 | 7500 | 劉備 |
| 副教授 | 6000 | 張昭 |
| 教授 | 6500 | 大喬 |
| 講師 | 5500 | 小喬 |
| 教授 | 9000 | 馬超 |
| 講師 | 5600 | 黃忠 |
| 副教授 | 6500 | 趙雲 |
接下來我要查詢月薪為6500的副教授的名字,sql語句為:
select 姓名 from [table] where 職稱 = '副教授' and 月薪 = 6500. 最慢的方法無疑是全表掃描,其執行過程是這樣的:順序查詢職稱為副教授的資料行,找到後與月薪進行比對;第二種方法是對職稱建立索引,這樣就能快速定位到副教授,但對於月薪這一列還需一一比對;第三種方法與第二種方法類似,是對月薪建立索引,又因為月薪的選擇性高,
索引的選擇性:索引列中不同值的數目與表中記錄數的比。
所以相比較職稱而言,對月薪建立索引更加有效;第四種方法是對職稱和月薪建立聯合索引,這種方法效率最高。聯合索引是按先後順序對兩列進行排序,就是先對職稱排序,然後再對月薪排序,注意必須按先來後到的關係,月薪是在某一個職稱下進行排序後的結果。聯合索引其實就是“樹中有樹”的思想。表2為聯合索引後的結果。
| 職稱 | 月薪 | 姓名 |
|---|---|---|
| 講師 | 3100 | 孫權 |
| 講師 | 4000 | 諸葛亮 |
| 講師 | 5500 | 小喬 |
| 講師 | 5600 | 黃忠 |
| 講師 | 9000 | 于吉 |
| 副教授 | 4500 | 關羽 |
| 副教授 | 5600 | 張飛 |
| 副教授 | 6000 | 張昭 |
| 副教授 | 6500 | 趙雲 |
| 副教授 | 8000 | 曹操 |
| 教授 | 5000 | 周瑜 |
| 教授 | 6500 | 大喬 |
| 教授 | 7500 | 劉備 |
| 教授 | 7600 | 黃蓋 |
| 教授 | 9000 | 馬超 |
最左字首原則
如果對column1,column2,column3建立了聯合索引,那麼在使用該索引時只有三種組合,它們分別是:column1 、column1 and column2、column1 and column2 and column3,概括起來就是想要使用右邊的索引,必須用上左邊的所有索引。如果只使用column2作為where的查詢條件,將不會用到所建好的索引。這是為什麼呢?請看錶2。這就好比直接用月薪作為查詢條件,有沒有發現月薪是呈全域性亂序的狀態,儘管它是區域性有序的。如果業務上要求只能用月薪來查詢,可行的解決辦法是在建立聯合索引時把月薪放在最左邊,或者直接建立單列索引。
總結
上文主要介紹了兩種樹形索引結構,由於本文的側重點是查詢優化,所以並未在樹的建立與刪除上費口舌。要知道,資料結構是計算機技術能夠快速發展到今天的基礎,只有對資料結構研究透徹了,才能在索引優化上有所突破。我們發現在執行資料庫的時候,不同的sql語句的寫法可能會造成千差萬別的效率,所以做資料庫的優化的時候,我們要保持嚴謹謙遜的心態,要深刻理解研究其內部的資料結構原理,知道是什麼、為什麼、該怎麼做、不這麼做會怎麼樣。
參考文獻:
[1] MySQL索引背後的資料結構及演算法原理,2011.
[2] 索引與優化,2009.
[3] 王正萬: ‘MySQL索引分析及優化’, 黔東南民族師範高等專科學校學報, 2006, 24, (3), pp. 54-55
[4] 何愛華, 郭有強: ‘查詢優化之索引的設計’, 蚌埠學院學報, 2012, 1, (2), pp. 24-26
[5] 伍應樹, 趙志剛, 李憲明: ‘關係資料庫基於索引查詢的優化設計研究’, 電腦程式設計技巧與維護, 2016, 0, (17), pp. 56-58
[6] 魏威, 馬國峰: ‘基於索引的關係資料庫查詢優化’, 洛陽大學學報, 2007, 22, (2), pp. 83-86
非常感謝閱讀水浴月研究生生涯的第一篇博文,本人才疏學淺,希望和大家一同進步!