
使用自相似性的聚類方法——Chameleon
使用自相似性的聚類方法——Chameleon
第三十六次寫部落格,本人數學基礎不是太好,如果有幸能得到讀者指正,感激不盡,希望能借此機會向大家學習。本文作為基於圖的聚類的第四部分,主要針對“使用自相似性的Chameleon聚類演算法”即進行介紹。其他基於圖的聚類演算法的連結可以在這篇綜述《基於圖的聚類演算法綜述(基於圖的聚類演算法開篇)》的結尾找到。
傳統相似性度量方法的缺陷
層次聚類技術通過合併兩個最相似的簇來進行聚類,其中簇的相似性定義依賴於具體的演算法,例如,“單鏈”使用不同簇中點的最小距離來表示相似性,CURE則使用兩個簇中最近的代表點間距離來表示相似性。僅僅使用單一的相似度度量方法可能導致簇被錯誤的合併和分割,如下圖所示存在4個簇,如果使用“單鏈”層次聚類或CURE演算法會將簇a、b錯誤的合併在一起,而不是將簇c、d進行合併。

另一問題是,大部分聚類技術都有一個全域性(靜態)簇模型,例如,K-Means假定簇是球形的,而DBSCAN基於單個密度閾值定義簇,使用這種全域性模型的聚類方法不能處理諸如大小、形狀和密度等簇特徵在簇間變化很大的情況。以“組平均”層次聚類演算法為例,如下圖所示存在4個簇,假設每個頂點之間邊的權值相等,且每個簇的大小相等,“組平均”會將簇c、d錯誤的合併,而不是將簇a、b進行合併。

Chameleon是一種凝聚層次聚類技術,他將資料的初始劃分(使用一種有效的圖劃分演算法)和一種新穎的層次聚類方案相結合,可以有效的解決上述問題。這種層次聚類使用接近性和互連性概念以及簇的區域性建模,因此不依賴於全域性(靜態)模型,關鍵思想是,僅當合並後的結果簇類似於原來的兩個簇時,這兩個簇才應當合併。
自相似性(Self-similarity)度量
Chameleon力求合併這樣一對簇,合併後產生的簇,用接近性和互聯性度量,與原來一對簇最相似,因為這種方法僅依賴於簇對而不依賴於全域性模型,Chameleon能夠處理包含具有各種不同簇特性的簇的情況,下面分別對接近性和互聯性進行介紹。
(1) 相對接近度(Relative Closeness,簡稱RC)
相對接近度是被簇的內部接近度規範化的兩個簇的絕對接近度,更具體的說,僅當結構簇中的點之間的接近程度幾乎與原來的每個簇一樣時,才滿足兩個簇合並的條件,數學表示為:
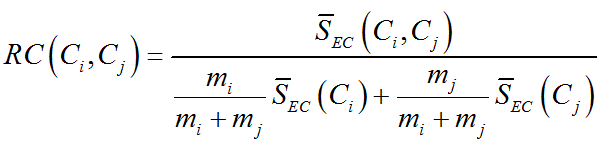
其中,
和
分別是簇
和
的大小,
絕對接近度是
-最近鄰圖中連線
和
的邊的平均加權和,內部接近度
和
分別是將簇
和
劃分為大小相等的兩個集合的割邊的平均加權和,如圖1所示,雖然簇a、b之間的絕對接近度高於簇c、d,但是他們的相對互連度要遠遠小於簇c、d。
(2) 相對互連度(Relative Inter-connectivity,簡稱RI)
相對互連度是被簇的內部互連度規範化的兩個簇的絕對互連度,僅當結果簇中的點之間的連線幾乎與原來的每個簇一樣強時,才滿足兩個簇合並的條件,數學表示為:

其中,絕對互連度
是
-最近鄰圖中連線
和
的邊的權值之和,內部互連度
和
分別是將簇
和
劃分為大小相等的兩個集合的割邊的最小加權和,如圖2所示,雖然簇c、d之間的絕對互連度高於簇a、b,但是他們的相對互連度要遠遠小於簇a、b。
RI和RC可以通過不同的方式進行組合,來產生相似性(Self-similarity)的總度量,Chameleon使用的一種方法是合併最大化
的簇對,其中
是使用者指定的引數,
時相對接近度更加重要,
時相對互連度更加重要。
Chameleon演算法
Chameleon演算法是一種基於稀疏化鄰近度圖的聚類演算法,該演算法共分為兩個階段,首先通過現有的圖劃分技術(例如METIS演算法)對稀疏鄰近度圖進行劃分,得到許多初始的子簇,然後使用動態框架對這些子簇進行凝聚層次聚類,這種演算法的缺點顯而易見,即用於進行凝聚層次聚類的子簇中的樣本點必須來自於同一個自然簇,演算法虛擬碼如下所示:

在進行稀疏鄰近度圖的劃分時,可以採用METIS演算法,該演算法將當前稀疏鄰近度圖作為一個簇,然後二分當前最大的子圖(簇),直到沒有一個簇多於 個點,其中, 是由使用者設定的引數,這個引數不僅要小於最小簇中的樣本點個數,還要足夠大以至於可以得到每個子簇的自相似性度量。需要注意的是,Chameleon並不丟棄噪聲點而是將他們指派到簇中。
參考資料
【1】《資料探勘導論》
【2】Karypis, G., E. H. Han, and V. Kumar. “Chameleon: hierarchical clustering using dynamic modeling.” Computer 32.8(2002):68-75.