
聚類方法與距離計算學習[轉載]
阿新 • • 發佈:2018-12-14
轉自:https://wenku.baidu.com/view/ab758fc558f5f61fb73666a4.html
1.聚類分析的型別

2.兩類距離
2.1歐式距離:

2.2明式距離:

3.距離缺點引出標準化及其他距離

馬氏距離://這個沒有見用過,計算比較複雜

lance和威廉距離:

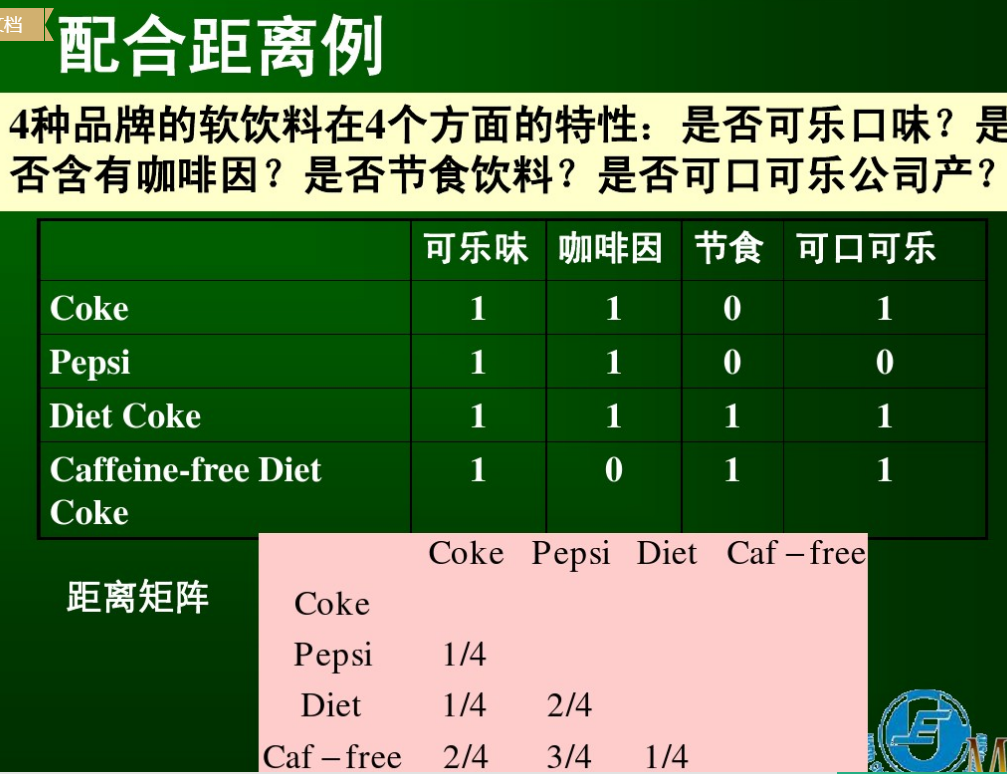
配合距離:

配合距離舉例://也就是其中類別不一樣的數目。
4.相似度


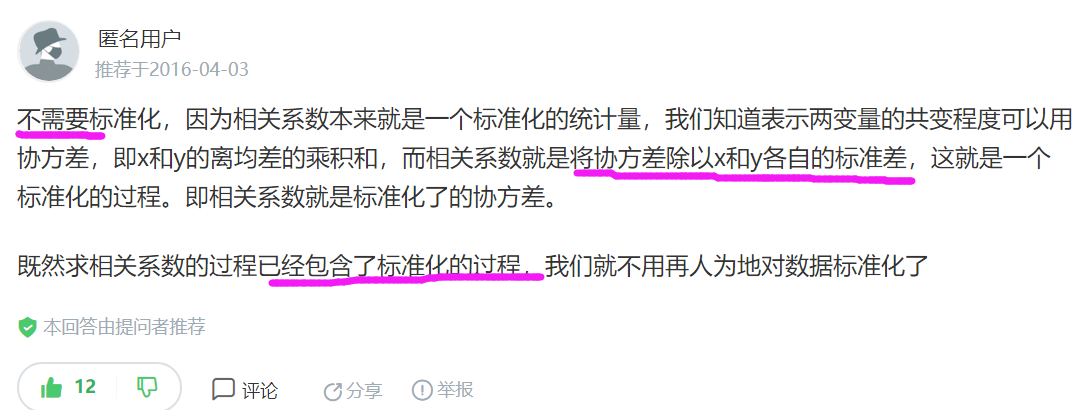
這裡上一個PPt說:變數標準化後計算的餘弦夾角與相關係數相等。我進行了計算:
> x1<-c(6,7,3,6,6) > x2<-c(7,1,2,5,6) x1s<-scale(x1,center=TRUE,scale=TRUE) x2s<-scale(x2,center=TRUE,scale=TRUE) #計算餘弦夾角,標準化資料 > sum(x1s*x2s)/sqrt(sum(x1s^2)*sum(x2s^2)) [1] 0.2165298 #計算相關係數 #使用未標準化的資料 > cor.test(x1,x2,method = "pearson") Pearson's product-moment correlation data: x1 and x2 t = 0.38415, df = 3, p-value = 0.7265 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.8229506 0.9225542 sample estimates: cor 0.2165298 #使用標準化的資料,結果是一樣的。 > cor.test(x1s,x2s,method = "pearson") Pearson's product-moment correlation data: x1s and x2s t = 0.38415, df = 3, p-value = 0.7265 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.8229506 0.9225542 sample estimates: cor 0.2165298 #但使用標準化與為標準化資料計算餘弦夾角差距非常大 > sum(x1*x2)/sqrt(sum(x1^2)*sum(x2^2)) [1] 0.8757546
查了一下,在計算皮爾遜相關係數前是否需要標準化:
5.系統聚類法


那麼這裡就涉及到如何讀譜系圖了:
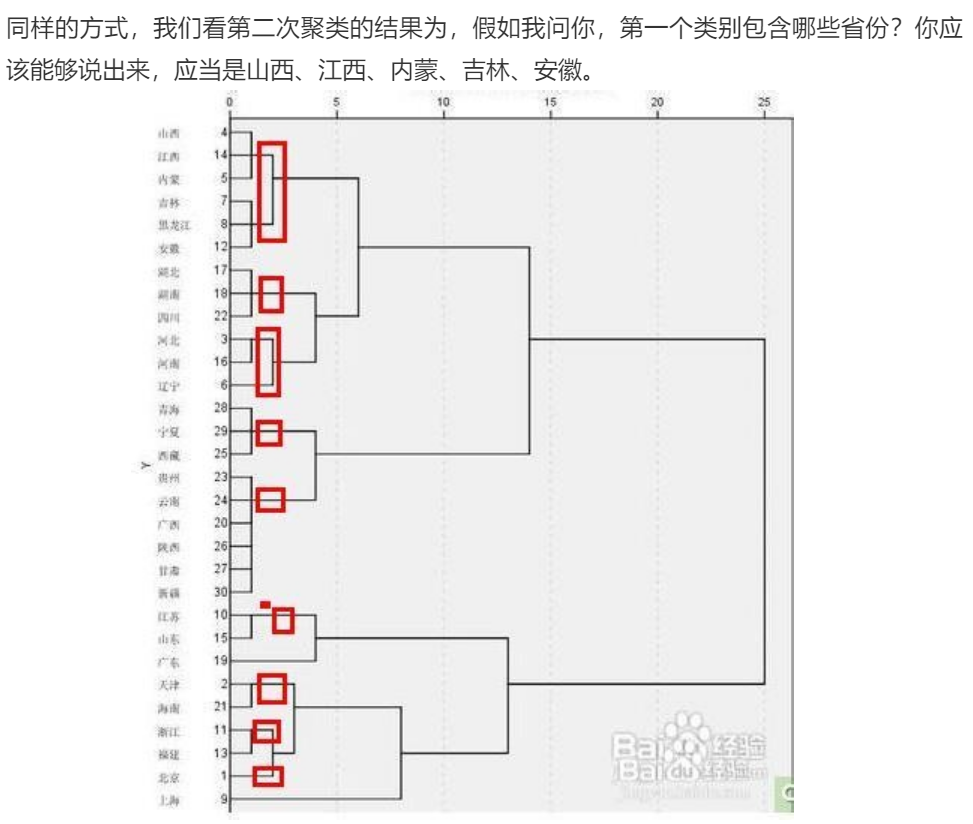
就是看它的線概括到了哪些,就是哪些特徵在一起了。
6.類與類之間的距離

6.1最短距離
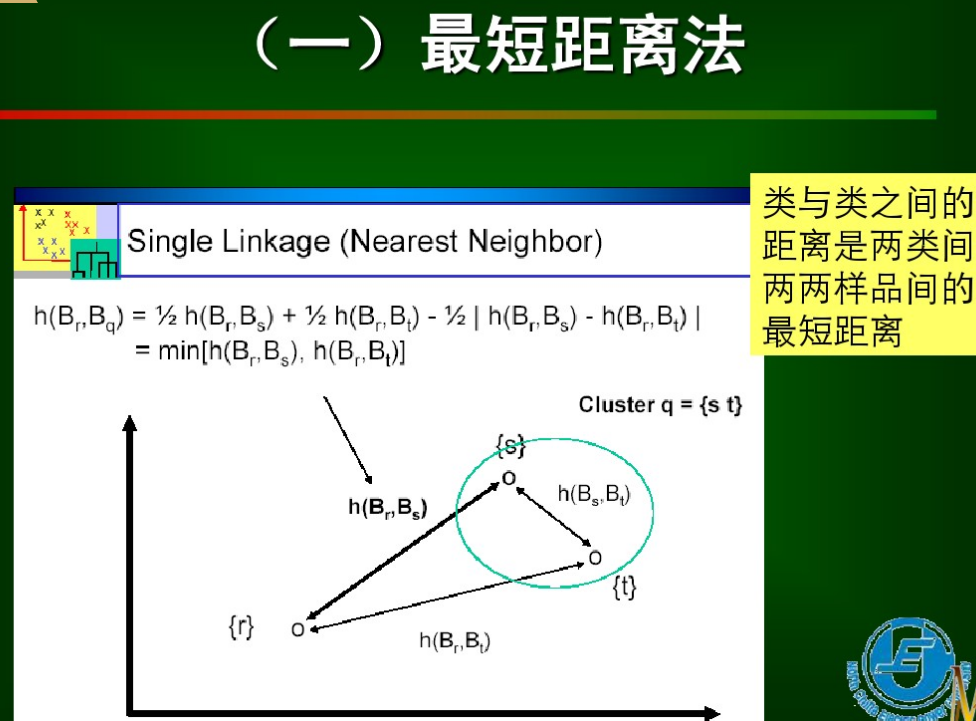
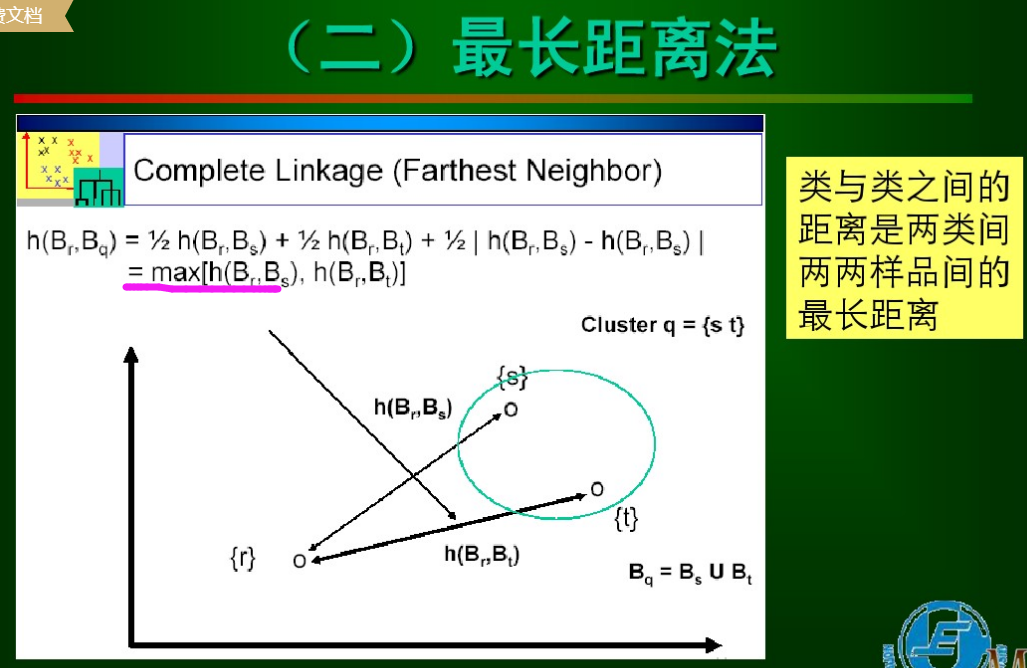
6.2最遠距離
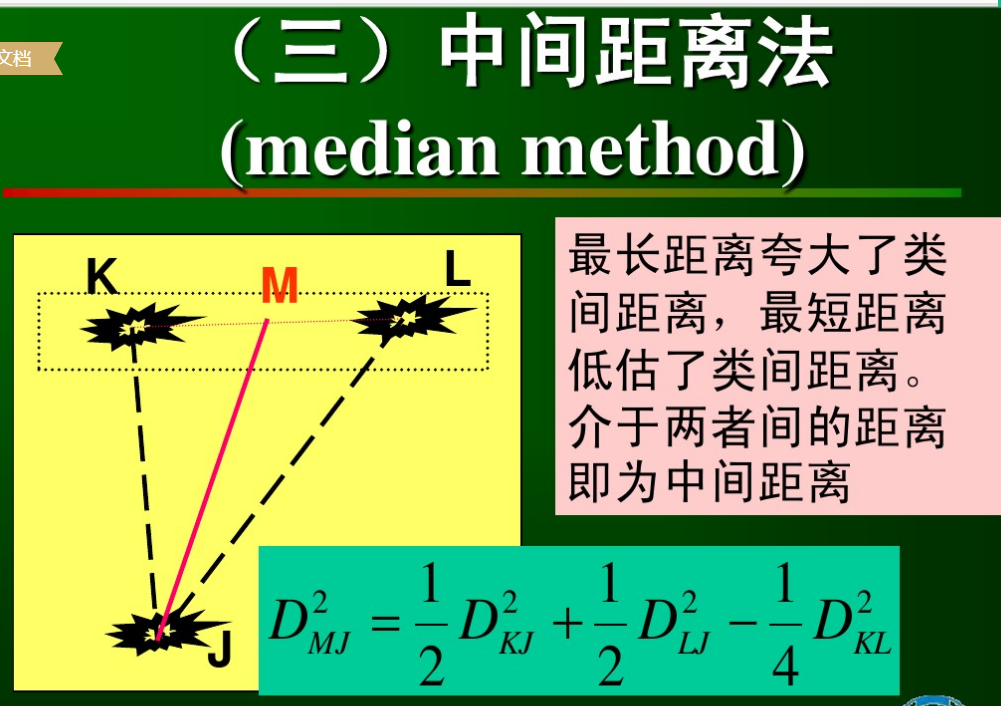
6.3中間距離
6.4類平均法average linkage between group
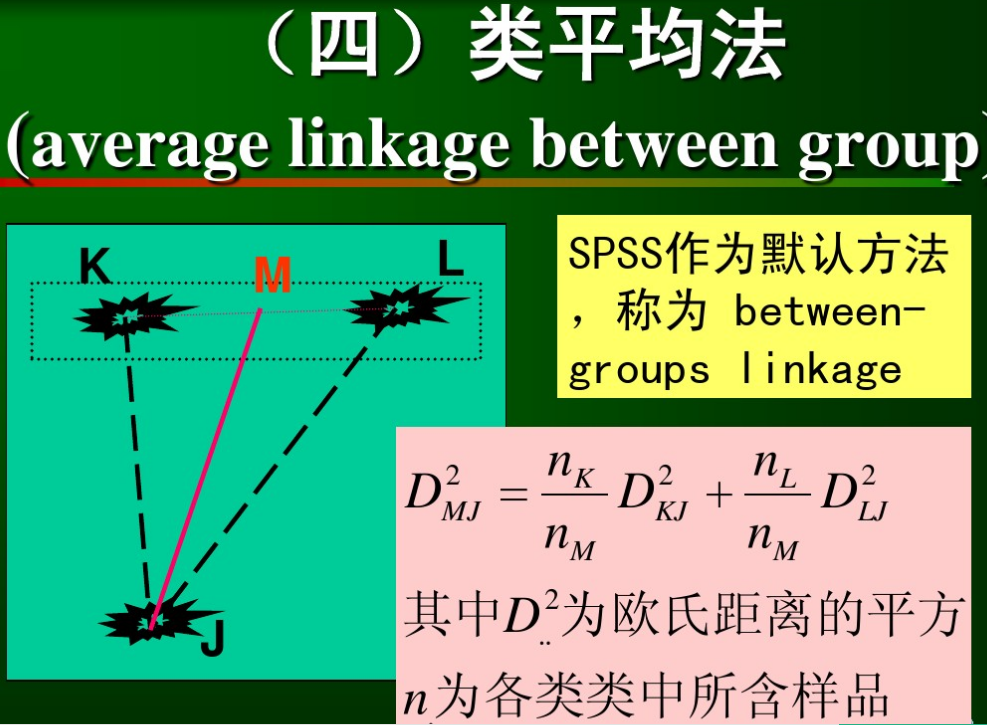
//其實這個沒有看懂,nm是什麼?M並不是一個類啊,它並沒有樣本數啊。。這個待定。
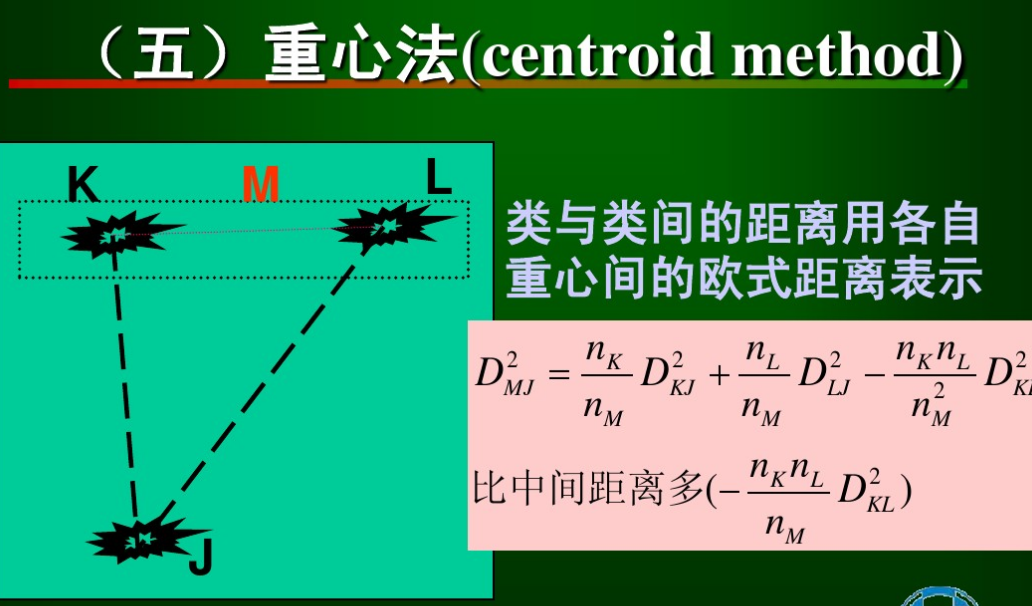
6.5重心法(重心用的是均值)
6.6Ward最小方法法距離

//這裡我感覺,複雜度好高啊!比方說目前有5類,那麼需要兩兩計算合併後的離差平方和。共需要計算10次。複雜度其實是n^2。
7.標準化方法

8.快速聚類(k-means聚類)

8.1初始聚類k個點的選擇

這頁非常好了,選取少量樣本系統聚類!。
8.2對於spss中k-means的結果:
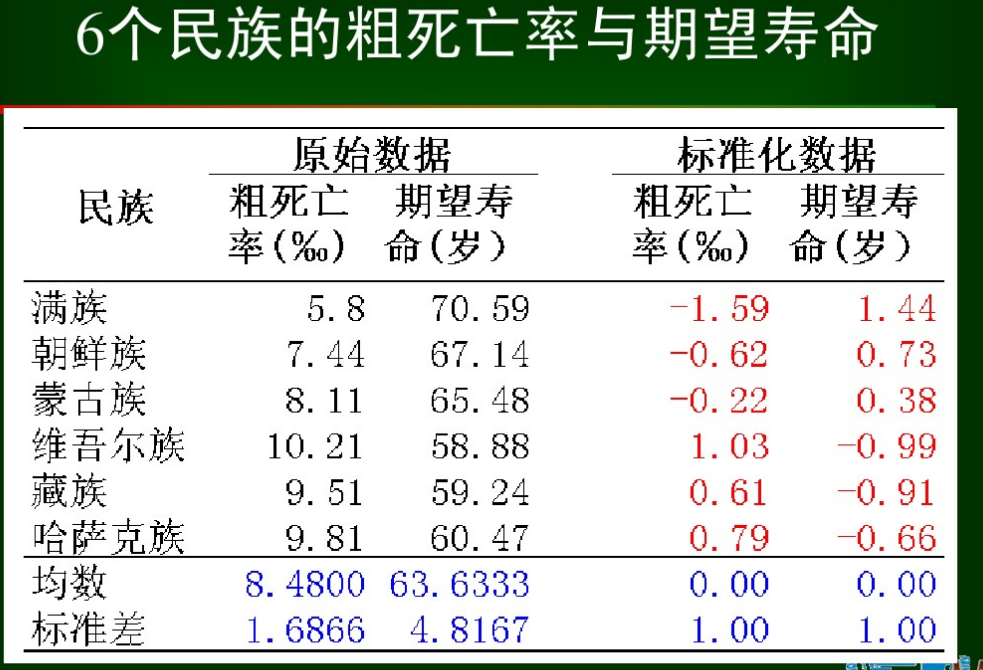
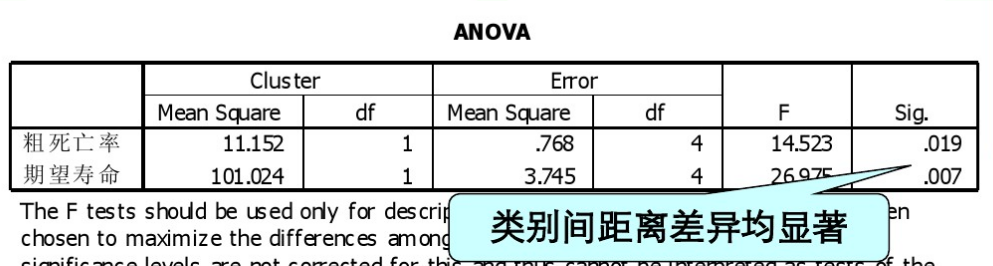
注意到了有一個sig顯著性引數,顯著性<0.05,差異顯著。
9.變數聚類

減少多重共線性,得到的特徵並不一定都可以表示,可以減少類似的特徵。
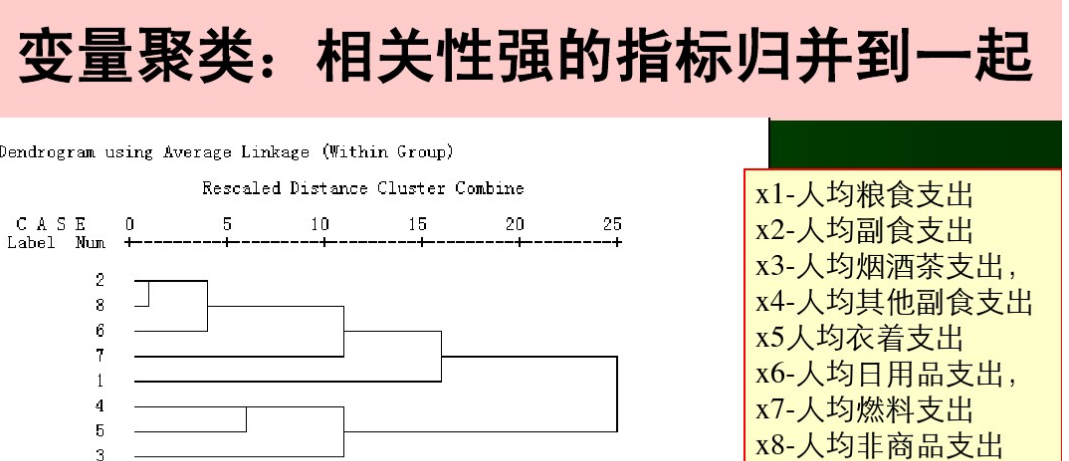
比如上圖:如果分稱5類的話,那麼分別是286、7、1、45、3。
並且通過觀察,每條直線終點指向的數就是聚類中心點。