
Apache Flink流處理(二)
到目前為止,您已經瞭解了流處理如何解決傳統批處理的侷限性,以及它如何支援新的應用程式和體系結構。您已經熟悉了開源的流處理空間的演變,並對Flink流應用程式有了簡單的瞭解。在這一章,你將進入流世界中,並得到本書本書剩下部分所必要的基礎知識。
這一章仍然與Flink無關。它的目標是介紹流處理的基本概念並討論流處理框架的需求。我們希望在閱讀本章之後,您能夠更好地理解流應用程式需求,並能夠評估現代流處理系統的特性。
2.1資料流程式設計介紹【dataflow programming】
在深入研究流處理的基礎知識之前,我們必須首先介紹資料流程式設計【dataflow programming】的必要背景知識,並確定我們將在本書中使用的術語。
2.1.1資料流圖[Dataflow graphs]
顧名思義,資料流程式描述了資料如何在業務操作【operations】之間流動。資料流程式通常表示為有向圖,其中節點稱為運運算元/操作符【operator】,表示計算,而邊表示資料依賴。運運算元/操作符【operator】是資料流應用程式的基本功能單元。它們消耗輸入的資料,對其執行計算,並將資料生成輸出以進行進一步的處理。沒有輸入埠的運運算元/操作符【operator】稱為資料來源[data source],沒有輸出埠的運運算元/操作符【operator】稱為資料接收器[data sinks]。資料流圖必須至少包含有一個數據源和一個數據接收器。圖2.1顯示了一個dataflow程式,它從tweet的輸入流中提取和計數雜湊標籤:

圖2 - 1 一個邏輯資料流圖,用於連續計數雜湊標籤。節點表示運運算元/操作符【operator】,邊表示資料依賴關係
圖2.1中的資料流圖之所以稱為邏輯圖,是因為它傳達的是計算邏輯的高階檢視。為了執行一個數據流程式,需要將其邏輯資料流圖轉換為物理資料流圖,其中包括關於如何執行計算的詳細資訊。例如,如果我們使用分散式處理引擎,每個運運算元/操作符【operator】可能在不同的物理機器上執行多個並行任務。圖2.2顯示了圖2.1中的邏輯資料流圖的物理資料流圖。在邏輯資料流圖中,節點表示運運算元/操作符【operator】,而在物理資料流中,節點表示任務【tasks】。“Extract hashtags”和“Count”運運算元/操作符【operator】分別有兩個並行的運運算元/操作符任務【operator task】,每個運運算元/操作符任務【operator task】均是對輸入資料的子集執行計算。
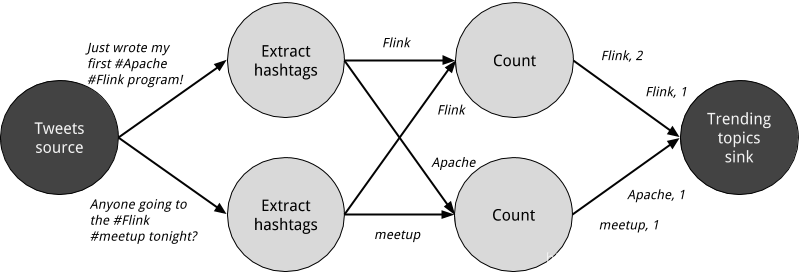
圖2 - 2 統計標籤的物理資料流計劃,其中節點代表的任務。
2.1.2 資料並行與任務並行
可以以不同的方式利用資料流圖中的並行性。首先,您可以對輸入資料進行分割槽,並讓相同操作的任務並行地在資料子集上執行。這種型別的並行性稱為資料並行性。資料並行性非常有用,因為它允許處理大量資料並將計算負載分散到多個計算節點。其次,可以讓來自不同運運算元/操作符【operator】的任務並行地對相同或不同的資料執行計算。這種並行性稱為任務並行性。使用任務並行性可以更好地利用叢集的計算資源。
2.1.3 資料交換策略
資料交換策略定義瞭如何將資料項/資料條目分配給物理資料流圖中的任務。資料交換策略可以由執行引擎根據運運算元/操作符【operator】的語義自動選擇,也可以由資料流程式設計師顯式地強制實施。在這裡,我們簡要回顧一些常見的資料交換策略,如圖2.3所示:
- 轉發【forward】策略將資料從一個任務傳送到另一個接收任務。如果兩個任務位於同一臺物理機器上(通常由任務排程器保證),那麼這種交換策略可以避免網路通訊。
- 廣播【broadcast】策略將每個資料項傳送給一個運運算元/操作符【operator】的所有並行的任務上。因為這種策略涉及資料複製和網路通訊,所以成本相當高。
- 基於鍵【key-based】的策略通過鍵屬性【key】對資料進行分割槽,並確保具有相同key的資料項將由相同的任務處理。在圖2.2中,“Extract hashtags”運運算元/操作符【operator】的輸出基於key(hashtag)進行分割槽,這樣count運運運算元/操作符任務【operator task】就能夠正確計算每個hashtag的出現次數。
- 隨機【random】策略將資料項均勻地分配給運運算元/操作符任務【operator task】,以便在任務之間均勻地分配負載。
THE FORWARD AND RANDOM STRATEGIES AS KEY-BASED
轉發策略和隨機策略也可以看作是基於鍵的策略的變體,前者保持上游元組的鍵,而後者則執行鍵的隨機重新分配。
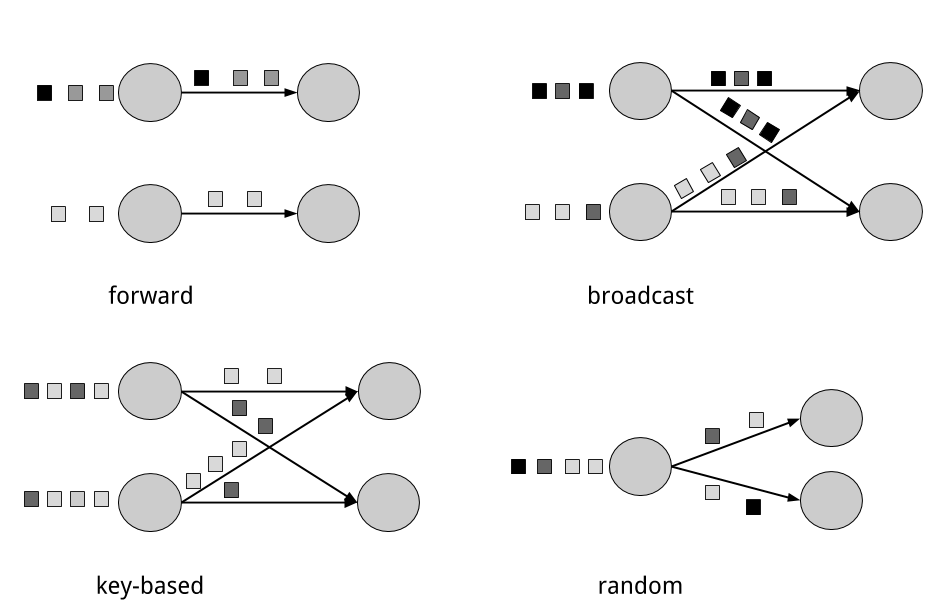
圖2-3 資料交換策略
2.2 並行處理無限的流
現在您已經熟悉了資料流程式設計【dataflow programming】的基礎知識,接下來我們將看看這些概念如何應用於並行處理資料流。但首先,我們定義術語資料流【data stream】:
A data stream is a potentially unbounded sequence of events
資料流是可能無限界的事件序列
資料流中的事件可以表示監視資料、感測器測量、信用卡交易、氣象站觀測、線上使用者互動、web搜尋等。在本節中,您將學習使用資料流程式設計正規化【dataflow programming paradigm】並行處理無限流的概念。
2.2.1延遲和吞吐量
在上一章中,您看到了流式應用程式是與傳統批處理程式有著不同的操作需求。在評估效能時,需求也有所不同。對於批處理應用程式,我們通常關心的是作業的總執行時間,簡而言之:處理引擎讀取輸入、執行計算和回寫結果需要多長時間。由於流式應用程式是連續執行的,並且輸入可能是無限的,所以在資料流處理中不存在總執行時間的概念。相反,流式應用程式必須儘可能快地為傳入的資料提供結果,同時能夠處理較高的事件攝取率。我們用延遲和吞吐量這兩個指標表示效能。
LATENCY延遲
延遲表示處理事件需要多長時間。本質上,它是指從接收事件到在輸出中看到處理此事件的效果之間的時間間隔。要直觀地理解延遲,可以考慮您每天訪問您最喜歡的咖啡店的情景。當你走進咖啡店時,裡面可能已經有其他顧客了。因此,你排隊等候,當輪到你時,你就下訂單。收銀員收到您的付款,並把您的訂單交給為您準備飲料的咖啡師。一旦你的咖啡準備好了,咖啡師就會叫你的名字,你就可以從前臺拿咖啡了。您的服務延遲指是您在咖啡店中,從您進入咖啡店的那一刻起,直到您喝了第一口咖啡所花費的時間。
在資料流中,延遲是以時間為單位度量的,比如毫秒。根據應用程式的不同,您可能會關心平均延遲、最大延遲或百分比延遲。例如,平均延遲值為10ms意味著事件平均在10ms時間內被處理。相反,95%的延遲值為10ms意味著95%的事件在10ms時間內處理。平均值隱藏了延遲的真實分佈,並且可能使問題難以檢測。如果咖啡師在準備卡布奇諾咖啡之前就把牛奶喝光了,你就得等他們從供應室拿來一些。雖然你可能會對這種延遲感到惱火,但大多數其他客戶仍然會對這裡的服務感到很滿意。
對於絕大多數流式應用程式來說,確保低延遲是非常關鍵的,例如欺詐檢測、報警、網路監視和使用嚴格的服務級別協議(sla)提供服務。低延遲是流處理的一個關鍵特性,它使得我們所說的實時應用程式變得可能。像Apache Flink這樣的現代流處理器可以提供低至幾毫秒的延遲。相比之下,傳統的批處理延遲通常在幾分鐘到幾個小時之間。在批處理中,首先需要分批次的收集事件,然後才能處理它們。因此,延遲受到每個批處理中最後一個事件的到達時間的限制,而這自然取決於批處理的大小。真正的流處理不會引入這種人為的延遲,因此可以實現非常低的延遲。在真正的流模型中,事件一旦到達系統就可以被處理,延遲自然更接近於對每個事件執行所花費的實際工作時間。
吞吐量
吞吐量是系統處理能力的度量,即處理速度。也就是說,吞吐量告訴我們每個時間單元內,系統可以處理多少個事件。再看一下咖啡店的例子,如果這家咖啡店從早上7點開到晚上7點,一天接待600名顧客,那麼它的平均吞吐量將是每小時50名顧客。雖然希望延遲儘可能低,但通常希望吞吐量儘可能高。
吞吐量通常以單位時間內所處理的業務操作或事件來度量。需要注意的是,處理的速度取決於到達的速度;低吞吐量並不一定意味著效能不好(即事件在傳遞的過程消費了太多的時間,比如網路訊號不好,或者記憶體不足)。在流系統中,您通常希望確保您的系統能夠處理最大的事件預期速率。也就是說,您主要關心的是確定峰值吞吐量,即系統在其最大負載時的效能限制。為了更好地理解峰值吞吐量的概念,讓我們考慮系統資源完全未利用的情況。當第一個事件出現時,它將立即以儘可能低的延遲進行處理。如果你是早上第一個在咖啡店開門後出現的顧客,你就會立即得到服務。理想情況下,您希望這種延遲保持在一個常量值水平,並且與傳入事件的速率無關。一旦我們達到了系統資源被充分利用起來時候的事件接收速率,我們將不得不開始緩衝事件。在咖啡店的例子中,你可能會在午後時分看到這種情況發生。許多人同時出現,你不得不排隊等候下訂單。此時系統已經達到了峰值吞吐量,進一步增加事件傳入速度只會導致更糟糕的延遲。如果系統繼續以超出其處理能力的速度接收資料,緩衝區可能會變得不可用,甚至丟失資料。這種情況通常被稱為背壓,有不同的應對策略。在第三章中,我們詳細介紹了Flink的背壓機制。
延遲VS吞吐量
此時,你應該很清楚,延遲和吞吐量並不是相互獨立的度量標準。如果事件在資料處理管道中傳輸需要很長時間,我們就不能輕鬆地保證高吞吐量。類似地,如果系統的吞吐量很小,事件將被緩衝,並且必須在被處理之前等待很長時間。
讓我們再次引用咖啡店這個示例,以闡明延遲和吞吐量如何相互影響。首先,應該清楚的是,在空載情況下存在最佳延遲。也就是說,如果你是咖啡店裡唯一的顧客,你會得到最快的服務。然而,在繁忙的時候,客戶不得不排隊等待,延遲會增加。影響延遲和吞吐量的另一個因素是處理事件所花費的時間,或者可以說是在咖啡店為每個顧客提供服務所花費的時間。想象一下,在聖誕節期間,咖啡師們必須在他們提供的每一杯咖啡上畫一個聖誕老人。這樣一來,準備一杯飲料的時間會增加,導致每個人在咖啡店的時間增加,從而降低整體的吞吐量。
那麼,您是否能夠同時獲得低延遲和高吞吐量,或者這只是一種無望的嘗試呢?獲得低延遲的一種方法是僱傭一名更有技巧的咖啡師,即一名準備咖啡更快的咖啡師。在高負載下,這種改變還會增加吞吐量,因為在相同的時間內會有更多的客戶得到服務。另一種達到相同效果的方法是僱傭第二個咖啡師,即利用並行性。這裡的主要要點是,降低延遲實際上會增加吞吐量。當然,如果一個系統可以更快地執行業務操作【operations】(即低延遲),那麼它可以在相同的時間內執行更多的業務操作【operations】(即高吞吐量)。事實上,這是通過在流處理管道中利用並行性實現的。通過並行處理多個流,可以在同時處理更多事件的同時降低延遲。
2.2.2 資料流上的操作
流處理引擎通常提供一組用於攝取、轉換和輸出流的內建操作【operations 】。這些運運算元/操作符【operator】可以組合成資料流處理圖來實現流應用程式的邏輯。在本節中,我們將描述最常見的流運運算元/操作符【operator】。
操作【operation】可以是無狀態的,也可以是有狀態的。無狀態的操作【Stateless operation】不維護任何內部狀態。也就是說,事件的處理不依賴於過去發生的任何事件,也不保留任何歷史。無狀態的操作【Stateless operation】很容易並行化,因為這些事件可以彼此獨立地處理,且不會受到事件到達的順序影響。此外,在發生故障的情況下,可以簡單地重新啟動無狀態運運算元/操作符【operator】,並從它停止的地方繼續處理。相反,有狀態運運算元/操作符【Stateful operator】可能會維護關於它們以前接收到的事件的資訊。該狀態可由傳入事件更新,並可用於未來事件的處理邏輯。有狀態的流處理應用程式在並行化和以容錯方式操作方面面臨更大的挑戰,因為在出現故障的情況下,狀態需要有效地分割槽和可靠地恢復。在本章的最後,您將瞭解關於有狀態的流處理、故障場景和一致性的更多資訊。
資料攝取和資料輸出
資料攝取和資料匯出操作【operation】允許流處理器與外部系統通訊。資料獲取是指從外部資料來源獲取原始資料並將其轉換為適合處理的格式的操作【operation】。實現資料攝入邏輯的運運算元/操作符【operator】稱為資料來源【data source】。資料來源可以從TCP套接字、檔案、Kafka主題或感測器資料介面來攝取資料。資料匯出是以適合於外部系統消費的形式產生輸出的操作。執行資料匯出的運運算元/操作符【operator】稱為資料接收器【data sinks 】,示例包括檔案、資料庫、訊息佇列和監視介面。
轉換操作
轉換操作是獨立處理每個事件的單通道操作。這些操作會一個又一個的消費事件,並對事件資料應用一些轉換,生成一個新的輸出流。轉換邏輯可以整合在運運算元/操作符【operator】中,也可以由使用者自定義函式(UDF)提供,如圖2.4所示。UDF由應用程式程式設計師編寫,實現自定義的計算邏輯。
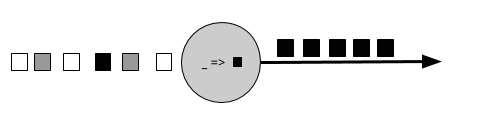
圖2 - 4 帶有UDF的流運運算元【operator】,它將每個傳入事件轉換為黑色事件。
運運算元/操作符【operator】可以接受多個輸入併產生多個輸出流。它們還可以通過將流拆分為多個流或將流合併為單個流來修改資料流圖的結構。我們將在第五章討論Flink中所有可用的運運算元/操作符【operator】的語義。
滾動聚合【ROLLING AGGREGATIONS】
滾動聚合【ROLLING AGGREGATIONS】是為每個輸入事件不斷更新的聚合,例如sum、minimum和maximum。聚合操作是有狀態的,並將當前狀態與傳入的事件結合起來以生成更新的聚合值。注意,為了能夠有效地將當前狀態與事件結合起來併產生單個值,聚合函式必須滿足結合律【associative】和交換律【commutative】。否則,運運算元/操作符【operator】將不得不儲存完整的流歷史記錄。圖2.5顯示了滾動最小值聚合。運運算元【operator】保持當前的最小值,並根據傳入的事件相應的更新該聚合值。
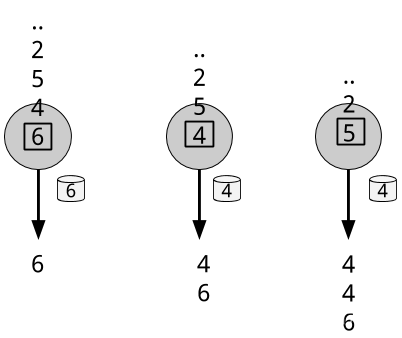
圖2 - 5 滾動最小值聚合運算【operation】
視窗【WINDOWS】
轉換和滾動聚合一次只處理一個事件,以產生輸出事件和潛在的狀態更新。然而,一些操作必須收集和緩衝記錄,以用來計算它們的結果。例如,考慮流式join操作或整體聚合(如中位數)。為了在無界流上高效地計算這些操作,您需要限制這些操作所維護的資料量。在本節中,我們將討論視窗【windows】操作,它提供這種機制。
除了具有實用價值之外,視窗【windows】還支援對流進行特定語義的查詢。您已經看到滾動聚合如何以一個聚合值的形式編碼整個流的歷史記錄,併為每一個事件提供一個低延遲的結果。這對於某些應用程式來說很好,但是如果您只對最新的資料感興趣呢?考慮一個向司機提供實時交通訊息的應用程式,以便於司機可以避開擁擠的路線。在這個場景中,您希望知道在過去幾分鐘內某個位置是否發生了事故。另一方面,在這種情況下,瞭解所有發生過的事故可能就沒有那麼必要了。更重要的是,通過將流中的歷史記錄歸約(reduce)為單個聚合值,您將丟失關於資料隨時間變化的資訊。例如,你可能想知道每5分鐘有多少輛車穿過一個十字路口。
視窗【windows】操作會不斷地從無限事件流中建立有限事件集,我們稱之為bucket,並讓我們對這些有限集執行計算。事件通常根據資料屬性或時間被分配給bucket。為了正確定義視窗運運算元/操作符【window operator】的語義,我們需要首先回答兩個主要問題:“如何將事件分配給bucket ?”和“視窗多長時間產生一次結果?”。windows的行為由一組策略定義。視窗策略決定何時建立新的bucket、將哪些事件分配給哪些bucket以及何時計算bucket中的內容。基於一個觸發條件,決定何時計算bucket中的內容。當觸發條件滿足時,bucket中的內容被髮送到一個計算函式,該函式對bucket中的元素應用計算邏輯。計算函式可以是像sum或minimum這樣的聚合,也可以是自定義的運算。策略可以基於時間(例如最近5秒內收到的事件)、計數(例如最近100個事件)或資料屬性。在本節中,我們將描述常見的視窗型別的語義。
- 滾動視窗【Tumbling window】將事件分配到固定大小的非重疊的bucket中。在事件抵達視窗邊界,所有事件都被髮送到一個計算函式中進行處理。基於計數的滾動視窗定義了在觸發計算之前需要收集多少事件。圖2.6顯示了一個基於計數的滾動視窗,它將輸入流離散為包含4個元素的bucket。基於時間的滾動視窗定義了在桶中緩衝事件的時間間隔。圖2.7顯示了一個基於時間的滾動視窗,該視窗將事件聚合到bucket中,並每10分鐘觸發一次計算。
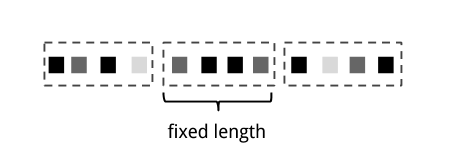
圖2-6 基於計數的滾動視窗

圖2-7 基於事件的滾動視窗
-
滑動視窗【Sliding window】將事件分配到固定大小的重疊的bucket中。因此,一個事件可能屬於多個bucket。我們通過提供長度(length)和滑動(slide)這兩個配置的值,來定義滑動視窗。滑動(slide)值定義了建立新桶的間隔。圖2.8中所示的是基於計數的滑動視窗,它的length=4個事件,slide=3個事件。
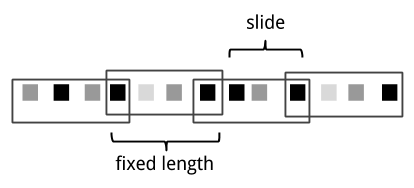
圖2-8 基於計數的滑動視窗 -
會話視窗【Session window】在既不能應用滾動視窗也不能應用滑動視窗的常見現實場景中非常有用。考慮一個分析線上使用者行為的應用程式。在此類應用程式中,我們希望將來自同一使用者活動或會話期間的事件組合在一起。會話是由兩部分組成,一部分是在相鄰時間內發生的一系列事件,另一部分則是一段失活時間(在這段時間內,沒有任何事件攝入,我們就假定應該是會話結束了)。例如,使用者一個又一個的與一系列新聞文章互動,這就可以看做是一個會話。由於會話的長度是無法預先定義的,而是取決於實際資料,因此在此場景中不能應用滾動視窗和滑動視窗。相反,我們需要一個視窗,來將同一會話中的事件,分配到同一個bucket中。會話視窗根據會話間隙值【 session gap value】對會話中的事件分組,會話間隙值定義了一個會話失活的參考時間值,當超過該時間值後仍沒有新的事件進入視窗,那麼表示會話關閉了。圖2-9展示了一個會話視窗。
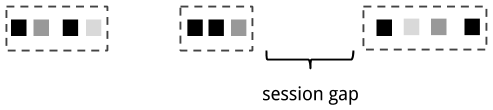
圖2-9 會話視窗
到目前為止,您看到的所有視窗型別都是全域性視窗,並且它們都是在整個流上進行操作。但在實踐中,您可能希望將流劃分為多個邏輯流並定義並行的視窗。例如,如果您正在接收來自不同感測器的測量資料,您可能希望在應用視窗計算之前,根據感測器id對流進行分組。在並行視窗中,每個分割槽獨立於其他分割槽應用視窗策略。圖2.10顯示了通過事件的顏色屬性分割槽,並並行執行的基於計數的滾動視窗(length=2)。
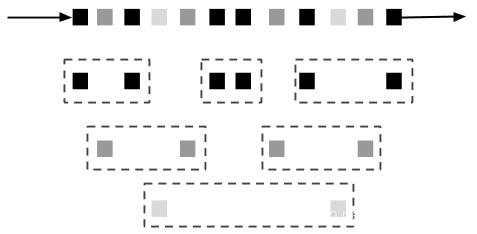
圖2-10 並行的基於計數的滾動視窗(length=2)
視窗操作與流處理中的兩個主要概念密切相關:時間語義和狀態管理。時間可能是流處理中最重要的方面。儘管低延遲是流式處理的一個引人注目的特性,但它的真正價值遠不僅僅是提供快速分析。現實世界中的系統、網路和通訊渠道遠非完美,因此流資料常常會延遲或無序到達。理解如何在這樣的條件下交付準確和確定的結果是至關重要的。更重要的是,在生成事件時處理事件的流應用程式也應該能夠以相同的方式處理歷史事件,從而支援離線分析【offline analytics】甚至時間漫遊分析【time travel analyses】。當然,如果您的系統不能保護狀態不受故障影響,那麼這些都不重要。到目前為止,您看到的所有視窗型別都需要在執行操作之前緩衝資料。事實上,如果您想在流應用程式中計算任何有趣的東西,即使是一個簡單的計數,您也需要維護狀態。考慮到流應用程式可能會執行幾天、幾個月甚至幾年,您需要確保在出現故障時能夠可靠地恢復狀態,這樣的話,你的系統就可以保證即使出現故障問題也能得到準確的結果。在本章的其餘部分中,我們將深入研究資料流處理在失敗情況下的時間和狀態保證的概念。
2.4 時間語義
在本節中,我們將介紹時間語義,並描述流中時間的不同概念。我們將討論流處理器如何為無序事件提供精確的結果,以及如何使用流執行歷史事件處理和時間漫遊【 time travel】。
2.4.1 一分鐘是什麼意思?
在處理持續不斷到達的無限事件流時,時間成為應用程式的重要方面。假設您希望持續不斷地計算結果,例如每分鐘計算一次。在我們的流式應用上下文中,一分鐘到底意味著什麼?
讓我們來考慮這樣一個程式,它分析使用者玩線上手機遊戲所產生的事件。使用者被組織在一個team中,應用程式收集一個team的活動,並根據team成員達到遊戲目標的速度提供獎勵,比如額外的生命和經驗。例如,如果team中的所有使用者在一分鐘內彈出500個氣泡,他們就會升級。Alice是一個忠實的遊戲玩家,她每天早上上班的路上都會玩這個遊戲。但問題是Alice住在柏林,她每天乘地鐵上下班。每個人都知道柏林地鐵裡的移動網際網路連線非常糟糕。考慮這樣一種情況,當Alice的手機連線到網路時,她開始彈出氣泡,並向分析系統傳送事件訊息。突然,火車進入隧道,她的網路被斷開了。Alice仍然繼續在玩,遊戲事件在她的手機裡緩衝。當火車離開隧道時,她會恢復線上狀態,緩衝區中等待處理的事件會被髮送到析系統。析系統應該怎麼做呢?在這種情況下,一分鐘是什麼意思?它是否包括Alice離線的時間?
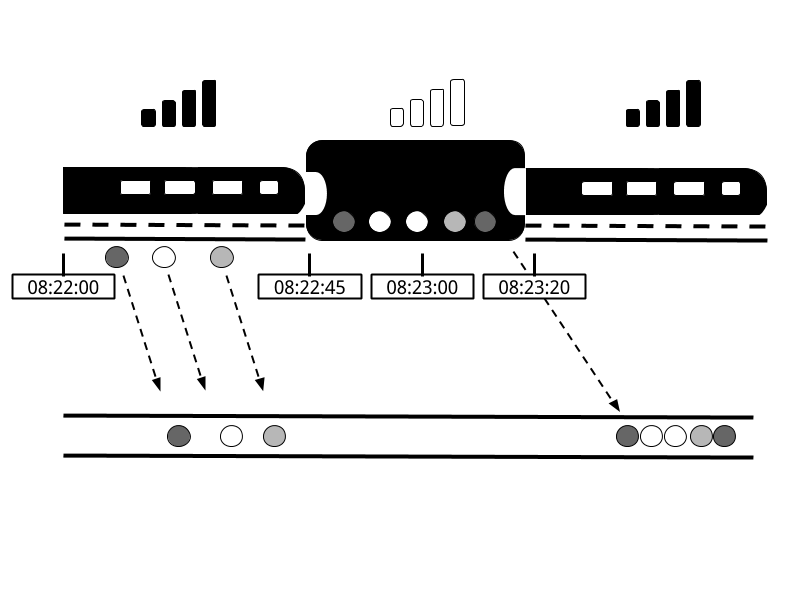
圖2-11 在地鐵裡玩手機遊戲。當火車進入隧道斷開網路時,接收遊戲事件的應用程式將會經歷一段缺口。事件將在玩家的手機中緩衝,並在網路連線恢復時傳送到應用程式。
線上遊戲是一個簡單的場景,展示了操作符語義依賴於時間例項發生的時間,而不是應用程式接收到事件的時間。對於一款手機遊戲來說,後果可能就像Alice和她的team會對遊戲感到失望,再也不會玩了一樣糟糕。但是還有很多對時序要求嚴格的應用程式,我們需要保證它們的語義。如果我們只考慮在一分鐘內接收了多少資料,那麼結果就會有所不同,這取決於網路連線的速度或處理的速度。相反,真正用來定義一分鐘內事件數量的標準應該是資料本身的時間。
在Alice玩手遊的這個示例中,流應用程式可以使用兩種不同的時間概念-------處理時間【Processing Time】或事件時間【Event Time】。我們在下面的章節中會描述這兩個概念。
2.4.2 處理時間【Processing Time】
處理時間【Processing Time】是正在執行處理流的運運算元/操作符【operator】所在的機器的本地時鐘的時間。處理時間視窗【 processing-time window】包括了在一段時間週期內碰巧到達視窗操作符【window operator 】的所有事件,這些事件由其機器的掛鐘來度量的。如圖2-12所示,在Alice的例子中,當她的手機斷開網路時,一個處理時間視窗【 processing-time window】將繼續計算時間,因此不會計入她在這段時間內的遊戲活動。

圖2 - 12 當Alice的手機斷開連線時,一個處理時間視窗【 processing-time window】將繼續計算時間。
2.4.3 事件時間【Event Time】
事件時間指的是流中事件實際發生的時間。事件時間基於附加在流事件上的時間戳。在進入處理管道之前,時間戳通常已經存在於事件資料中(例如,事件建立時間)。圖2-13顯示的事件時間視窗【Event Time Window】將正確地將事件放置在視窗中,這真實的反映了事情是如何發生的,即使有些事件被延遲了。
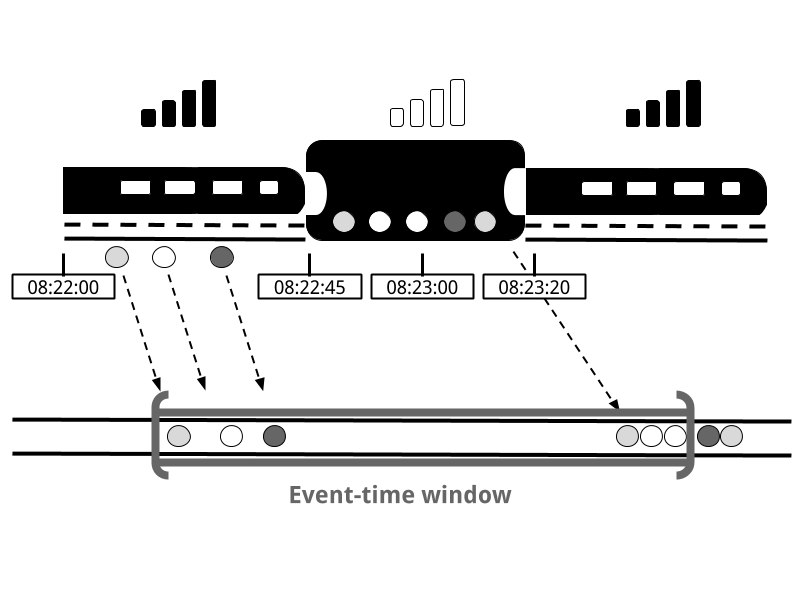
圖2 - 13 事件時間Event Time】正確地將事件放置在視窗中,反映了事情是如何發生的。
事件事件【Event Time】完全將處理速度與結果解耦。基於事件時間的操作是可預測的,它們的結果是確定的。無論流處理的速度有多快,或者事件何時到達運運算元/操作符【operator】,事件時間視窗【Event Time Window】的計算都會產生相同的結果。
處理延遲事件僅僅是事件時間【Event Time】所能克服的挑戰之一。除了經歷網路延遲之外,流還可能受到許多其他因素的影響,導致事件亂序到達。想想Bob,他是另一個線上移動遊戲的玩家,碰巧坐在和愛麗絲一樣的火車上。Bob和Alice玩同一款遊戲,但他們使用不同的移動供應商。當Alice的手機在隧道內斷開網路連線時,Bob的手機始終保持連線線上,並將事件傳遞給遊戲應用程式。
通過依賴事件時間【Event Time】,即使在這種情況下,我們也可以保證結果的正確性。更重要的是,當事件時間【Event Time】與可重放【replayable】的流相結合時,時間戳決定論使您能夠快進過去。也就是說,您可以重放流並分析歷史資料,就好像事件正在實時發生一樣。此外,您可以將計算快進到現在,這樣,一旦您的程式趕上了正在實時發生的事件,它就可以繼續使用完全相同的程式邏輯作為實時應用程式來執行。
2.4.4 水印【Watermarks】
在我們到目前為止關於事件時間視窗【event-time windows】的討論中,我們忽略了一個非常重要的方面:我們如何決定何時觸發事件時間視窗【event-time windows】?也就是說,我們需要等待多長時間才能確定我們已經完整的接收到了某個時間點之前發生的所有事件?我們怎麼知道資料會被延遲呢?考慮到分散式系統不可預測性和外部元件可能導致的任意延遲,這些問題並沒有絕對正確的答案。在本節中,我們將瞭解如何使用水印的概念來配置事件時間視窗【event-time windows】的行為。
水印是一種全域性進度度量指標,它表示一個我們確信不會再有延遲事件發生的時間點。實際上,水印提供了一個邏輯時鐘,它通知系統當前事件的時間。當運運算元/操作符【operator】接收到時間為T的水印時,它可以假設再也不會接收到時間戳小於T的其他事件。水印對於事件時間視窗【event-time windows】和處理無序事件的運運算元/操作符【operators 】都是必不可少的。一旦接收到水印,就會向運運算元/操作符【operators 】發出訊號,通知它已觀察到一定時間間隔的所有時間戳,並觸發計算或排序接收到的事件。
水印在結果可信度和延遲之間提供了一種可配置的平衡。 熱水印【Eager watermarks】保證了低延遲,但提供較低的結果可信度。在這種情況下,延遲的事件可能會在水印之後到達,我們應該提供一些程式碼來處理它們。另一方面,如果水印很晚才到達,則您有很高的結果可信度,但可能會不必要地增加了處理的延遲。
在許多實際應用中,系統沒有足夠的知識來完美地確定水印。例如,在移動遊戲的情況下,幾乎不可能知道使用者可能會斷開連線多久;他們可能穿過隧道,登上飛機,或者再也不玩了。無論水印是使用者定義的還是自動生成的,當存在掉隊的任務時(即處理速度跟不上其他任務的速度),在分散式系統中追蹤全域性進度總會存在問題
。因此,僅僅依靠水印可能並不總是一個好主意。相反,流處理系統需要提供一些機制來處理水印之後可能到達的事件,這一點至關重要。根據應用程式需求的不同,您可能希望忽略這些事件、記錄它們或使用它們來糾正以前的結果。
2.4.5 Processing time vs. event time
此時,您可能會想:既然事件時間【event time】解決了所有問題,為什麼還要有處理時間【Processing time】呢?事實上,處理時間【Processing time】在某些情況下確實是有用的。處理時間視窗【Processing time window】引入了儘可能低的延遲。由於不考慮到延遲事件和無序事件,因此視窗只需要緩衝事件並在達到指定的時間長度後立即觸發計算。因此,對於速度比準確性更重要的應用程式,處理時間【Processing time】更方便。另一種情況是,您需要定期實時報告結果,而不依賴其準確性時。實時監控儀表板就是一個很好的樣例,當接收到事件後,就會將事件聚合值展示出來。最後,處理時間視窗【Processing time window】提供了對流本身的真實表示,對於某些用例來說,這可能也是一個理想的屬性。總而言之,處理時間【Processing time】提供了較低的延遲,但是結果取決於處理的速度,且具有不確定性。另一方面,事件時間【event time】保證了結果的確定性,並允許您處理延遲事件,甚至是無序的事件。
2.5 狀態與一致性模型
現在我們來研究流處理的另一個非常重要的方面,狀態【state】。狀態在資料處理中無處不在。任何有意義的計算都需要它。為了產生結果,UDF在一段時間週期或多個事件中累積狀態,例如計算聚合值或模式檢測(欺詐、釣魚檢測)。有狀態的運運算元/操作符【operators】使用傳入事件和內部狀態來計算並得到輸出。以滾動聚合操作符【operator】為例,該操作符輸出到目前為止所看到的所有事件的sum總和。該操作符將sum的當前值作為其內部狀態,並在每次接收到新事件時更新它。類似地,考慮這麼一個運運算元/操作符【operator】,當它在檢測到在出現“高溫”事件後10分鐘內出現“冒煙”事件時,就發出警報。運運算元/操作符【operator】需要將“高溫”事件儲存在其內部狀態,直到看到“冒煙”事件或10分鐘的時間週期到期為止。
如果我們考慮使用批處理系統來分析無限資料集的情況,那麼狀態的重要性就會更加明顯了。事實上,在現代流處理器出現之前,這是一種非常常見的實現選擇。在這種情況下,一個作業在各個批次的事件集上重複執行。當作業完成時,結果被寫入持久儲存,所有的操作符狀態都將丟失。一旦作業被排程用於在下一批次的事件集上執行,它就無法訪問獲取到之前的作業的狀態。這個問題通常通過將狀態管理委託給外部系統(如資料庫)來解決。相反,連續執行流作業可以大大簡化應用程式程式碼中的狀態操作。在流中,我們擁有跨事件的持久狀態,並且我們可以將其作為程式設計模型中的一等公民公開。可以說,亦可以使用外部系統來管理流狀態,儘管這種設計選擇可能會帶來額外的延遲。
由於流式操作符【operator】處理的資料可能是無限的,因此應該注意不要允許內部狀態無限增長。為了限制狀態大小,操作符【operators】通常維護的是對到目前為止所看到的事件的某種摘要或概要。這樣的摘要可以是一個計數、一個求和、到目前為止所看到的事件的一個樣本、一個視窗緩衝區或一個自定義資料結構,這些結構保留了執行中的應用程式感興趣的一些屬性。
我們可以想象的到,支援有狀態的運運算元/操作符【stateful operator】帶來了一些實現方面的挑戰。首先,系統需要有效地管理狀態並確保它不受併發更新的影響。其次,並行化變得複雜,因為結果取決於狀態和傳入的事件這兩個方面。幸運的是,在許多情況下,您可以通過鍵【key】對狀態進行分割槽,並獨立地管理每個分割槽的狀態。例如,如果您正在處理來自一組感測器的測量資料流,您可以對操作符狀態進行分割槽,來獨立的維護每個感測器的狀態。有狀態的運運算元/操作符【stateful operator】帶來的第三個也是最大的挑戰是確保狀態可以恢復,並且即使出現故障時,狀態也可以正確的恢復以保證結果的正確性。在下一節中,您將詳細瞭解任務失敗和結果保證的細節。
2.5.1 Task failures
流式作業中的操作符狀態【operator state】是非常有價值的,應該防範出現故障。如果在發生故障時狀態丟失,那麼恢復後結果將不正確。流式作業會執行很長一段時間,因此可以在幾天甚至幾個月的時間內收集狀態。在發生故障的情況下,重新處理所有的輸入以重現丟失的狀態,這將是非常昂貴和耗時的。
在本章的開頭,您看到了如何將流式程式建模為(邏輯)資料流圖。在執行之前,這些(邏輯)資料流圖被轉換為由許多相互連線且並行的任務構成的物理資料流圖,每個任務都執行一些操作邏輯,消費輸入流併為其他任務生成輸出流。現實生產中這種設定可以很容易地讓數百個這樣的任務在多個物理機器上並行執行。在長時間執行的流式作業中,這些任務中的每一個都可能在任何時候失敗。如何確保透明地處理此類故障,以便流作業能夠繼續執行呢?事實上,您希望您的流處理器不僅在任務失敗的情況下可以繼續處理,而且還需要提供對於結果和操作符狀態的正確性保證。我們將在本節中討論所有這些問題。
2.5.1 什麼是任務失敗?
對於輸入流中的每個事件,任務均會執行以下步驟:
(1)接收事件,即將其儲存在本地緩衝區中
(2)可能會更新內部狀態
(3)生成輸出記錄。
在任何這些步驟中都可能發生故障,系統必須為故障場景明確地定義其行為。如果任務在第一步中失敗,事件會丟失嗎?如果在更新內部狀態後失敗,在恢復後會還會再次更新狀態嗎?在這種情況下,輸出還會是確定的嗎?
我們假設有可靠的網路連線,這樣就不會有任何記錄被刪除或重複,所有事件最終都以FIFO順序交付到它們的目的地。注意,Flink使用TCP連線,因此這些需求是有保證的。我們還假設有完美的故障檢測器,沒有任何任務會故意表現出惡意行為;也就是說,所有非失敗的任務都遵循上述步驟。
在批處理場景中,您可以輕鬆地解決所有這些問題,因為所有輸入資料都是可用的。最簡單的方法是簡單地重新啟動作業,然後我們必須重放所有資料。然而,在流世界中,處理失敗並不是一個微不足道的問題。流式系統通過提供結果保證,來定義它們在出現故障時的行為。接下來,我們將回顧現代流處理器提供的各種保證型別,以及系統實現這些保證的一些機制。
2.5.2 結果保證
我們描述不同型別的保證之前,我們需要澄清一些在討論流處理器中的任務失敗時經常引起混淆的問題。在本章的其餘部分中,當我們談到“結果保證【result guarantees】”時,我們指的是流處理器內部狀態的一致性。也就是說,我們關心的是應用程式程式碼在從失敗中恢復後所看到的狀態值。注意,流處理器通常只能保證流處理器內部狀態的結果正確性。然而,保證結果唯一的【exactly-once 】被交付給外部系統是非常具有挑戰性的。例如,一旦資料被髮送到接收器節點【sink node】,就很難保證結果的正確性,因為接收器【sink】可能不提供事務來恢復以前編寫的結果。
AT-MOST-ONCE
當任務失敗時,最簡單的處理方式就是不做任何事情來恢復丟失的狀態和重播丟失的事件。至多一次【AT-MOST-ONCE】是保證每個事件最多處理一次的簡單情況。簡而言之,事件可以簡單地刪除,並且沒有任何確機制去保結果的正確性。這種型別的保證也被稱為“無保證”,因為任何一個放棄所有事件的系統都可以實現它。沒有任何保證聽起來是一個糟糕的主意,但是如果您能夠接受近似的結果,並且您所關心的只是提供儘可能低的延遲,那麼它可能是好的。
AT-LEAST-ONCE
在大多數實際應用程式中,我們最基本的要求是不丟失事件。這種型別的保證稱為至少一次【AT-LEAST-ONCE】,這意味著所有事件肯定會被處理,即使其中一些事件可能會被處理多次。如果應用程式的正確性僅取決於資訊的完整性,那麼重複處理是可以接受的。例如,確定輸入流中是否發生了某一特定事件,這可以通過至少一次【at-least-once】保證正確地實現。在最壞的情況下,您將可能會找到多個相同的事件。但是如果我們統計的是某個事件出現的次數,那麼至少一次【at-least-once】保證就很可能會返回我們一個錯誤的結果。
為了確保至少一次【at-least-once】的結果正確性,您需要有一種機制來從源或某個緩衝區中重放事件。持久化事件日誌會將所有事件寫入到永續性的儲存裝置上,以便在任務失敗時可以重播這些事件(這是從源中重放事件的方法)。另一種實現等效功能的方法是使用記錄確認【record acknowledgements】,此方法將每個事件儲存在緩衝區中,直到其處理已被管道中的所有任務確認,此時才可以丟棄該事件。
EXACTLY-ONCE
這是最嚴格、最具挑戰性的一種保證。唯一結果保證意味著不僅不會有事件丟失,而且對於每個事件,它們僅會對內部狀態的更新產生唯一一次影響。從本質上說,唯一保證意味著我們的應用程式將會始終提供正確的結果,就好像從來沒有發生過失敗一樣。
提供唯一【exactly-once】保證的前提是要有至少一次【at-least-once】保證,因此這裡也需要資料重放機制。此外,流處理器還需要確保內部狀態的一致性。也就是說,在恢復之後,它應該知道事件更新是否已經反映在狀態上。事務性更新是一種實現方式,但是,它可能會產生大量的效能開銷。相反,Flink使用輕量級快照機制來實現唯一【exactly-once】結果保證。我們將在第3章討論Flink的容錯演算法。
END-TO-END EXACTLY-ONCE
到目前為止,您看到的保證型別僅涉及流處理器元件。然而,在實際的流架構中,通常有多個互聯的元件。在一個最簡單的情況下,除了流處理器,我們至少還需要有一個源和一個接收器元件。端到端保證是指整個資料處理流水線的結果正確性。在評估端到端保證時,我們必須考慮應用程式管道中的所有元件。每個元件都提供了自己的保證,而整個管道的端到端保證則由每個元件中最弱的那兒保證來決定(PS:水桶擋板的故事)。需要注意的是,有時候你可以通過較弱的保證獲得更強的語義。一種常見的情況就是任務執行冪等操作,例如最大值或最小值。在這種情況下,您可以使用至少一次【at-least-once】保證(這是一種較弱的保證)實現唯一【exactly-once】保證語義(我們通過冪等,使得較弱的保證,獲得了更強的語義----唯一保證)。
2.4 Summary
在本章中,您已經瞭解了資料流式處理的基本概念和思想。您已經瞭解了資料流程式設計模型【dataflow programming model】,並瞭解瞭如何將流應用程式表示為分散式資料流圖【distributed dataflow graph】。接下來,您研究了並行處理無限流的要求,並認識到延遲和吞吐量對於流應用程式的重要性。您已經學習了基本的流操作,以及如何使用視窗在無限的資料輸入流上計算有意義的結果。您已經想知道了流處理中時間的含義,並且比較了事件時間和處理時間的概念。最後,您已經瞭解了為什麼狀態【state】在流應用程式中的重要性,以及如何防範故障並保證正確的結果。
到目前為止,我們已經獨立於Apache Flink細緻的審視了流概念。在本書的其餘部分中,我們將看到Flink如何實現這些概念,以及如何使用它的DataStream API編寫使用到目前為止介紹的所有特性的應用程式。