
Apache Flink流處理(一)
Apache Flink是一個分散式流處理器,它使用直接且富有表現力的API來實現有狀態的流處理應用程式。它以容錯的方式高效地大規模執行此類應用程式。Flink於2014年4月加入Apache軟體基金會作為孵化專案,並於2015年1月成為頂級專案。從一開始,Flink就有一個非常活躍且不斷增長的使用者和貢獻者的社群。到目前為止,已有超過350人蔘與了Flink的工作,它已經發展成為最成熟的開源流處理引擎之一,並被廣泛採用。Flink在全球不同行業的許多公司和企業中為大型關鍵業務應用程式提供支援。
流處理不僅為已建立的用例提供了更好的解決方案,而且還促進了新的應用程式、軟體架構以及商業機會,因此它正迅速的被大大小小各種規模的公司和企業所採用。在本章中,我們將討論為什麼有狀態的流處理變得如此流行,並評估它的潛力。我們首先回顧傳統的資料處理應用程式體系結構【 data processing application architectures】,並指出它們的侷限性。接下來,我們將介紹基於有狀態的流式處理設計的應用程式,與傳統的方法相比,該設計具有許多有趣的特性和優點。我們簡要討論開源流處理器的發展,並幫助您在本地Flink例項上執行第一個流應用程式。最後,我們告訴你在閱讀這本書的時候你會學到什麼。
1.傳統的資料基礎設施[ Data Infrastructures]
公司會使用許多不同的應用程式來執行它們的業務,例如企業資源規劃(ERP)系統、客戶關係管理(CRM)軟體或基於web的應用程式。所有這些系統通常都為資料處理(應用程式本身)和資料儲存(事務性資料庫系統)設計了單獨的分層,如圖1-1所示:
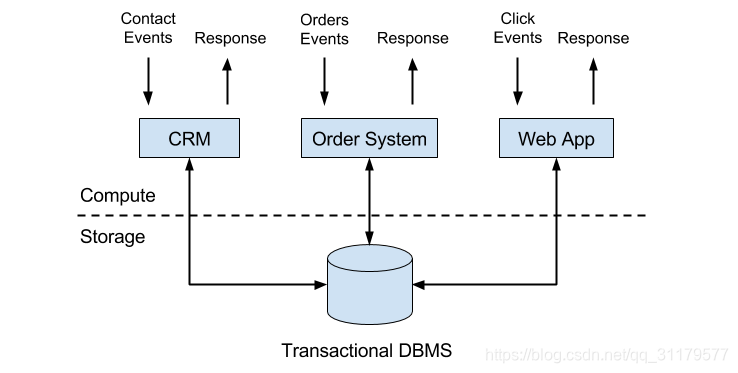
圖1-1 傳統的應用
應用程式通常連線到外部服務或面向人類使用者,並持續處理傳入的事件,如訂單、郵件或網站點選。在處理事件時,應用程式通過對遠端資料庫系統執行事務,來讀取狀態或更新狀態。通常,一個數據庫系統服務於多個應用程式,這些應用程式甚至常常訪問的是相同的庫或表
當應用程式需要演變或擴充套件時,這種設計可能會導致問題。由於多個應用程式可能工作在相同的資料表示【data representation】,或者共享相同的基礎設施,因此更改資料庫表或擴充套件資料庫系統需要仔細的規劃和大量的工作。最近一種克服應用程式緊密捆綁的方法是微服務設計模式。微服務指的是被設計為小型、自包含且獨立的應用程式。他們遵循UNIX的哲學------只做一件事,並把它做好。複雜的應用程式是通過將幾個微服務相互連線而構建的,這些微服務僅通過諸如RESTful HTTP連線之類的標準化介面進行通訊。由於微服務之間是嚴格解耦的,並且只能通過規範的介面進行通訊,因此每個微服務都可以使用自定義技術棧(包括程式語言、庫和資料儲存)來實現。微服務,及其所有必需的軟體和服務,通常被打包/捆綁並部署在獨立的容器中。圖1-2描述了一個微服務體系結構。
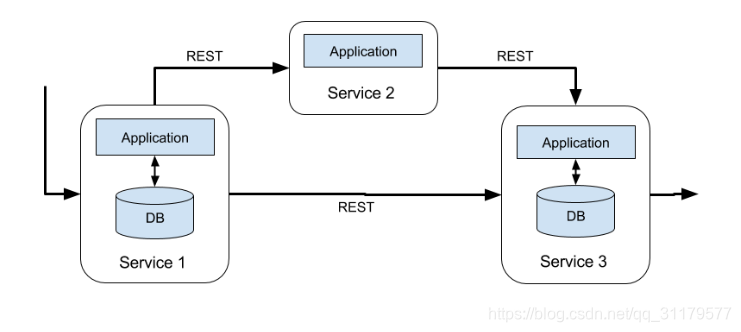
圖1-2 微服務架構
儲存在公司各種事務性資料庫系統中的資料可以為公司業務的各個方面提供有價值的見解。例如,可以對訂單處理系統的資料進行分析,以獲得隨時間的銷售增長、確定延遲發貨的原因或預測未來的銷售以調整庫存。然而,這種事務性資料通常分佈在多個分離的的資料庫系統之間,當它們可以被聯合分析時,事務性資料就會變得更有價值。此外,我們常常需要將資料轉換為通用格式。
IT系統中通常使用一個通用元件—資料倉庫,來實現這樣的需求,而不是直接在事務性資料庫上執行分析查詢。資料倉庫是用於分析查詢工作負載(query workloads)的專用資料庫系統。為了填充資料倉庫,需要將事務性資料庫系統所管理的資料複製到資料倉庫中。將資料複製到資料倉庫的處理過程稱為提取-轉換-載入(extract-transform-load, ETL)。ETL流程從事務性資料庫中提取資料,將其轉換為一種通用的表示形式,其中可能包括驗證、值規範化、編碼、重複資料刪除和模式轉換,最後將其載入到分析資料庫中。ETL處理過程可能非常複雜,通常需要技術複雜的解決方案來滿足對於效能的需求。為了使資料倉庫的資料保持最新,ETL處理過程需要定期執行。
一旦資料被匯入到資料倉庫中,它就可以被查詢和分析。通常,在資料倉庫上執行兩類查詢。第一種型別是定期/週期性的報告查詢【periodic report queries】,用於計算與業務相關的統計資訊,如收益、使用者增長或產量。這些指標被組成有助於評估業務狀況的報告。第二種型別是專門/臨時的的查詢【ad-hoc queries】,這類查詢的目的是為特定問題提供答案,以支援關鍵業務的決策。這兩種查詢都由資料倉庫以批處理方式執行,即,查詢的資料輸入是完全可用的,並且查詢會在返回計算結果之後終止。圖1-3描述了該體系架構。
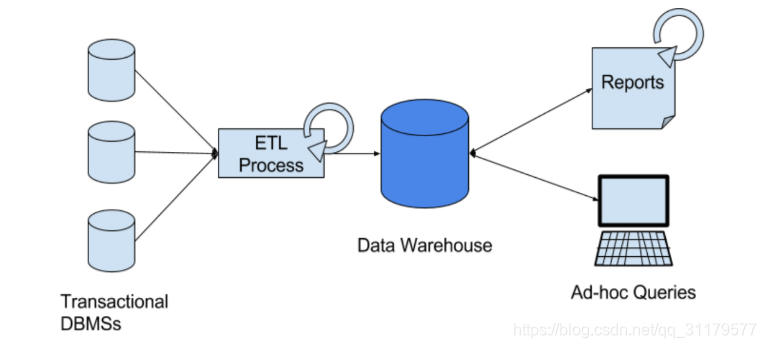
圖1-3 用於資料分析的傳統的資料倉庫
在Apache Hadoop興起之前,專門的分析資料庫系統和資料倉庫是資料分析工作負載【 data analytics workloads】的主要解決方案。然而,隨著Hadoop的日益普及,企業意識到很多有價值的資料被排除在他們以往的資料分析處理之外。通常,這些資料要麼是非結構化的,即不嚴格遵循關係型模式,或者是過於龐大,無法有效地儲存在關係資料庫系統中。今天,Apache Hadoop生態系統的元件是許多企業和公司的IIT基礎設施中不可或缺的一部分。與將所有資料插入關係型資料庫系統不同,而是將大量資料(如日誌檔案、社交媒體或web點選日誌)寫入Hadoop的分散式檔案系統(HDFS)或其他大容量資料儲存(如Apache HBase),它們都以較小的成本提供巨大的儲存容量。駐留在此類儲存系統中的資料可以被SQL-on-hadoop的引擎訪問,例如Apache Hive、Apache Drill或Apache Impala。但是,即使是Hadoop生態系統的儲存系統和執行引擎,其基礎架構的整體執行模式與傳統的資料倉庫架構基本相同,即,定期提取資料並將其載入到資料儲存中,並以批處理方式處理定期/週期性或專門/臨時性查詢。
2.有狀態流處理【Stateful Stream Processing】
一個重要的觀察結果是,幾乎所有的資料都是作為連續的事件流建立的。想想使用者在網站或移動應用程式中的互動、訂單的建立、伺服器日誌或感測器測量;所有這些資料都是事件流。事實上,很難找到一下子就生成的完整且有限的資料集的例子。有狀態的流處理是用於處理無界的事件流的應用程式設計模式,它適用於公司IT基礎結構中的許多不同的用例。在討論它的用例之前,我們簡要地解釋一下什麼是有狀態的流處理以及它是如何工作的。
任何處理事件流且不只是執行一次記錄的簡單轉換的應用程式都需要是有狀態的,即,具有儲存和訪問中間資料的能力。當應用程式接收到一個事件時,它可以執行任意的計算,包括從該狀態中讀取資料或將資料寫入狀態。原則上,狀態可以儲存在不同的地方,也可以從不同的地方被訪問,這些地方包括程式變數、本地檔案、嵌入式或外部資料庫。
Apache Flink將應用程式狀態本地儲存在記憶體中或嵌入式資料庫中,而不是遠端資料庫中。由於Flink是一個分散式系統,因此需要保護本地狀態不受故障影響,以避免在應用程式或機器故障時資料丟失。Flink通過定期將應用程式狀態的一致性檢查點寫入遠端持久化儲存來保證這一點。狀態、狀態一致性和Flink的檢查點機制將在接下來的章節中詳細討論。圖1-4顯示了一個有狀態的Flink應用程式。
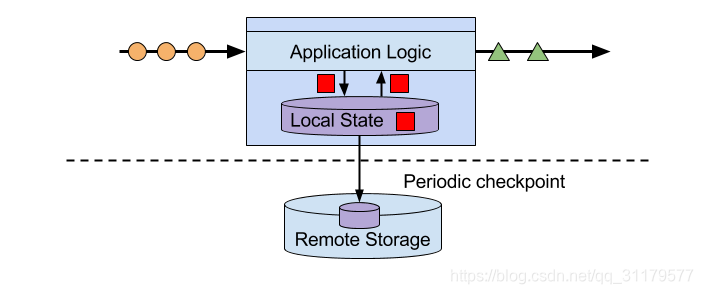
圖1-4 有狀態的流應用程式
有狀態的流處理應用程式通常從事件日誌中攝取其傳入的事件。事件日誌負責儲存和分發事件流。事件被寫入一個持久的(durable)、僅新增(append-only)的日誌中,這意味著事件寫入的順序不能更改。被寫入到事件日誌中的流可以被相同或不同的使用者多次讀取。由於日誌的僅新增(append-only)屬性,事件總是以完全相同的順序釋出給所有消費者。有多個開源的事件系統可以使用,Apache Kafka是最流行的,或者使勇雲端計算提供商提供的整合服務。
出於多種原因,將在Flink上執行的有狀態的流應用程式和事件日誌連線起來很有趣。在這種體系架構中,事件日誌充當真實資料的來源,因為它可以持久化輸入事件,並以確定性的順序重播它們。在發生故障時,Flink通過先前獲取的檢查點來恢復有狀態的流應用程式的狀態,並重置事件日誌上的讀取位置,從而恢復有狀態的流應用程式。應用程式將重放(並快進)來自事件日誌的輸入事件,直到它到達流的尾部。該技術用於從故障中恢復,但也可以用於更新應用程式、修復bug和修復先前發出的結果、將應用程式遷移到不同的叢集或使用不同的應用程式版本執行A /B測試。
如前所述,有狀態的流處理是一種通用且靈活的設計模式,可以用於處理許多不同的用例。在接下來的文章中,我們將介紹三類應用程式:
- 事件驅動的應用程式
- 資料管道應用程式
- 資料分析應用程式
這些應用程式通常使用有狀態的流處理過程來實現,並給出真實世界應用程式的示例。我們將這些類別描述為不同的模式,以強調有狀態流處理的通用性。然而,大多數實際的應用程式都是多個類別的特性的結合體,這再次顯示了這種應用設計模式的靈活性。
2.1事件驅動應用程式
事件驅動的應用程式是有狀態的流應用程式,它接收事件流並在接收的事件上應用業務邏輯。根據業務邏輯的不同,事件驅動的應用程式可以觸發一些操作,比如傳送警報或者電子郵件,或者是將事件寫入到輸出事件流,該輸出事件流可能會被其他事件驅動應用程式作為輸入事件流而消費。
事件驅動應用程式的典型用例包括:
- 實時推薦,例如,當顧客瀏覽零售商的網站時推薦產品
- 模式檢測或複雜事件處理(CEP),例如,用於信用卡交易中的欺詐檢測
- 異常檢測,例如,檢測侵入計算機網路的企圖
事件驅動的應用程式是前面討論的微服務的演變。它們通過事件日誌而不是REST呼叫進行通訊,並將應用程式資料儲存為本地狀態,而不是將其寫入外部資料儲存中或是從外部資料儲存中讀取資料,這類資料儲存包括事務性資料庫或鍵值儲存。圖1-5繪製了一個由事件驅動的流應用程式組成的服務體系結構。
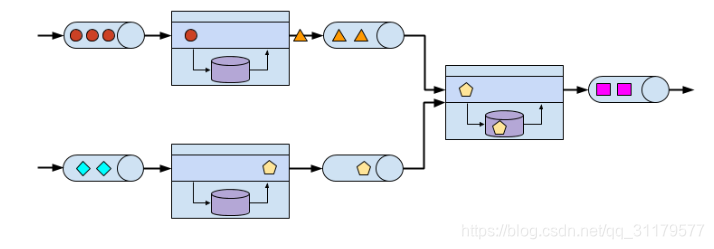
圖1-5 事件驅動應用程式架構
事件驅動的應用程式是一種有趣的設計模式,因為它與傳統的獨立出儲存和計算的分層的體系架構或者目前流行的微服務體系架構相比,它們提供了一些優點。與對遠端資料儲存進行讀寫查詢相比,本地狀態訪問,即從記憶體或本地磁碟進行讀寫操作,提供了非常好的效能。縮放和容錯不需要特別考慮,因為這些方面是由流處理器處理的。最後,通過利用事件日誌作為輸入源,應用程式的完整輸入可以可靠地儲存並以確定的順序重播。這是非常有吸引力的,特別是與Flink的儲存點(savepoint)特性相結合,該特性可以將應用程式的狀態重置為之前的某一一致性的儲存點。通過重置(可能已被修改)應用程式的狀態並重播輸入事件,可以幫助我們修復應用程式的Bug並糾正/訂正其影響,部署新版本的應用程式而不丟失其狀態,或者執行what-if或A/B測試。據我們所知,有一家公司決定基於事件日誌和事件驅動應用程式構建社交網路的後端,原因就在於這些特性。
事件驅動的應用程式對執行它們的流處理器有很高的要求。業務邏輯受它對狀態和時間的控制能力的限制。這個方面取決於流處理器的API、它提供的狀態原語的種類,以及它對事件時間處理所支援的質量。此外,唯一狀態一致性【 exactly-once state consistency 】以及擴充套件應用程式的能力,則是最基本的要求。Apache FLink滿足所有的這些條件,是執行事件驅動應用程式的一個很好的選擇。
2.2資料管道和實時ETL
今天的IT體系結構包括許多不同的資料儲存,例如關係和專用資料庫系統、事件日誌、分散式檔案系統、記憶體快取和搜尋索引。所有這些系統都以不同的表示形式和資料結構儲存資料,以便為它們的特定目提供最佳效能。組織/機構的資料的子集儲存在多個系統中。例如,網上商城提供的產品資訊可以儲存在事務性資料庫、web快取和搜尋索引中。由於資料的這種複製,資料儲存之間必須保持同步。
傳統的方法是使用一個定期的ELT,在儲存系統之間移動資料,而這種方法通常不能足夠快地傳播更新。相反,一種常見的方法是將所有的更改寫入到作為事實(truth,可以理解為真實資料的意思)資料來源的事件日誌中。事件日誌將這些更改釋出給消費者,這些消費者會將這些更改合併到受影響的資料儲存中。根據用例和資料儲存,通常在合併之前需要對資料進行處理。例如,需要對它們進行規範化、與額外資料連線起來,或預先聚合,例如:ETL處理過程通常執行的轉換。
低延遲的攝入、轉換和插入資料是有狀態的流處理應用程式的另一個通用使用場景。我們將這種型別的應用程式稱為資料管道。資料管道的額外要求是能夠在短時間內處理大量資料,即,支援高吞吐量和擴充套件應用程式的能力。操作資料管道的流處理器還應該支援各種source connector和sink connector,以便與各種儲存系統以不同的資料格式進行資料讀寫操作。同樣,Flink提供了操作資料管道所需的所有特性,幷包含許多聯結器。
2.3流分析
在本章之前,我們描述了資料分析管道的通用體系結構。ETL作業定期將資料匯入到資料儲存中,而資料則是由專門的查詢或定時排程的查詢來處理。無論架構是基於資料倉庫還是Hadoop生態系統的元件,基本的操作模式—批處理—這都是相同的。雖然將資料定期載入到資料分析系統的方法多年來一直是最先進的,但它有一個明顯的缺點。
顯然,ETL作業和報告查詢的週期性特性導致了相當大的延遲。根據排程間隔的不同,可能需要數小時或數天的時間,才能將某個資料點包括在報告中。在某種程度上,通過使用資料管道程式將資料匯入到資料儲存,可以減少延遲。然而,即使是連續的ETL,在查詢處理事件之前也總會有一定的延遲。在過去,用幾個小時甚至幾天的延遲來分析資料通常是可以接受的,因為對新結果或見解的迅速響應並沒有產生多麼顯著的優勢。然而,在過去的十年裡,情況發生了戲劇性的變化。快速數字化和互聯絡統的出現,使實時收集更多資料並立即對這些資料採取行動成為可能,例如通過調整以適應不斷變化的條件或個性化的使用者體驗。線上零售商可以在使用者瀏覽其網站時向其推薦產品;手機遊戲可以給使用者贈送虛擬禮物,讓他們留在遊戲中,或者在適當的時候提供遊戲內購買;製造商可以監視機器的行為並觸發維護操作以減少生產中斷。所有這些用例都需要收集實時資料,並以低延遲進行分析,並立即對結果做出反應。傳統的面向批處理的體系結構是無法處理這樣的用例。
您可能並不驚訝於有狀態的流處理是構建低延遲分析管道的正確技術。流分析應用程式不需要等待週期性觸發,而是不斷地接收事件流,並通過低延遲的合併最新事件來維護更新結果。這類似於資料庫系統用來更新物化檢視的檢視維護技術。通常,流應用程式將結果儲存在支援高效更新的外部資料儲存中,例如資料庫或鍵值儲存。此外,Flink還提供了一個名為可查詢狀態【queryable state】的特性,允許使用者將應用程式的狀態作為鍵查詢表【key-lookup table】公開開來,並允許外部應用程式訪問它。流分析應用程式的實時更新結果可用於為儀表板【dashboard】應用程式提供動力,如圖1-6所示。
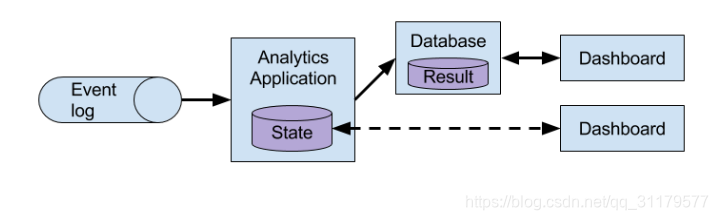
圖1-6 流分析應用程式
除了將事件整合到分析結果中的時間變得要短得多之外,流分析應用程式還有另一個不那麼明顯的優勢。傳統的分析管道由幾個單獨的元件組成,例如ETL處理、儲存系統,在基於hadoop的環境中,還包括一個數據處理器和排程器來觸發作業或查詢。這些元件需要仔細編排,尤其是錯誤處理和故障恢復可能會變得更有挑戰性。
相反,執行有狀態流程式的流處理器會負責所有的處理步驟,包括事件攝入、持續計算(包括狀態維護)和更新結果。此外,流處理器負責以唯一狀態一致性【 exactly-once state consistency】保證從故障中恢復,而且應該能夠調整應用程式的並行性。支援流分析應用的額外需求是:一個是支援按照事件時間【event-time】處理事件,即保證事件處理的順序,以便產生正確和確定的結果,另一個是需要在短時間內處理大量資料的能力,即高吞吐量。Flink為所有這些需求都提供了完美的答案。
流分析應用程式的典型用例是:
- 監控手機網路的質量。
- 分析移動應用程式中的使用者行為。
- 以消費者技術實現實時資料的特別分析。
雖然本書沒有涉及,但值得一提的是Flink還提供了對流的SQL查詢分析的支援。多家公司已經基於Flink的SQL支援構建了流分析服務,既可以用於內部使用,也可以公開提供給付費使用者。
3.開源流處理的演進
資料流處理並不是一種新技術。最早的研究原型和商業產品可以追溯到20世紀90年代末。然而,流處理技術在最近的發展在很大程度上是由成熟的開源流處理器驅動的。今天,分散式開源流處理器為許多企業的關鍵業務應用程式提供支援,這些應用程式橫跨不同的行業,如(線上)零售、社交媒體、電信、遊戲和銀行。開源軟體是這一趨勢的主要驅動力,主要有兩個原因:
- 開源流處理軟體是一種人人都可以評估和使用的商品。
- 由於許多開源社群的努力,可擴充套件的流處理技術正在迅速成熟和發展
僅Apache軟體基金會就有十多個與流處理相關的專案。新的分散式流處理專案正不斷地進入開源階段,並以新的特性和功能挑戰最先進的技術。這些新來者的特性通常被更早一代的流處理器所採用。此外,開源軟體的使用者更是新特性的發起者或者貢獻者。通過這種方式,開源社群不斷改進其專案的能力,並進一步推動流處理的技術邊界。我們將簡要回顧過去,看看開源流處理的前世今生。
第一代分散式開源流處理器得到了廣泛的採用,而主要的關注點落在毫秒級延遲的事件處理,以及提供了在發生故障時不會丟失事件的保證。這些系統具有相當底層的API,並且沒有為流應用程式提供具有準確性和一致性的結果的內建支援,因為結果取決於事件到達的時間和順序。此外,即使事件不會在失敗的情況下丟失,它們也可以被多次處理。與保證準確結果的批處理程式相反,第一批開源流處理器用結果的準確性換取了更好的延遲。資料處理系統(實時的)可以提供快速或準確的結果,這導致了圖1-7所示的所謂的Lambda體系結構的設計。
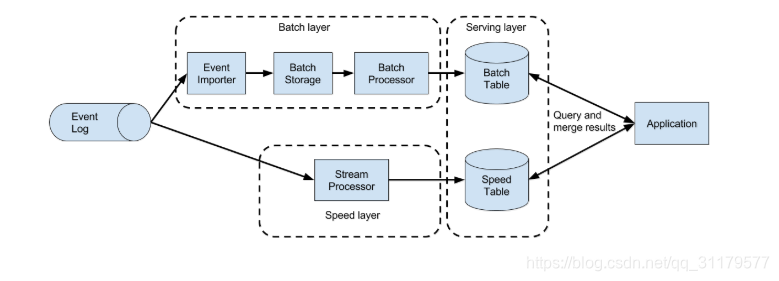
圖1-7 Lambda架構
Lambda體系架構通過一個由低延遲流處理器支援的速度層[Speed Layer],擴充套件了傳統的週期性的批處理體系結構。到達Lambda體系架構的資料被流處理器消化,並被寫入批處理儲存器(如HDFS)。流處理器在接近實時的情況下計算出可能不準確的結果,並將結果寫入速度表【speed table】。寫入到批處理儲存器的資料由批處理程式定期的處理。並將準確的結果寫入批處理表【batch table】中,刪除速度表中相應的不準確結果。應用程式通過合併來自速度表【speed table】中的最新但僅是近似的結果和來自batch表的更老但準確的結果來使用服務層【Service Layer】的結果。Lambda體系結構旨在改善原始批處理分析體系架構的過高的結果延遲。然而,這種方法有一些明顯的缺點。首先,它需要兩個語義等效的應用程式邏輯實現,用於兩個具有不同api的獨立處理系統。其次,流處理器計算的最新結果並不準確,只是近似。第三,Lambda體系結構很難設定和維護。教科書式的設定是由流處理器、批處理器、速度儲存、批儲存和用於接收批處理器資料和排程批作業的工具組成。
下一代分散式開源流處理器在第一代的基礎上進行了改進,提供了更好的故障保證,並確保在出現故障時,每條記錄只對結果貢獻一次。此外,程式設計API從相當低階的操作符介面發展到具有更多內建原語的高階API。然而,一些改進,如更高的吞吐量和更好的故障保證,是以將處理延遲從毫秒增加到秒的為代價的。此外,結果仍然取決於事件到達的時間和順序,即,結果不僅依賴於資料,還依賴於硬體利用率等外部條件。
第三代分散式開源流處理器修復了結果對事件到達的時間和順序的依賴關係。與唯一失敗【 exactly-once failure】的語義相結合,這一代系統是第一個能夠計算一致和準確結果的開源流處理器。通過只基於實際真實資料計算結果,這些系統也能夠以與處理“實時”資料相同的方式來處理歷史資料,即資料一旦被產出,就會立馬被攝入。另一個改進是消除了延遲–吞吐量權衡的分解。雖然以前的流處理器只能提供高吞吐量或低延遲,但是第三代的系統能夠同時滿足這兩個方面的需求。這一代的流處理器使得lambda體系結構過時了。
除了到目前為止討論的系統特性(如容錯、效能和結果精度)之外,流處理器還不斷新增新的操作特性。由於流應用程式通常需要24/7執行,且停機時間最少,因此許多流處理器增加了一些特性,如高可用設定、與資源管理器(如YARN或Mesos)的緊密整合以及動態擴充套件流應用程式的能力。其他特性包括支援升級應用程式程式碼或將作業遷移到不同的叢集或流處理器的新版本,而不會丟失應用程式的當前狀態。
4.Flink淺嘗
Apache Flink是第三代分散式流處理器,具有許多充滿競爭力的特性集。它提供精確的流處理,具有高吞吐量和低延遲。特別值得一提的是,以下功能讓它脫穎而出:
- Flink支援事件時【event-ime】和處理時【processing-time】語義。event-tine提供了一致和準確的結果,即使事件順序被打亂。processing-time適用於對延遲要求非常低的應用程式。
- Flink支援唯一狀態一致性【exactly-once state consistency】保證。
- Flink實現了毫秒延遲,並且能夠每秒處理數百萬個事件。Flink應用程式可以擴充套件到在數千個核心上執行。
- Flink具有層次化的API,在表達性和易用性方面各不相同。本書涵蓋了DataStream API,以及ProcessFunction,這些函式為常見的流處理操作(如視窗操作和非同步操作)提供了原語,還包括精確控制狀態和時間的介面。Flink的關係型APIs, SQL 以及 LINQ-style Table API在本書中沒有討論。
- Flink為最常用的儲存系統(如Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis和(分散式)檔案系統(如HDFS和S3)提供了聯結器。
- Flink能夠24/7地執行流應用程式,由於它的高可用性設定(沒有單點故障)、與YARN和Apache Mesos的緊密整合、從故障中快速恢復以及動態縮放作業的能力,因此幾乎不需要停機。
- Flink允許更新作業的應用程式程式碼,並將作業遷移到不同的Flink叢集,而不會丟失應用程式的狀態。
- 詳細和可定製的系統和應用程式度量集合有助於提前識別和響應問題。
- 最後,Flink也是一個成熟的批處理程式。
除了這些特性之外,Flink由於其易於使用的API,是一個非常適合開發人員的框架。嵌入式執行模式將Flink應用程式作為單個JVM程序啟動,該JVM程序可用於在IDE中執行和除錯Flink作業。這個特性在開發和測試Flink應用程式時非常有用。
接下來,我們將引導您完成啟動本地叢集和執行第一個流應用程式的過程,以便讓您對Flink有一個初步印象。我們將要執行的應用程式對隨機生成的溫度感測器讀數按時間進行轉換和聚合。為此,您的系統需要安裝Java 8(或更高版本)。我們將描述UNIX環境的步驟。如果您正在執行Windows,我們建議您使用Linux、Cygwin(用於Windows的Linux環境)或Windows子系統來設定虛擬機器,這些子系統是在Windows 10中引入的。
- 訪問Apache Flink的網頁flink.apache.org,下載Apache Flink 1.4.0的Hadoop-free二進位制發行版。
- 解壓 : tar -zxvf flink-1.6.0-bin-scala_2.11.tgz
- 啟動flink本地節點
cd flink-1.6.0/
./bin/start-cluster.sh
-
在瀏覽器中輸入URL http://localhost:8081開啟web儀表板。如圖1-8所示,您將看到關於剛剛啟動的本地Flink叢集的一些統計資料。它將顯示一個被連線的工作管理員(Flink的工作程序),一個可用的任務槽(由工作管理員提供的資源單元)。
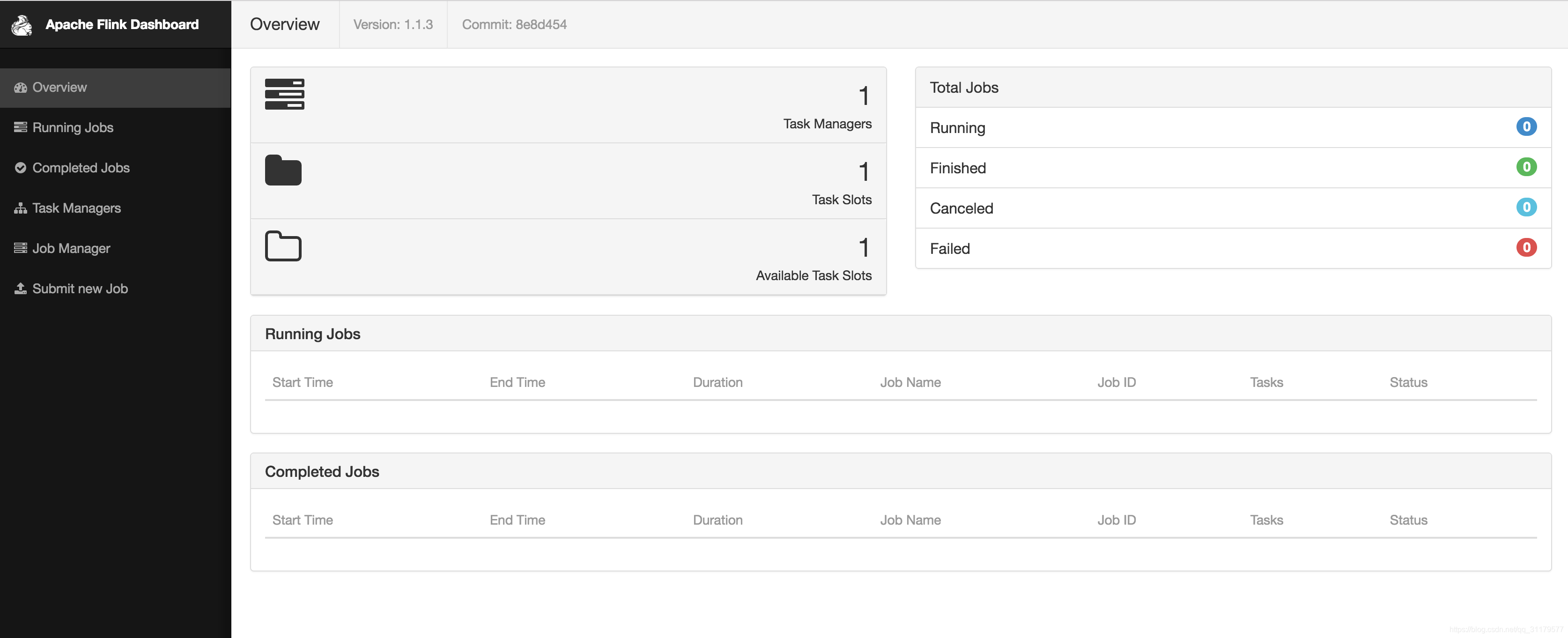
圖1-8 Apache Flink的web儀表板的螢幕截圖顯示概述。
-
下載包含本書所有示例程式的JAR檔案。
wget https://streaming-with-flink.github.io/examples/download/examples-scala.jar
注意:您還可以按照儲存庫的README檔案上的步驟自己構建JAR檔案。
- 通過指定應用程式條目類和JAR檔案,在本地叢集上執行示例:
./bin/flink run -c io.github.streamingwithflink.intro.AverageSensorReadings examples-scala.jar
-
檢查web儀表板。您應該看到在“Running Jobs”下面列出執行中的作業。如果單擊該作業,您將看到關於執行中的作業的操作的資料流和實時度量,如圖1-9所示。
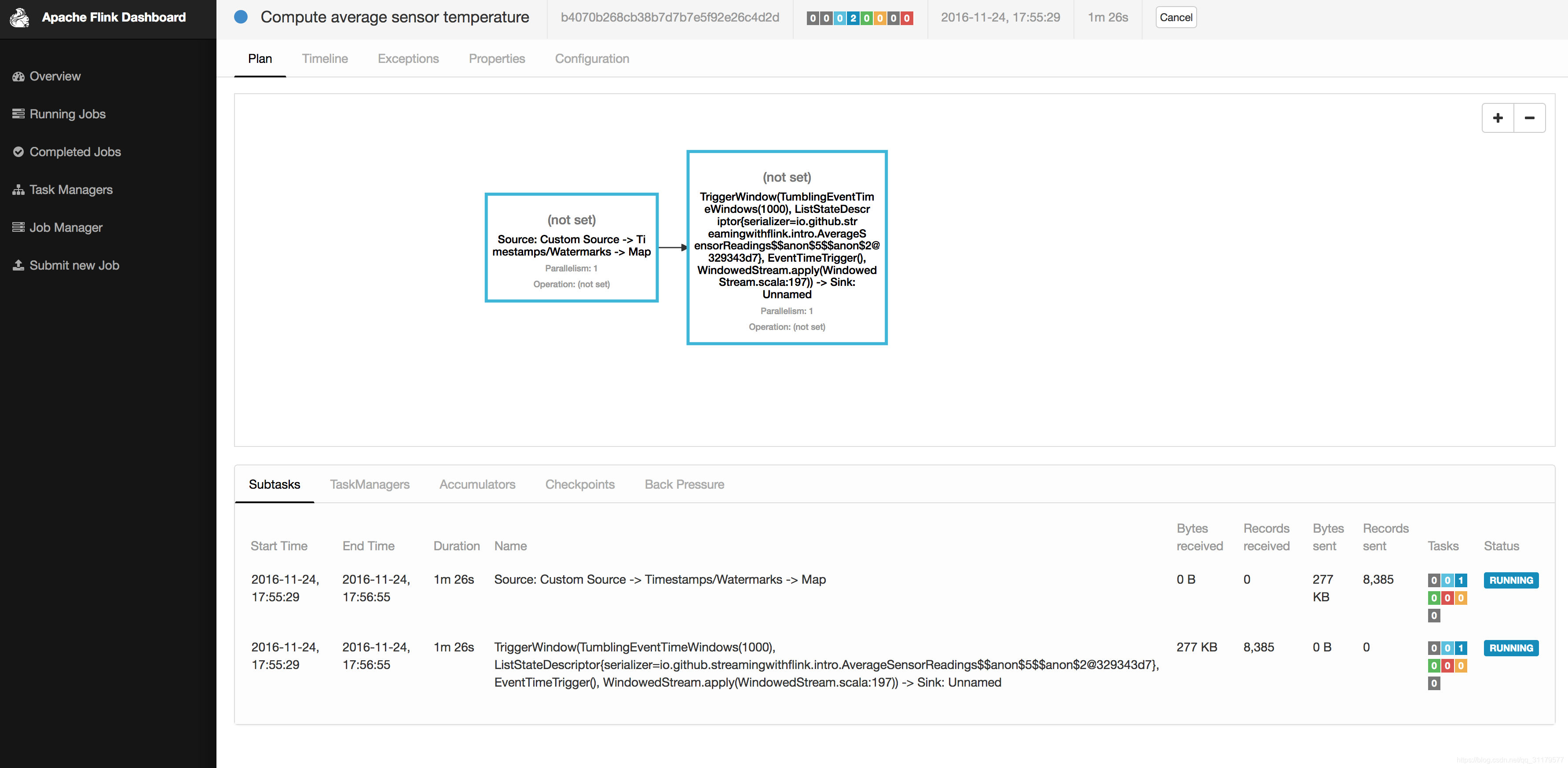
圖1-9 Apache Flink的web儀表板螢幕截圖,顯示一個正在執行的作業。 -
作業的輸出被寫入Flink的工作程序的標準輸出中,該工作程序在預設情況下被重定向到./log資料夾中的一個檔案中。您可以使用tail命令來監視不斷生成的輸出,如下所示:
tail -f ./log/flink-<user>-jobmanager-<hostname>.out
您應該看到以下程式碼行被寫入檔案
SensorReading(sensor_2,1480005737000,18.832819812267438)
SensorReading(sensor_5,1480005737000,52.416477673987856)
SensorReading(sensor_3,1480005737000,50.83979980099426)
SensorReading(sensor_4,1480005737000,-17.783076985394775)
輸出可以讀取如下:SensorReading的第一個欄位是sensorId,第二個欄位是自1970-01-01-00:00以來的毫秒,第三個欄位是計算5秒以上的平均溫度。
- 因為您正在執行一個流應用程式,所以它將繼續持續執行,直到您取消它。您可以通過在web儀表板中選擇作業並單擊頁面頂部的CANCEL按鈕來實現這一點。
- 最後,應該停止本地Flink叢集
./bin/stop-cluster.sh
就是這樣。您剛剛安裝並啟動了第一個本地Flink叢集,並運行了第一個Flink DataStream程式!當然,關於Apache Flink的流處理還有很多要學習的地方,這就是本書的內容。
5.你在本書講學到什麼
本書將教會您關於使用Apache Flink進行流處理的所有知識。第2章討論流處理的基本概念和挑戰,第3章Flink講解用於滿足這些需求的系統架構。第4到8章指導您設定開發環境,介紹DataStream API的基礎知識,並詳細介紹Flink的時間語義和視窗操作符、它與外部系統的聯結器以及Flink容錯操作符狀態。第9章討論瞭如何在各種環境中設定和配置Flink叢集,最後第10章討論瞭如何操作、監視和維護24/7執行的流應用程式。