
K-SVD的理解
阿新 • • 發佈:2018-12-12
K-SVD和MOD最大的不同在於,每次只更新字典的一個原子(即D的一列),而不是每次用一個x更新整個D。
回憶下前面的y=Dx,但是學一個字典,當然不能只用一個數據,現在來升級版: Y = DX哈?小寫變大寫?意思是一組y和其對應的一組x,那麼Y和X指的矩陣。
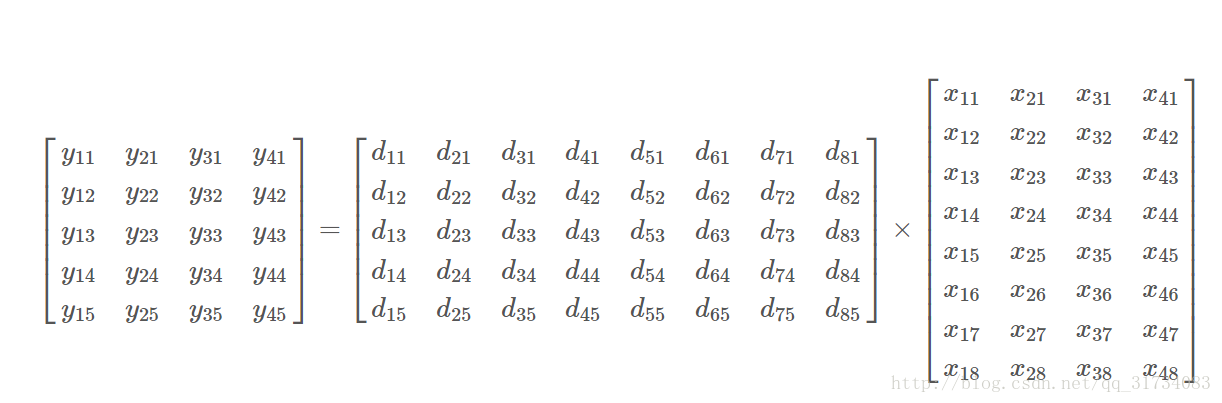
目標函式的轉化:
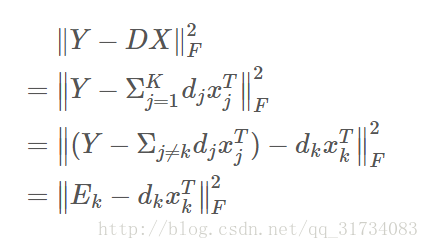
k個原子。求解這裡的 Dk, xkT ,就用到對 E 的SVD分解了。但是直接分解 E 得到的 xkT 並不稀疏。
更新字典和稀疏係數是迭代進行的,在“本次”迭代中,找到“上次”迭代中哪些Y
D的原子k,也就是X的第k行哪些元素不為0,x1k, x2k, x3k, x4k 裡,假設 x1k, x3k 不為0,那麼對應的Y的1,3列就是用到了D的原子k的訊號(Y的每列是一個訊號)。現在把它們拆出來: 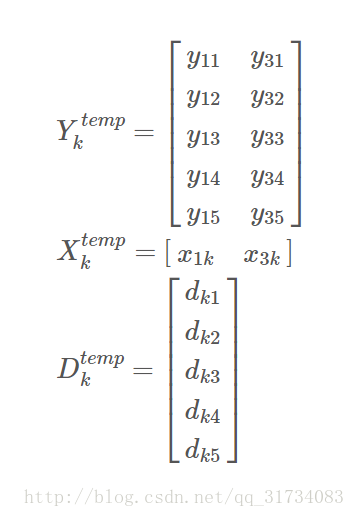
這樣得到只保留非零位置的X、D計算目標函式後得到的只保留對應位置的 Ektemp ,對這個 Ektemp 再做SVD分解,Ektemp = UΣVT, U 的第一列即為新的 $\widetilde{d}_{k}$, V 的第一列與 Σ(1, 1) 的乘積為新的 $\widetilde{x}^{T}_{k}$ 。
逐列更新得到新字典 $\widetilde{D}$