TensorFlow 的資料模型-----張量(Tensor)
作者:man_world
原文地址:https://blog.csdn.net/mzpmzk/article/details/78636137
Tensor 定義
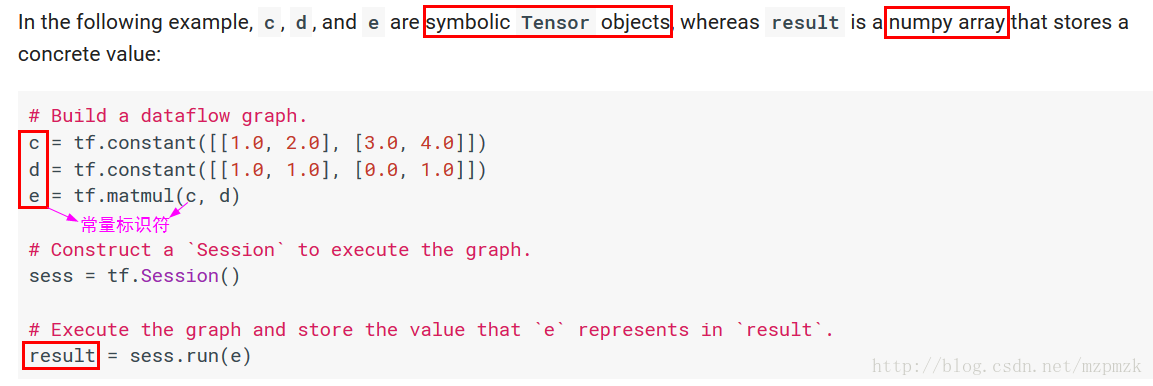
- A Tensor is a symbolic handle to one of the outputs of an Operation. It does not hold the values of that operation’s output, but instead provides a means of computing those values in a TensorFlow
tf.Session. - 在 TensorFlow 中,所有在節點之間傳遞的
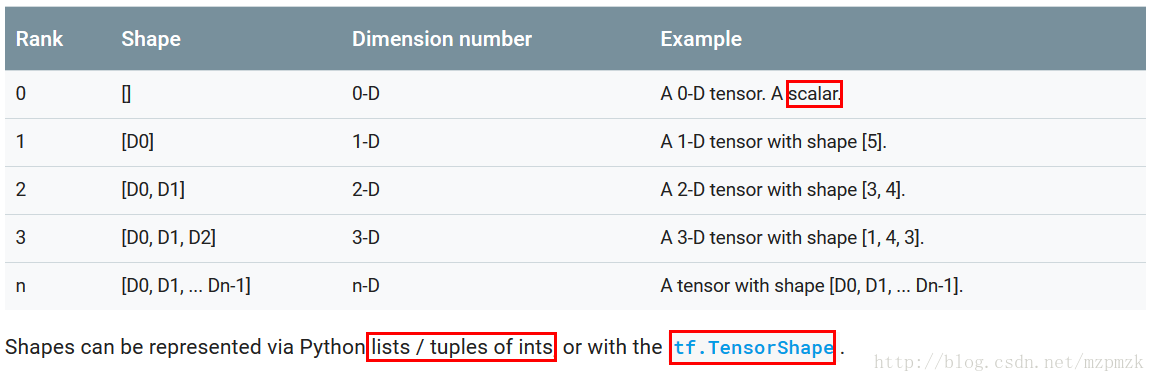
資料都為 Tensor 物件(可以看作n 維的陣列),常用影象資料的表示形式 為:batch*height*width*channel

Tensor-like objects
tf.Tensortf.Variablenumpy.ndarraylist (and lists of tensor-like objects)Scalar Python types: bool, float, int, strNote: By default, TensorFlow will create a new
tf.Tensoreach time you use the same tensor-like object.
Some special tensors
- tf.constant():返回一個
常量 tensor - tf.Variable():返回一個
tensor-like 物件,表示變數 - tf.SparseTensor():返回一個
tensor-like 物件 - tf.placeholder():return a tensor that may be used as a
handle for feeding a value, but not evaluated directly.
二、Tensor 建立
TF op:可接收標準 Python 資料型別,如整數、字串、由它們構成的列表或者Numpy 陣列,並將它們自動轉化為張量。**單個數值將被轉化為0階張量(或標量),數值列表將被轉化為1階張量(向量),由列表構成的列表**將被轉化為2階張量(矩陣),以此類推。Note:shape要以list或tuple的形式傳入
1、常量 Tensor 的建立
-
Constant Value Tensors# 產生全 0 的張量 tf.zeros(shape, dtype=tf.float32, name=None) tf.zeros_like(tensor, dtype=None, name=None)
# 產生全 1 的張量
tf.ones(shape, dtype=tf.float32, name=None)
tf.ones_like(tensor, dtype=None, name=None)
# Creates a tensor of shape and fills it with value
tf.fill(dims, value, name=None)
tf.fill([2, 3], 9) ==> [[9, 9, 9]
[9, 9, 9]]
# 產生常量 Tensor, value 值可為 python 標準資料型別、Numpy 等
tf.constant(value, dtype=None, shape=None, name=‘Const’)
tf.constant(-1.0, shape=[2, 3]) => [[-1., -1., -1.] # Note: 注意 shape 的用法(廣播機制)
[-1., -1., -1.]]
tf.constant([1,2,3,4,5,6], shape=[2,3]) => [[1, 2, 3]
[4, 5, 6]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Sequences
# 產生 num 個等距分佈在 [start, stop] 間元素組成的陣列,包括 start & stop (需為 float 型別)
# increase by (stop - start) / (num - 1)
tf.linspace(start, stop, num,, name=None)
# []為可選引數,步長 delta 預設為 1,start 預設為 0, limit 的值取不到,它產生一個數字序列
tf.range([start], limit, delta=1, dtype=None, name=‘range’)
# eg
tf.range(start=3, limit=18, delta=3) # [3, 6, 9, 12, 15]
tf.range(limit=5) # [0, 1, 2, 3, 4]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Random Tensors
# 正態分佈,預設均值為0,標準差為1.0,資料型別為float32
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 正態分佈,但那些到均值的距離超過2倍標準差的隨機數將被丟棄,然後重新抽取,直到取得足夠數量的隨機數為止, 隨機數 x
# 的取值範圍是
, 從而可以防止有元素與該張量中的其他元素顯著不同的情況出現
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
# 產生在[minval, maxval)之間形狀為 shape 的均勻分佈, 預設是[0, 1)之間形狀為 shape 的均勻分佈
tf.random_uniform(shape, minval=0.0, maxval=1, dtype=tf.float32, seed=None, name=None)
# Randomly shuffles a tensor along its first dimension
tf.random_shuffle(value, seed=None, name=None)
# Randomly crops a tensor to a given size
tf.random_crop(value, size, seed=None, name=None)
# Note:If a dimension should not be cropped, pass the full size of that dimension.
# For example, RGB images can be cropped with size = [crop_height, crop_width, 3]
# Sets the graph-level random seed
tf.set_random_seed(seed)
# 1. To generate the same repeatable sequence for an op across sessions
# set the seed for the op, a = tf.random_uniform([1], seed=1)
# 2. To make the random sequences generated by all ops be repeatable across sessions
# set a graph-level seed, tf.set_random_seed(1234)
# 其它
tf.multinomial(logits, num_samples, seed=None, name=None)
tf.random_gamma(shape,alpha,beta=None,dtype=tf.float32,seed=None,name=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
2、變數 Tensor 的建立
I、Class tf.Variable()
-
常用屬性
dtype、shape、nameinitial_value:Returns the Tensor used as the initial value for the variable.initializer:The initializer operation for this variable,用於初始化此變數sess.run(v.initializer)- op:The Operation that produces this tensor as an output.
- device:The name of the device on which this tensor will be produced, or None.
- graph:The Graph that contains this tensor.
-
常用方法
eval(session=None):Evaluates this tensor in a Session. Returns A numpy ndarray with a copy of the value of this variableget_shape():Alias of Tensor.shape.set_shape(shape): It can be used to provide additional information about the shape of this tensor that cannot be inferred from the graph alone。initialized_value():Returns the value of the initialized variable.read_value():Returns the value of this variable, read in the current context.assign(value, use_locking=False):Assigns a new value to the variable.assign_add(delta, use_locking=False)assign_sub(delta, use_locking=False)
-
Class Variable 定義
# tf.constant 是 op,而 tf.Variable() 是一個類,初始化的物件有多個op var_obj = tf.Variable( initial_value, dtype=None, name=None, trainable=True, collections=None, validate_shape=True )
# 初始化引數
initial_value:可由 Python 內建資料型別提供,也可由常量 Tensor 的內建 op 來快速構建,但所有這些 op 都需要提供 shape
trainable:指明瞭該變數是否可訓練, 會加入 GraphKeys<span class="token punctuation">.</span>TRAINABLE_VARIABLES collection 中去。
collections: List of graph collections keys. The new variable is added to these collections. Defaults to [GraphKeys.GLOBAL_VARIABLES].
validate_shape: If False, allows the variable to be initialized with a value of unknown shape. If True, the default, the shape of initial_value must be known.
# 返回值
變數例項物件(Tensor-like)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
II、tf.get_variable()
# Gets an existing variable with these parameters or create a new one
tf.get_variable(
name,
shape=None,
dtype=None,
initializer=None,
trainable=True,
regularizer=None,
collections=None,
caching_device=None,
partitioner=None,
validate_shape=True,
use_resource=None,
custom_getter=None
)
# 初始化引數
name: The name of the new or existing variable.
shape: Shape of the new or existing variable.
dtype: Type of the new or existing variable (defaults to DT_FLOAT).
initializer: Initializer for the variable if one is created.
trainable: If True also add the variable to the graph collection tf.GraphKeys.TRAINABLE_VARIABLES.
regularizer: A (Tensor -> Tensor or None) function; the result of applying it on a newly created variable will be added to the collection tf.GraphKeys.REGULARIZATION_LOSSES and can be used for regularization.
collections: List of graph collections keys to add the Variable to. Defaults to [GraphKeys.GLOBAL_VARIABLES] (see tf.Variable).
# 返回值
The created or existing Variable, 擁有變數類的所有屬性和方法。
# Note:
>>> name 引數必須要指定,如果僅給出 shape 引數而未指定 initializer,那麼它的值將由 tf.glorot_uniform_initializer 隨機產生,資料型別為tf.float32;
>>> 另外,initializer 可以為一個張量,這種情況下,變數的值和形狀即為此張量的值和形狀(就不必指定shape 了)。
>>> 此函式經常和 tf.variable_scope() 一起使用,產生共享變數
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
III、initializer 引數的初始化
一般要在
tf.get_variable()函式中指定**shape**,因為initializer要用到。
-
tf.constant_initializer()、tf.zeros_initializer()、tf.ones_initializer()tf.constant_initializer( value=0, dtype=dtypes.float32, verify_shape=False )
# 通常偏置項就是用它初始化的。由它衍生出的兩個初始化方法:
I、tf.zeros_initializer()
II、tf.ones_initializer()
init = tf.constant_initializer()
x = tf.get_variable(name=‘v_x’, shape=[2, 3], initializer=init) # 必須指定shape
sess.run(x.initializer)
sess.run(x)
>>> array([[ 0., 0., 0.],
[ 0., 0., 0.]], dtype=float32)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
tf.truncated_normal_initializer()、tf.random_normal_initializer()
# 生成截斷正態分佈的隨機數,方差一般選0.01等比較小的數
tf.truncated_normal_initializer(
mean=0.0,
stddev=1.0,
seed=None,
dtype=tf.float32
)
# 生成標準正態分佈的隨機數,方差一般選0.01等比較小的數
tf.random_normal_initializer(
mean=0.0,
stddev=1.0,
seed=None,
dtype=tf.float32
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
tf.random_uniform_initializer()、tf.uniform_unit_scaling_initializer()
# 生成均勻分佈的隨機數
tf.random_uniform_initializer(
minval=0,
maxval=None,
seed=None,
dtype=tf.float32
)
# 和均勻分佈差不多,只是這個初始化方法不需要指定最小最大值,是通過計算出來的
# 它的分佈區間為[-max_val, max_val]
tf.uniform_unit_scaling_initializer(
factor=1.0,
seed=None,
dtype=tf.float32
)
max_val = math.sqrt(3 / input_size) * self.factor
# input size is obtained by multiplying W’s all dimensions but the last one
# for a linear layer factor is 1.0, relu: ~1.43, tanh: ~1.15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
tf.variance_scaling_initializer()
tf.variance_scaling_initializer(
scale=1.0,
mode='fan_in',
distribution='normal',
seed=None,
dtype=tf.float32
)
# 初始化引數
scale: Scaling factor (positive float).
mode: One of “fan_in”, “fan_out”, “fan_avg”.
distribution: Random distribution to use. One of “normal”, “uniform”.
# 1、當 distribution=“normal” 的時候:
生成 truncated normal distribution(截斷正態分佈)的隨機數,其中mean = 0, stddev = sqrt(scale / n),
n 的計算與 mode 引數有關:
如果mode = “fan_in”, n 為輸入單元的結點數
如果mode = “fan_out”,n 為輸出單元的結點數
如果mode = “fan_avg”,n 為輸入和輸出單元結點數的平均值
# 2、當distribution="uniform”的時候:
生成均勻分佈的隨機數,假設分佈區間為[-limit, limit],則limit = sqrt(3 * scale / n)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
tf.glorot_uniform_initializer()、tf.glorot_normal_initializer()
為了使得在經過多層網路後,訊號不被過分放大或過分減弱,我們儘可能保持每個神經元的輸入和輸出的方差一致! 從數學角度來講,就是讓權重滿足均值為 0,方差為 fanin+fanout2,隨機分佈的形式可以為均勻分佈或者高斯分佈。
# 又稱 Xavier uniform initializer
tf.glorot_uniform_initializer(
seed=None,
dtype=tf.float32
)
# It draws samples from a uniform distribution within [a=-limit, b=limit]
limit: sqrt(6 / (fan_in + fan_out))
fan_in:the number of input units in the weight tensor
fan_out:the number of output units in the weight tensor
mean = (b + a) / 2
stddev = (b - a)**2 /12
# 又稱 Xavier normal initializer
tf.glorot_normal_initializer(
seed=None,
dtype=tf.float32
)
# It draws samples from a truncated normal distribution centered on 0 with
# stddev = sqrt(2 / (fan_in + fan_out))
fan_in:the number of input units in the weight tensor
fan_out:the number of output units in the weight tensor
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
三、 Tensor 初始化及訪問
1、Constants 初始化
- Constants are initialized when you
call tf.constant, and their value can never change.
2、Variables 初始化
-
Variables are not initialized when you call tf.Variable. To initialize all the variables in a TensorFlow program, you must explicitly
call a special operationas follows:# 變數使用前一定要初始化 init = tf.global_variables_initializer() # 初始化全部變數 sess.run(init)
# 使用變數的 initializer 屬性初始化
sess.run(v.initializer)
- 1
- 2
- 3
- 4
- 5
- 6
用另一個變數的初始化值給當前變數初始化
- 由於
tf.global_variables_initializer()是並行地初始化所有變數,所以直接使用另一個變數的初始化值來初始化當前變數會報錯(因為你用另一個變數的值時,它沒有被初始化) - 在這種情況下需要使用另一個變數的
initialized_value()方法。你可以直接把已初始化的值作為新變數的初始值,或者把它當做tensor計算得到一個值賦予新變數。# Create a variable with a random value. weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35), name="weights")
# Create another variable with the same value as ‘weights’.
w2 = tf.Variable(weights.initialized_value(), name=“w2”)
# Create another variable with twice the value of ‘weights’
w_twice = tf.Variable(weights.initialized_value() * 0.2, name=“w_twice”)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
改變變數的值:通過 TF 中的賦值操作,update = tf.assign(old_variable, new_value) or v.assign(new_value)
3、Tensor 的訪問
- 索引
- 一維 Tensor 的索引和 Python 列表類似
(可以逆序索引(arr[ : : -1])和負索引arr[-3]) - 二維 Tensor 的索引:
arr[i, j] == arr[i][j] - 在多維 Tensor 中,如果省略了後面的索引,則返回的物件會是一個維度低一點的
ndarray(但它含有高一級維度上的某條軸上的所有資料) - 條件索引:
arr[conditon] # conditon 可以使用 & | 進行多條件組合
- 一維 Tensor 的索引和 Python 列表類似
- 切片
- 一維 Tensor 的切片和 Python 列表類似
- 二維 Tensor 的索引:
arr[r1:r2, c1:c2:step] # 也可指定 step 進行切片
四、Tensor 常用屬性
-
dtype
tf.float32/64、tf.int8/16/32/64tf.string、tf.bool、tf.complex64、tf.qint8- 不帶小數點的數會被預設為
tf.int32,帶小數點的會預設為tf.float32 - 可使用
tf.cast(x, dtype, name=None)轉換資料型別
-
shape
-
Tensor 的 shape 刻畫了張量每一維的長度,張量的維數由
tf.rank(tensor)來表示
相關推薦
TensorFlow 的資料模型-----張量(Tensor)
作者:man_world 原文地址:https://blog.csdn.net/mzpmzk/article/details/78636137 Tensor 定義 A Tensor is a symbolic handle to one of the outputs of a
3、TensorFlow 的資料模型-----張量(Tensor)
一、Tensor 類簡介 Tensor 定義 A Tensor is a symbolic handle to one of the outputs of an Operation. It do
TensorFlow入門(二) TensorFlow資料模型——張量
1.2 TensorFlow資料模型——張量 1.2.1 張量的概念 在TensorFlow程式中,所有的資料都通過張量的形式來表示。從功能角度上看,張量可以簡單理解為多維陣列,其中零階張量表示為標量(scalar),也就是一個數(張量的型別也可以是字串);第一階張量為向
tensorflow中張量(tensor)的屬性——維數(階)、形狀和資料型別
tensorflow的命名來源於本身的執行原理,tensor(張量)意味著N維陣列,flow(流)意味著基於資料流圖的計算,所以tensorflow字面理解為張量從流圖的一端流動到另一端的計算過程。
tensorflow 中,修改張量tensor特定元素的值
tensorflow中: constant tensor不能直接賦值,否則會報
對tensorflow中張量tensor的理解與tf.argmax()函式的用法
對tensorflow中張量tensor的理解: 一維張量: 如a=[1., 2., 3., 0., 9., ],其shape為(5,),故當我們選擇維度0時(張量的維度總是從第0個維度開始),實際上是在a的最外層括號上進行操作。 我們畫圖來表示: 二維張量: 如b=[
TensorFlow之張量(tensor)
張量(tensor) 在Tensorflow中,所有資料都通過張量的形式來表示,從功能上看,張量可以簡單的被理解為多維陣列。其中零階張量表示標量(scalar),也就是一個數;第一階張量為向量(vector),也就是一個一維陣列;同理第n階張量就是n維陣列。 但是張量
tensorflow中的 張量(tensor)與節點操作(OP)
#所以需要注意的是 張量 不是 節點操作(OP) #tensor1 = tf.matmul(a,b,name='exampleop') #上面這個 定義的只是一個張量,是在一個靜態的圖(graph)中的 #張量在 定義完成之後是不會進行操作的,想
神經網路的資料表示- 張量(tensor)
神經網路使用的資料儲存在多維Numpy陣列中,也叫張量(tensor)。 張量是一個數據容器,張量的維度(dimension)通常叫做軸(axis)。 1. 標量(0D張量) 僅含一個數字的張量叫做標量(scalar,也叫標量張量、零維張量、0D張量)。在Numpy中,一個flo
如何檢視張量tensor,並將其轉換為numpy資料
在tensorflow 中一般資料都是用tensor來表示,而在python 中一般是用numpy包,然而有時候需要列印變數的資料,可用以下方法來列印: 一、 import tensorflow as tf a = tf.constant(2.1) #定義tensor常量 with tf
張量tensor的資料與numpy 資料之間的轉化與列印
在tensorflow 中一般資料都是用tensor來表示,而在python 中一般是用numpy包,然而有時候需要列印變數的資料,所以下面可以程式碼:import tensorflow as tf from tensorflow.examples.tutorials.mni
#####tensorflow+入門筆記︱基本張量tensor理解與tensorflow執行結構 ***********######
Gokula Krishnan Santhanam認為,大部分深度學習框架都包含以下五個核心元件: 張量(Tensor)基於張量的各種操作計算圖(Computation Graph)自動微分(Automatic Differentiation)工具BLAS、cuBLAS、cuDNN等拓展包 . . 一、
Tensorflow獲取張量Tensor的具體維數
獲取Tensor的維數 >>> import tensorflow as tf >>> tf.__version__ '1.2.0-rc1' >>> x=tf.placeholder(dtype=f
TensorFlow筆記-03-張量,計算圖,會話
result 計算過程 運行 代碼 font fontsize ESS category .html TensorFlow筆記-03-張量,計算圖,會話 搭建你的第一個神經網絡,總結搭建八股 基於TensorFlow的NN:用張量表示數據,用計算圖搭建神經網絡,用會話執行
不懂錘爆我係列之Tensorflow入門學習—— 張量拓展函式tile()詳解
第二期,第二期,開始,開始。 在tensorflow中有個很常用的張量擴充套件函式——tile(),看過了許多講解部落格之後,覺得有必要系統的進行一下整理。同時,我將講解一維、二維、乃至多維張量使用tile()的運算過程與規則。 下面,我們還是以一段程式碼為例: imp
TensorFlow輸出列印張量操作
1、簡單地使用Session會話,計算完畢後,需要關閉會話 >>> hello = tf.constant('Hello TensorFlow') >>> sess = tf.Session() >>> print(sess.ru
淺談什麼是張量tensor
淺談什麼是張量tensor 也許你已經下載了TensorFlow,而且準備開始著手研究深度學習。但是你會疑惑:TensorFlow裡面的Tensor,也就是“張量”,到底是個什麼鬼?也許你查閱了維基百科,而且現在變得更加困惑。也許你在NASA教程中看到它,仍然不知道它在說些什麼?問題在於
TensorFlow之稀疏張量表示
構造稀疏張量 SparseTensor(indices, values, dense_shape) indices是一個維度為(n, ndims)的2-D int64張量,指定非零元素的位置。比
TensorFlow中的張量是什麼
TensorFlow用張量這種資料結構來表示所有的資料.你可以把一個張量想象成一個n維的陣列或列表.一個張量有一個靜態型別和動態型別的維數.張量可以在圖中的節點之間流通.階在TensorFlow系統中,張量的維數來被描述為階.但是張量的階和矩陣的階並不是同一個概念.張量的階(
Tensorflow學習筆記——張量、圖、常量、變數(一)
1 張量和圖 TensorFlow是一種採用資料流圖(data flow graphs),用於數值計算的開源軟體庫。其中 Tensor 代表傳遞的資料為張量(多維陣列),Flow 代表使用計算圖進行運算。資料流圖用「結點」(nodes)和「邊」(edges)組成的有向圖來描
-