
論文解讀:A Focused Dynamic Attention Model for Visual Question Answering
阿新 • • 發佈:2018-12-09
這是關於VQA問題的第四篇系列文章。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:A Focused Dynamic Attention Model for Visual Question Answering。
1,主要思想:
Focused Dynamic Attention (FDA)模型: 通過問題的關鍵詞,識別影象中重要的物件;並通過LSTM單元融合來自區域和全域性特徵的資訊。 然後將這種問題驅動的表示與問題表示相結合,並將其輸入到用於生成答案的推理單元中。
2,模型
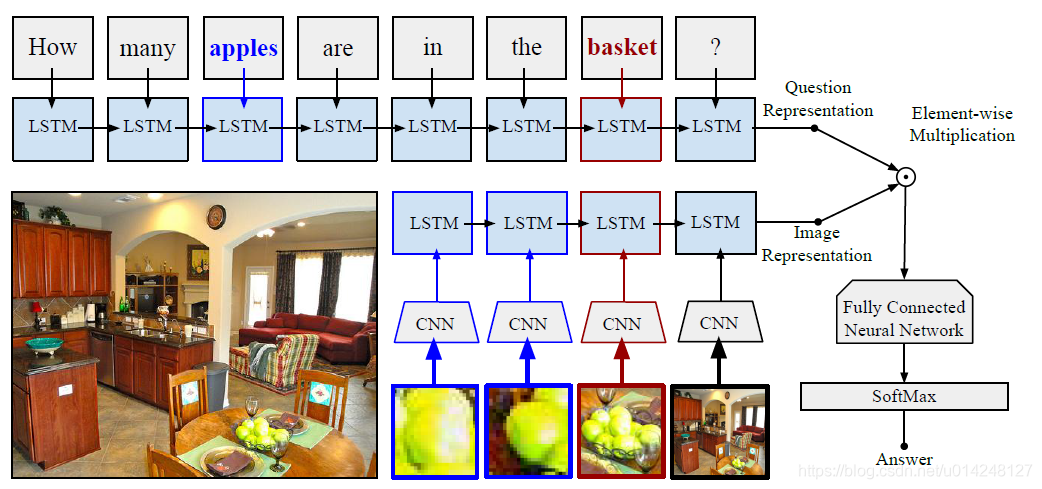
a.問題特徵:
採用LSTM對問題文字提取問題表達資訊。
b.影象特徵
採用預訓練的Deep Residual Networks model獲取影象資訊。
c.Focused Dynamic Attention Mechanism(重要部分)
- 在訓練期間,我們使用真實物件邊界框和標籤。 在測試時,預先計算的邊界框,並用對它們進行分類,以獲得物件標籤。
- 首先: 對於每個影象物件,它使用word2vec單詞嵌入來測量問題單詞和物件標籤之間的相似性。
- 其次: 它選擇相似度得分大於0.5的物件,並用預先訓練的ResNet模型提取物件邊界框的特徵向量。
- 再次: 按照問題單詞順序,把這些影象特徵送入LSTM網路。
- 最後:向LSTM網路提供整個影象的特徵向量,並使用得到的LSTM狀態作為視覺特徵表示
d.產生預測
採用element-wise multiplication融合兩個向量,用全連線加softmax輸出。
3,主要貢獻:
-
提出了FDA模型,用於vqa問題;
-
將區域性和全域性上下文視覺特徵與文字特徵融合在一起
-
在過個模型上對比了開放域和多項選擇兩個資料集
-
FDA可以減少噪聲的影響:只考慮了重要的物件,其他沒有物件的部分都丟掉了。並採用attention機制,找到與問題相關的物件。