
基於PTB資料集實現RNN-LSTM迴圈神經網路(智慧填詞)
阿新 • • 發佈:2018-12-02
本篇直入主題,做一篇學習的記錄,在學習RNN的時候,跟著教程敲了一個案例
分為處理方法檔案,神經網路模型檔案,訓練方法檔案,測試檔案
所有的操作和重要內容都在程式碼中作了詳細的註釋
一、目標神經網路模型
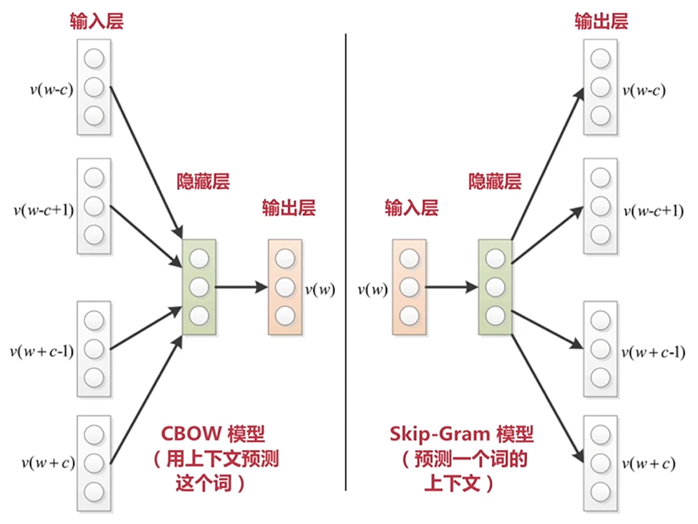

二、資料集
PTB資料集下載地址
或者使用wget進行安裝
wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
三、完整程式碼
1.實用方法utils.py檔案
# zhonghangalex # -*- coding: UTF-8 -*- """ 實用方法 """ import os import sys import argparse import datetime import collections import numpy as np import tensorflow as tf """ 此例子中用到的資料是從 Tomas Mikolov 的網站取得的 PTB 資料集 PTB 文字資料集是語言模型學習中目前最廣泛的資料集。 資料集中我們只需要利用 data 資料夾中的 ptb.test.txt,ptb.train.txt,ptb.valid.txt 三個資料檔案 測試,訓練,驗證 資料集 這三個資料檔案是已經經過預處理的,包含10000個不同的詞語和語句結束識別符號 <eos> 的 要獲得此資料集,只需要用下面一行命令: wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz 如果沒有 wget 的話,就安裝一下: sudo apt install wget 解壓下載下來的壓縮檔案: tar xvf simple-examples.tgz ==== 一些術語的概念 ==== # Batch size : 批次(樣本)數目。一次迭代(Forword 運算(用於得到損失函式)以及 BackPropagation 運算(用於更新神經網路引數))所用的樣本數目。Batch size 越大,所需的記憶體就越大 # Iteration : 迭代。每一次迭代更新一次權重(網路引數),每一次權重更新需要 Batch size 個數據進行 Forward 運算,再進行 BP 運算 # Epoch : 紀元/時代。所有的訓練樣本完成一次迭代 # 假如 : 訓練集有 1000 個樣本,Batch_size=10 # 那麼 : 訓練完整個樣本集需要: 100 次 Iteration,1 個 Epoch # 但一般我們都不止訓練一個 Epoch ==== 超引數(Hyper parameter)==== init_scale : 權重引數(Weights)的初始取值跨度,一開始取小一些比較利於訓練 learning_rate : 學習率,訓練時初始為 1.0 num_layers : LSTM 層的數目(預設是 2) num_steps : LSTM 展開的步(step)數,相當於每個批次輸入單詞的數目(預設是 35) hidden_size : LSTM 層的神經元數目,也是詞向量的維度(預設是 650) max_lr_epoch : 用初始學習率訓練的 Epoch 數目(預設是 10) dropout : 在 Dropout 層的留存率(預設是 0.5) lr_decay : 在過了 max_lr_epoch 之後每一個 Epoch 的學習率的衰減率,訓練時初始為 0.93。讓學習率逐漸衰減是提高訓練效率的有效方法 batch_size : 批次(樣本)數目。一次迭代(Forword 運算(用於得到損失函式)以及 BackPropagation 運算(用於更新神經網路引數))所用的樣本數目 (batch_size 預設是 20。取比較小的 batch_size 更有利於 Stochastic Gradient Descent(隨機梯度下降),防止被困在區域性最小值) """ # 資料集的目錄 data_path = "data" # 儲存訓練所得的模型引數檔案的目錄 save_path = './save' # 測試時讀取模型引數檔案的名稱 load_file = "train-checkpoint-69" parser = argparse.ArgumentParser() # 資料集的目錄 parser.add_argument('--data_path', type=str, default=data_path, help='The path of the data for training and testing') # 測試時讀取模型引數檔案的名稱 parser.add_argument('--load_file', type=str, default=load_file, help='The path of checkpoint file of model variables saved during training') args = parser.parse_args() # 如果是 Python3 版本 Py3 = sys.version_info[0] == 3 # 將檔案根據句末分割符 <eos> 來分割 def read_words(filename): with tf.gfile.GFile(filename, "r") as f: if Py3: return f.read().replace("\n", "<eos>").split() else: return f.read().decode("utf-8").replace("\n", "<eos>").split() # 構造從單詞到唯一整數值的對映 # 後面的其他數的整數值按照它們在資料集裡出現的次數多少來排序,出現較多的排前面 # 單詞 the 出現頻次最多,對應整數值是 0 # <unk> 表示 unknown(未知),第二多,整數值為 1 def build_vocab(filename): data = read_words(filename) # 用 Counter 統計單詞出現的次數,為了之後按單詞出現次數的多少來排序 counter = collections.Counter(data) count_pairs = sorted(counter.items(), key=lambda x: (-x[1], x[0])) words, _ = list(zip(*count_pairs)) # 單詞到整數的對映 word_to_id = dict(zip(words, range(len(words)))) return word_to_id # 將檔案裡的單詞都替換成獨一的整數 def file_to_word_ids(filename, word_to_id): data = read_words(filename) return [word_to_id[word] for word in data if word in word_to_id] # 載入所有資料,讀取所有單詞,把其轉成唯一對應的整數值 def load_data(data_path): # 確保包含所有資料集檔案的 data_path 資料夾在所有 Python 檔案 # 的同級目錄下。當然了,你也可以自定義資料夾名和路徑 if not os.path.exists(data_path): raise Exception("包含所有資料集檔案的 {} 資料夾 不在此目錄下,請新增".format(data_path)) # 三個資料集的路徑 train_path = os.path.join(data_path, "ptb.train.txt") valid_path = os.path.join(data_path, "ptb.valid.txt") test_path = os.path.join(data_path, "ptb.test.txt") # 建立詞彙表,將所有單詞(word)轉為唯一對應的整數值(id) word_to_id = build_vocab(train_path) # 訓練,驗證和測試資料 train_data = file_to_word_ids(train_path, word_to_id) valid_data = file_to_word_ids(valid_path, word_to_id) test_data = file_to_word_ids(test_path, word_to_id) # 所有不重複單詞的個數 vocab_size = len(word_to_id) # 反轉一個詞彙表:為了之後從 整數 轉為 單詞 id_to_word = dict(zip(word_to_id.values(), word_to_id.keys())) print(word_to_id) print("===================") print(vocab_size) print("===================") print(train_data[:10]) print("===================") print(" ".join([id_to_word[x] for x in train_data[:10]])) print("===================") return train_data, valid_data, test_data, vocab_size, id_to_word # 生成批次樣本 def generate_batches(raw_data, batch_size, num_steps): # 將資料轉為 Tensor 型別 raw_data = tf.convert_to_tensor(raw_data, name="raw_data", dtype=tf.int32) data_len = tf.size(raw_data) batch_len = data_len // batch_size # 將資料形狀轉為 [batch_size, batch_len] data = tf.reshape(raw_data[0: batch_size * batch_len], [batch_size, batch_len]) epoch_size = (batch_len - 1) // num_steps # range_input_producer 可以用多執行緒非同步的方式從資料集裡提取資料 # 用多執行緒可以加快訓練,因為 feed_dict 的賦值方式效率不高 # shuffle 為 False 表示不打亂資料而按照佇列先進先出的方式提取資料 i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue() # 假設一句話是這樣: “我愛我的祖國和人民” # 那麼,如果 x 是類似這樣: “我愛我的祖國” x = data[:, i * num_steps:(i + 1) * num_steps] x.set_shape([batch_size, num_steps]) # y 就是類似這樣(正好是 x 的時間步長 + 1): “愛我的祖國和” # 因為我們的模型就是要預測一句話中每一個單詞的下一個單詞 # 當然這邊的例子很簡單,實際的資料不止一個維度 y = data[:, i * num_steps + 1: (i + 1) * num_steps + 1] y.set_shape([batch_size, num_steps]) return x, y # 輸入資料 class Input(object): def __init__(self, batch_size, num_steps, data): self.batch_size = batch_size self.num_steps = num_steps self.epoch_size = ((len(data) // batch_size) - 1) // num_steps # input_data 是輸入,targets 是期望的輸出 self.input_data, self.targets = generate_batches(data, batch_size, num_steps)
2.神經網路模型network.py檔案
# zhonghangalex # -*- coding: UTF-8 -*- import tensorflow as tf # 神經網路的模型 class Model(object): # 建構函式 def __init__(self, input_obj, is_training, hidden_size, vocab_size, num_layers, dropout=0.5, init_scale=0.05): self.is_training = is_training self.input_obj = input_obj self.batch_size = input_obj.batch_size self.num_steps = input_obj.num_steps self.hidden_size = hidden_size # 讓這裡的操作和變數用 CPU 來計算,因為暫時(貌似)還沒有 GPU 的實現 with tf.device("/cpu:0"): # 建立 詞向量(Word Embedding),Embedding 表示 Dense Vector(密集向量) # 詞向量本質上是一種單詞聚類(Clustering)的方法 embedding = tf.Variable(tf.random_uniform([vocab_size, self.hidden_size], -init_scale, init_scale)) # embedding_lookup 返回詞向量 inputs = tf.nn.embedding_lookup(embedding, self.input_obj.input_data) # 如果是 訓練時 並且 dropout 率小於 1,使輸入經過一個 Dropout 層 # Dropout 防止過擬合 if is_training and dropout < 1: inputs = tf.nn.dropout(inputs, dropout) # 狀態(state)的儲存和提取 # 第二維是 2 是因為對每一個 LSTM 單元有兩個來自上一單元的輸入: # 一個是 前一時刻 LSTM 的輸出 h(t-1) # 一個是 前一時刻的單元狀態 C(t-1) # 這個 C 和 h 是用於構建之後的 tf.contrib.rnn.LSTMStateTuple self.init_state = tf.placeholder(tf.float32, [num_layers, 2, self.batch_size, self.hidden_size]) # 每一層的狀態 state_per_layer_list = tf.unstack(self.init_state, axis=0) # 初始的狀態(包含 前一時刻 LSTM 的輸出 h(t-1) 和 前一時刻的單元狀態 C(t-1)),用於之後的 dynamic_rnn rnn_tuple_state = tuple( [tf.contrib.rnn.LSTMStateTuple(state_per_layer_list[idx][0], state_per_layer_list[idx][1]) for idx in range(num_layers)] ) # 建立一個 LSTM 層,其中的神經元數目是 hidden_size 個(預設 650 個) cell = tf.contrib.rnn.LSTMCell(hidden_size) # 如果是訓練時 並且 Dropout 率小於 1,給 LSTM 層加上 Dropout 操作 # 這裡只給 輸出 加了 Dropout 操作,留存率(output_keep_prob)是 0.5 # 輸入則是預設的 1,所以相當於輸入沒有做 Dropout 操作 if is_training and dropout < 1: cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=dropout) # 如果 LSTM 的層數大於 1, 則總計建立 num_layers 個 LSTM 層 # 並將所有的 LSTM 層包裝進 MultiRNNCell 這樣的序列化層級模型中 # state_is_tuple=True 表示接受 LSTMStateTuple 形式的輸入狀態 if num_layers > 1: cell = tf.contrib.rnn.MultiRNNCell([cell for _ in range(num_layers)], state_is_tuple=True) # dynamic_rnn(動態 RNN)可以讓不同迭代傳入的 Batch 可以是長度不同的資料 # 但同一次迭代中一個 Batch 內部的所有資料長度仍然是固定的 # dynamic_rnn 能更好處理 padding(補零)的情況,節約計算資源 # 返回兩個變數: # 第一個是一個 Batch 裡在時間維度(預設是 35)上展開的所有 LSTM 單元的輸出,形狀預設為 [20, 35, 650],之後會經過扁平層處理 # 第二個是最終的 state(狀態),包含 當前時刻 LSTM 的輸出 h(t) 和 當前時刻的單元狀態 C(t) output, self.state = tf.nn.dynamic_rnn(cell, inputs, dtype=tf.float32, initial_state=rnn_tuple_state) # 扁平化處理,改變輸出形狀為 (batch_size * num_steps, hidden_size),形狀預設為 [700, 650] output = tf.reshape(output, [-1, hidden_size]) # -1 表示 自動推導維度大小 # Softmax 的權重(Weight) softmax_w = tf.Variable(tf.random_uniform([hidden_size, vocab_size], -init_scale, init_scale)) # Softmax 的偏置(Bias) softmax_b = tf.Variable(tf.random_uniform([vocab_size], -init_scale, init_scale)) # logits 是 Logistic Regression(用於分類)模型(線性方程: y = W * x + b )計算的結果(分值) # 這個 logits(分值)之後會用 Softmax 來轉成百分比概率 # output 是輸入(x), softmax_w 是 權重(W),softmax_b 是偏置(b) # 返回 W * x + b 結果 logits = tf.nn.xw_plus_b(output, softmax_w, softmax_b) # 將 logits 轉化為三維的 Tensor,為了 sequence loss 的計算 # 形狀預設為 [20, 35, 10000] logits = tf.reshape(logits, [self.batch_size, self.num_steps, vocab_size]) # 計算 logits 的序列的交叉熵(Cross-Entropy)的損失(loss) loss = tf.contrib.seq2seq.sequence_loss( logits, # 形狀預設為 [20, 35, 10000] self.input_obj.targets, # 期望輸出,形狀預設為 [20, 35] tf.ones([self.batch_size, self.num_steps], dtype=tf.float32), average_across_timesteps=False, average_across_batch=True) # 更新代價(cost) self.cost = tf.reduce_sum(loss) # Softmax 算出來的概率 self.softmax_out = tf.nn.softmax(tf.reshape(logits, [-1, vocab_size])) # 取最大概率的那個值作為預測 self.predict = tf.cast(tf.argmax(self.softmax_out, axis=1), tf.int32) # 預測值和真實值(目標)對比 correct_prediction = tf.equal(self.predict, tf.reshape(self.input_obj.targets, [-1])) # 計算預測的精度 self.accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 如果是 測試,則直接退出 if not is_training: return # 學習率。trainable=False 表示“不可被訓練” self.learning_rate = tf.Variable(0.0, trainable=False) # 返回所有可被訓練(trainable=True。如果不設定 trainable=False,預設的 Variable 都是可以被訓練的) # 也就是除了不可被訓練的 學習率 之外的其他變數 tvars = tf.trainable_variables() # tf.clip_by_global_norm(實現 Gradient Clipping(梯度裁剪))是為了防止梯度爆炸 # tf.gradients 計算 self.cost 對於 tvars 的梯度(求導),返回一個梯度的列表 grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars), 5) # 優化器用 GradientDescentOptimizer(梯度下降優化器) optimizer = tf.train.GradientDescentOptimizer(self.learning_rate) # apply_gradients(應用梯度)將之前用(Gradient Clipping)梯度裁剪過的梯度 應用到可被訓練的變數上去,做梯度下降 # apply_gradients 其實是 minimize 方法裡面的第二步,第一步是 計算梯度 self.train_op = optimizer.apply_gradients( zip(grads, tvars), global_step=tf.train.get_or_create_global_step()) # 用於更新 學習率 self.new_lr = tf.placeholder(tf.float32, shape=[]) self.lr_update = tf.assign(self.learning_rate, self.new_lr) # 更新 學習率 def assign_lr(self, session, lr_value): session.run(self.lr_update, feed_dict={self.new_lr: lr_value})
3.訓練方法train.py檔案
# zhonghangalex
# -*- coding: UTF-8 -*-
from utils import *
from network import *
def train(train_data, vocab_size, num_layers, num_epochs, batch_size, model_save_name,
learning_rate=1.0, max_lr_epoch=10, lr_decay=0.93, print_iter=50):
# 訓練的輸入
training_input = Input(batch_size=batch_size, num_steps=35, data=train_data)
# 建立訓練的模型
m = Model(training_input, is_training=True, hidden_size=650, vocab_size=vocab_size, num_layers=num_layers)
# 初始化變數的操作
init_op = tf.global_variables_initializer()
# 初始的學習率(learning rate)的衰減率
orig_decay = lr_decay
with tf.Session() as sess:
sess.run(init_op) # 初始化所有變數
# Coordinator(協調器),用於協調執行緒的執行
coord = tf.train.Coordinator()
# 啟動執行緒
threads = tf.train.start_queue_runners(coord=coord)
# 為了用 Saver 來儲存模型的變數
saver = tf.train.Saver() # max_to_keep 預設是 5, 只儲存最近的 5 個模型引數檔案
# 開始 Epoch 的訓練
for epoch in range(num_epochs):
# 只有 Epoch 數大於 max_lr_epoch(設定為 10)後,才會使學習率衰減
# 也就是說前 10 個 Epoch 的學習率一直是 1, 之後每個 Epoch 學習率都會衰減
new_lr_decay = orig_decay ** max(epoch + 1 - max_lr_epoch, 0)
m.assign_lr(sess, learning_rate * new_lr_decay)
# 當前的狀態
# 第二維是 2 是因為對每一個 LSTM 單元有兩個來自上一單元的輸入:
# 一個是 前一時刻 LSTM 的輸出 h(t-1)
# 一個是 前一時刻的單元狀態 C(t-1)
current_state = np.zeros((num_layers, 2, batch_size, m.hidden_size))
# 獲取當前時間,以便列印日誌時用
curr_time = datetime.datetime.now()
for step in range(training_input.epoch_size):
# train_op 操作:計算被修剪(clipping)過的梯度,並最小化 cost(誤差)
# state 操作:返回時間維度上展開的最後 LSTM 單元的輸出(C(t) 和 h(t)),作為下一個 Batch 的輸入狀態
if step % print_iter != 0:
cost, _, current_state = sess.run([m.cost, m.train_op, m.state], feed_dict={m.init_state: current_state})
else:
seconds = (float((datetime.datetime.now() - curr_time).seconds) / print_iter)
curr_time = datetime.datetime.now()
cost, _, current_state, acc = sess.run([m.cost, m.train_op, m.state, m.accuracy], feed_dict={m.init_state: current_state})
# 每 print_iter(預設是 50)列印當下的 Cost(誤差/損失)和 Accuracy(精度)
print("Epoch {}, 第 {} 步, 損失: {:.3f}, 精度: {:.3f}, 每步所用秒數: {:.2f}".format(epoch, step, cost, acc, seconds))
# 儲存一個模型的變數的 checkpoint 檔案
saver.save(sess, save_path + '/' + model_save_name, global_step=epoch)
# 對模型做一次總的儲存
saver.save(sess, save_path + '/' + model_save_name + '-final')
# 關閉執行緒
coord.request_stop()
coord.join(threads)
if __name__ == "__main__":
if args.data_path:
data_path = args.data_path
train_data, valid_data, test_data, vocab_size, id_to_word = load_data(data_path)
train(train_data, vocab_size, num_layers=2, num_epochs=70, batch_size=20,
model_save_name='train-checkpoint')
4.測試方法test.py檔案
#zhonghangalex
# -*- coding: UTF-8 -*-
from utils import *
from network import *
def test(model_path, test_data, vocab_size, id_to_word):
# 測試的輸入
test_input = Input(batch_size=20, num_steps=35, data=test_data)
# 建立測試的模型,基本的超引數需要和訓練時用的一致,例如:
# hidden_size,num_steps,num_layers,vocab_size,batch_size 等等
# 因為我們要載入訓練時儲存的引數的檔案,如果超引數不匹配 TensorFlow 會報錯
m = Model(test_input, is_training=False, hidden_size=650, vocab_size=vocab_size, num_layers=2)
# 為了用 Saver 來恢復訓練時生成的模型的變數
saver = tf.train.Saver()
with tf.Session() as sess:
# Coordinator(協調器),用於協調執行緒的執行
coord = tf.train.Coordinator()
# 啟動執行緒
threads = tf.train.start_queue_runners(coord=coord)
# 當前的狀態
# 第二維是 2 是因為測試時指定只有 2 層 LSTM
# 第二維是 2 是因為對每一個 LSTM 單元有兩個來自上一單元的輸入:
# 一個是 前一時刻 LSTM 的輸出 h(t-1)
# 一個是 前一時刻的單元狀態 C(t-1)
current_state = np.zeros((2, 2, m.batch_size, m.hidden_size))
# 恢復被訓練的模型的變數
saver.restore(sess, model_path)
# 測試 30 個批次
num_acc_batches = 30
# 列印預測單詞和實際單詞的批次數
check_batch_idx = 25
# 超過 5 個批次才開始累加精度
acc_check_thresh = 5
# 初始精度的和,用於之後算平均精度
accuracy = 0
for batch in range(num_acc_batches):
if batch == check_batch_idx:
true, pred, current_state, acc = sess.run([m.input_obj.targets, m.predict, m.state, m.accuracy], feed_dict={m.init_state: current_state})
pred_words = [id_to_word[x] for x in pred[:m.num_steps]]
true_words = [id_to_word[x] for x in true[0]]
print("\n實際的單詞:")
print(" ".join(true_words)) # 真實的單詞
print("預測的單詞:")
print(" ".join(pred_words)) # 預測的單詞
else:
acc, current_state = sess.run([m.accuracy, m.state], feed_dict={m.init_state: current_state})
if batch >= acc_check_thresh:
accuracy += acc
# 列印平均精度
print("平均精度: {:.3f}".format(accuracy / (num_acc_batches - acc_check_thresh)))
# 關閉執行緒
coord.request_stop()
coord.join(threads)
if __name__ == "__main__":
if args.data_path:
data_path = args.data_path
if args.load_file:
load_file = args.load_file
train_data, valid_data, test_data, vocab_size, id_to_word = load_data(data_path)
trained_model = save_path + "/" + load_file
test(trained_model, test_data, vocab_size, id_to_word)
四、結果
1.先進行訓練
直接執行train.py 檔案:
python3 train.py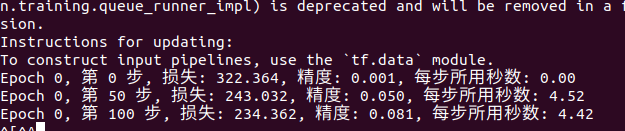
2.進行測試
python3 test.py --load_file train-checkpint -X根據實際測試的檔案確定x
測試結果如下:
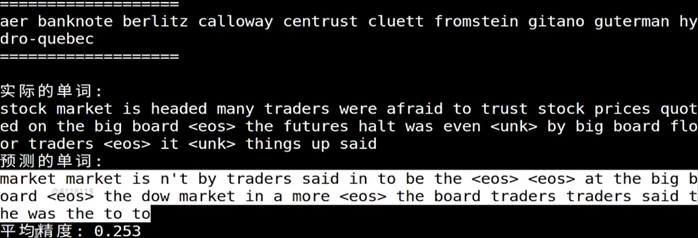
由於時間原因,訓練步數較少,所以測試的精度會差一些。