
Question Answering over Freebase with Multi-Column Convolutional Neural Networks【論文筆記】
一、概要
通過知識庫回答自然語言問題是一個重要的具有挑戰性的任務。大多數目前的系統依賴於手工特徵和規則。本篇論文,我們介紹了MCCNNs,從三個不同層面(答案路徑,答案型別,答案上下文)來理解問題。同時,在知識庫中我們共同學習實體和關係的低維詞向量。問答對用於訓練模型以對候選答案進行排名。我們還利用問題釋義以多工學習方式訓練列網路。我們使用Freebase作為知識庫,在WebQuestions資料集上進行實驗。此外,我們提出了一種計算不同列網路中問題詞的顯著性得分的方法。結果有助於我們直觀地瞭解MCCNN學到的知識。
二、介紹
自動問答系統返回自然語言問題的直接和正確的答案。目前為止,對於這個任務有兩個主流的方法。第一個方法依賴於語義解析,第二個方法依賴於資訊抽取。
語義解析器通過將他們轉換為邏輯形式來理解自然語言問題。然後,解析結果用於生成結構化查詢來查詢知識庫獲得答案。最近的研究工作著重於使用問答對,而不是問題的標註邏輯形式,因為弱訓練訊號降低標註成本。但是,他們中的一些人仍假設一組固定的和預定義的詞彙觸發器,這些觸發器限制了它們的領域和可擴充套件效能力。此外,他們需要手動設計語義解析器的特徵。
第二個方法使用資訊抽取來進行開放域問答。這類方法從知識庫中檢索候選答案的集合,提取問題和候選答案的特徵來對候選答案排名。然而,這類方法依賴於規則和依存分析結果來提取問題的手工特徵。
另外,一些方法使用問題詞向量的總和來表示問題,這忽略了詞序資訊並且不同處理複雜的問題。
本篇論文,我們介紹了MCCNNs從不同方面自動分析問題。該模型共享相同的詞向量來表示問題單詞。MCCNNs從輸入問題中使用不同列的網路來提取答案型別,關係和上下文資訊。知識庫中的實體和關係也都表示為低維向量。然後,評分層根據問題和候選答案的表示對候選答案排名。所提出的基於資訊抽取的方法利用問答對自動學習模型,而不依賴於手工註釋的形式和手工特徵。我們也沒用使用任何的詞法觸發器和規則。此外,問題釋義還用於訓練網路並以多工學習方式概況生詞。早WebQuestions資料集進行實驗,結果優於baseline:
本篇文章有三個貢獻:
- 我們介紹了多列的卷積神經網路來理解問題,不依賴於手工特徵和規則,並且利用問題釋義以多工學習的方式來訓練列網路和詞向量。
- 我們共同學習FREEBASE中實體和關係的低維詞向量,並將問答對作為監督訊號;
- 我們在WEBQUESTIONS資料集上進行了大量實驗,並通過開發一種檢測不同列網路中顯著問題單詞的方法,為MCCNN提供了一些直觀的解釋。
三、相關工作
主要介紹了主流的兩個傳統方法,上面已經介紹過了,這裡不再介紹。
四、建立過程
給定一個自然語言問題q =
…
,我們從FreeBase中檢索相關的實體和屬性,作為候選答案
。我們的目標是對這些候選答案進行評分並且預測答案。一個問題可能有幾個正確答案。為了訓練模型,我們使用沒有標註邏輯形式的問答對。首先我們先描述一下資料集:
WebQuestions:資料集包括3778訓練例項和2032測試例項。將訓練例項分為80%訓練集和20%驗證集。
Freebase:由一般事實組成的大規模知識庫,事實格式為 subject-property-object的三元組。保留其中一個實體出現在WebQuestions的訓練集 / 驗證集或者CLUEWEB的三元組,移除實體次數少於5次的三元組。
WikiAnswers:Fader et al.(2013)在WikiAnswers中提取了相似問題並將他們作為問題釋義,用於概括生詞和問題模式。
五、方法
我們使用多列卷積神經網路來學習問題的表示,模型共享相同的詞向量,這些列描述問題的不同層面。比如答案路徑、答案型別、答案上下文。向量表示為
。相應地,我們也學習候選答案的表示,對每一個候選答案a,表示為
。使用問題和答案的表示,我們可以計算問答對的分數。評分函式S(q,a)定義為:
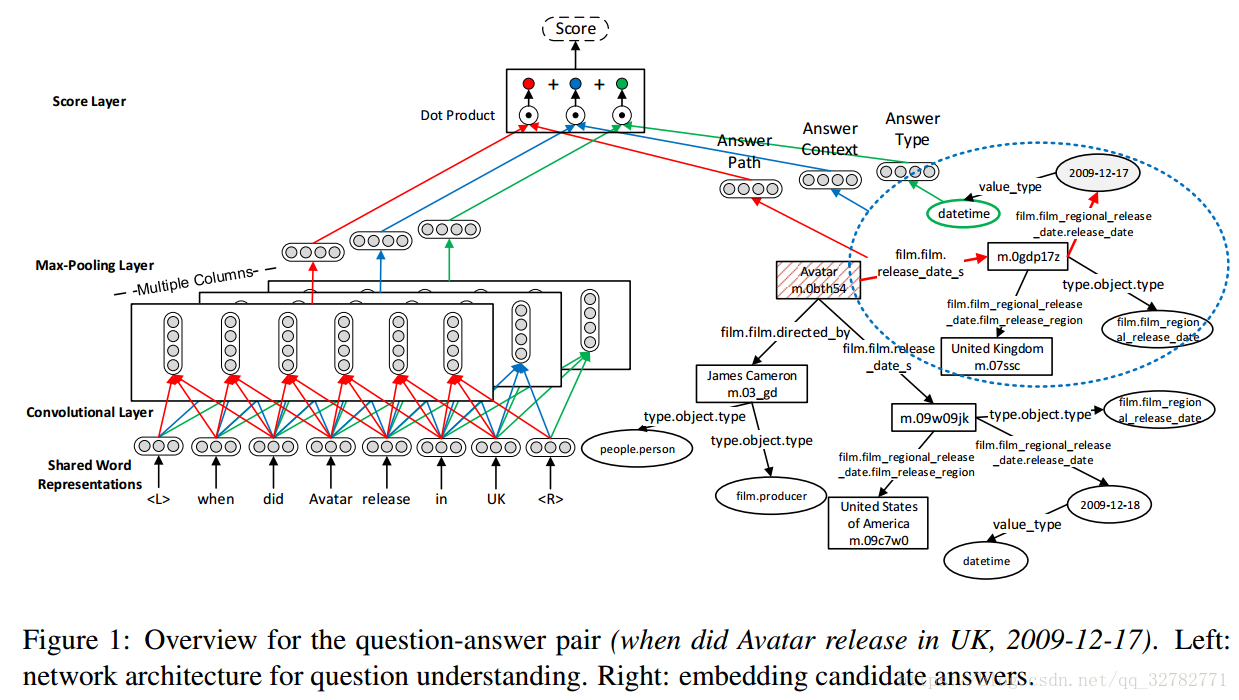
1. 候選答案的生成
給定一個問題,首要步驟就是從Freebase知識庫中檢索候選答案。問題應該包含一個確定的實體,該實體可以連結到知識庫中。我們使用Freebase Search API查詢問題中的命名實體。如果沒有任何命名實體,那麼名詞短語代替。我使用排在第一位置的實體。然後連結到該實體的全部2跳之內的節點作為候選答案。對給定問題q,我們用Cq表示候選答案集。
2. 問題理解
MCCNNs使用多列的卷積神經網路從共享詞向量中學習問題的不同層面的特徵。對於問題q =
,lookup layer將每一個單詞轉換為一個向量
,其中
是詞向量矩陣,
是
的one-hot表示,|V|是詞彙大小。詞向量在訓練過程中更新。
卷積層計算滑動視窗中單詞的表示。對第 i 列的MCCNNs,卷積層對問題q計算n個向量,第j個向量表示如下:
其中(2s + 1)是視窗大小,
是卷積層的權重矩陣,
是bias向量,h(·)是非線性函式(softsign,tanh,sigmoid)。填充左右不存在的單詞。
最終,經過最大池化層獲得問題的固定大小向量表示。在第i列MCCNNs的最大池化層計算問題q的表示通過: