
Udacity資料分析(入門)-分析 A/B 測試結果
分析A/B測試結果
目錄
簡介
對於這個專案,你將要了解的是電子商務網站執行的 A/B 測試的結果。你的目標是通過這個 notebook 來幫助公司弄清楚他們是否應該使用新的頁面,保留舊的頁面,或者應該將測試時間延長,之後再做出決定。
I - 概率
讓我們先匯入庫,然後開始你的任務吧。
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
% 1. 現在,匯入 ab_data.csv 資料,並將其儲存在 df 中。
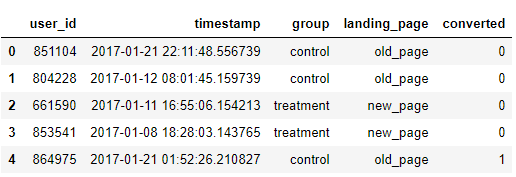
a. 匯入資料集,並在這裡檢視前幾行:
df=pd.read_csv('ab_data.csv')
df.head()
b. 使用下面的單元格來查詢資料集中的行數。
df.shape[0]
294478
c. 資料集中獨立使用者的數量。
df.user_id. d. 使用者轉化的比例。
df.converted.mean()
0.11965919355605512
e. new_page 與treatment 不一致的次數。
treatment = df['group'] == 'treatment'
new_page = df['landing_page'] == 'new_page'
mismatch = treatment != new_page
mismatch.sum()
3893
f. 是否有任何行存在缺失值?
df.isnull().sum()
user_id 0 2. 對於 treatment 不與 new_page 一致的行或 control 不與 old_page 一致的行,我們不能確定該行是否真正接收到了新的或舊的頁面。我們應該如何處理這些行?
a. 現在建立一個符合測試規格要求的新資料集。將新 dataframe 儲存在 df2 中。
df2 = df[~mismatch].copy()
# Double Check all of the correct rows were removed - this should be 0
df2[((df2['group'] == 'treatment') == (df2['landing_page'] == 'new_page')) == False].shape[0]
0
df2[((df2['group'] == 'control') == (df2['landing_page'] == 'old_page')) == False].shape[0]
0
3.
a. df2 中有多少唯一的 user_id?
df2.user_id.nunique()
290584
b. df2 中有一個重複的 user_id 。它是什麼?
df2[df2.user_id.duplicated(keep=False)].user_id
1899 773192
2893 773192
Name: user_id, dtype: int64
c. 這個重複的 user_id 的行資訊是什麼?
df2.query('user_id=="773192"')

d. 刪除 一個 含有重複的 user_id 的行, 但需要確保你的 dataframe 為 df2。
df2=df2.drop_duplicates(subset=['user_id'], keep='first')
sum(df2.duplicated())
0
df2.shape
(290584, 5)
4.
a. 不管它們收到什麼頁面,單個使用者的轉化率是多少?
df2.converted.mean()
0.11959708724499628
b. 假定一個使用者處於 control 組中,他的轉化率是多少?
df2.query('group=="control"')['converted'].mean()
0.1203863045004612
c. 假定一個使用者處於 treatment 組中,他的轉化率是多少?
df2.query('group=="treatment"')['converted'].mean()
0.11880806551510564
d. 一個使用者收到新頁面的概率是多少?
df2.query('landing_page=="new_page"').shape[0]/df2.shape[0]
0.5000619442226688
e. 使用這個問題的前兩部分的結果,給出你的建議:你是否認為有證據表明一個頁面可以帶來更多的轉化?在下面寫出你的答案。
截止目前並沒有證據可以證明某一頁面可以帶來更多的轉化率
II - A/B 測試
請注意,由於與每個事件相關的時間戳,你可以在進行每次觀察時連續執行假設檢驗。
然而,問題的難點在於,一個頁面被認為比另一頁頁面的效果好得多的時候你就要停止檢驗嗎?還是需要在一定時間內持續發生?你需要將檢驗執行多長時間來決定哪個頁面比另一個頁面更好?
1. 現在,你要考慮的是,你需要根據提供的所有資料做出決定。如果你想假定舊的頁面效果更好,除非新的頁面在型別I錯誤率為5%的情況下才能證明效果更好,那麼,你的零假設和備擇假設是什麼? 你可以根據單詞或舊頁面與新頁面的轉化率
與
來陳述你的假設。
零假設: - <=0
備擇假設: - >0
2. 假定在零假設中,不管是新頁面還是舊頁面,
and
都具有等於 轉化 成功率的“真”成功率,也就是說,
與
是相等的。此外,假設它們都等於ab_data.csv 中的 轉化 率,新舊頁面都是如此。
每個頁面的樣本大小要與 ab_data.csv 中的頁面大小相同。
執行兩次頁面之間 轉化 差異的抽樣分佈,計算零假設中10000次迭代計算的估計值。
使用下面的單元格提供這個模擬的必要內容。如果現在還沒有完整的意義,不要擔心,你將通過下面的問題來解決這個問題。
a. 在零假設中, 的 convert rate(轉化率) 是多少?
p_new=df2.converted.mean()
p_new
0.11959708724499628
b. 在零假設中,
的 convert rate(轉化率) 是多少?
p_old=df2.converted.mean()
p_old
0.11959708724499628
c. 是多少?
n_new=df2.query('landing_page=="new_page"').shape[0]
n_new
145310
d. ?是多少?
n_old=df2.query('landing_page=="old_page"').shape[0]
n_old
145274
e. 在零假設中,使用 轉化率模擬 交易,並將這些 1’s 與 0’s 儲存在 new_page_converted 中。
random.seed(42)
new_page_converted=np.random.choice(2,size=n_new,p=[1-p_new,p_new])
new_page_converted
array([0, 0, 0, ..., 0, 0, 1], dtype=int64)
f. 在零假設中,使用 轉化率模擬 交易,並將這些 1’s 與 0’s 儲存在 old_page_converted 中。
random.seed(42)
old_page_converted=np.random.choice(2,size=n_old,p=[1-p_old,p_old])
old_page_converted
array([0, 0, 0, ..., 1, 0, 0], dtype=int64)
g. 在 (e) 與 (f)中找到 - 模擬值。
diff=new_page_converted.mean()-old_page_converted.mean()
diff
0.0004797582554228047
h. 使用**a. 到 g. ** 中的計算方法來模擬 10,000個 - 值,並將這 10,000 個值儲存在 p_diffs 中。
p_diffs=[]
for i in range(10000):
p_new_diff = np.random.choice(2,size=n_new,p=[1-p_new,p_new]).mean()
p_old_diff = np.random.choice(2,size=n_old,p=[1-p_old,p_old]).mean()
p_diffs.append(p_new_diff - p_old_diff)
i. 繪製一個 p_diffs 直方圖。這個直方圖看起來像你所期望的嗎?
p_diffs = np.array(p_diffs)
plt.hist(p_diffs)
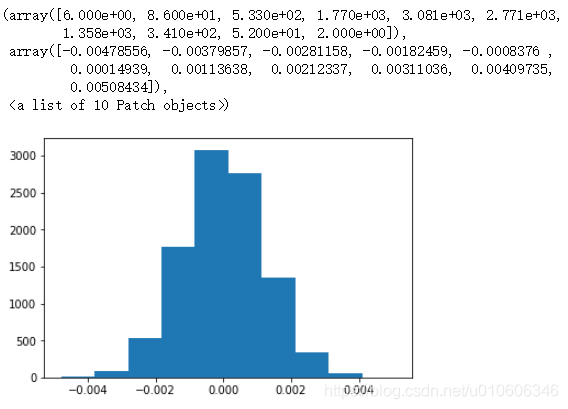
j. 在p_diffs列表的數值中,有多大比例大於 ab_data.csv 中觀察到的實際差值?
obs_diff=df2.query('landing_page=="new_page"')['converted'].mean()-df2.query('landing_page=="old_page"')['converted'].mean()
obs_diff
-0.0015782389853555567
(p_diffs>obs_diff).mean()
0.9079
k. 用文字解釋一下你剛才在 **j.**中計算出來的結果。在科學研究中,這個值是什麼? 根據這個數值,新舊頁面的轉化率是否有區別呢?
p-value,p值等於0.9079較大,我們無法拒絕零假設
l. 我們也可以使用一個內建程式 (built-in)來實現類似的結果。儘管使用內建程式可能更易於編寫程式碼,但上面的內容是對正確思考統計顯著性至關重要的思想的一個預排。填寫下面的內容來計算每個頁面的轉化次數,以及每個頁面的訪問人數。使用 n_old 與 n_new 分別引證與舊頁面和新頁面關聯的行數。
import statsmodels.api as sm
convert_old = df2.query('group=="control" & converted==1').shape[0]
convert_new = df2.query('group=="treatment" & converted==1').shape[0]
n_old = df2.query('group=="control"').shape[0]
n_new = df2.query('group=="treatment"').shape[0]
m. 現在使用 stats.proportions_ztest 來計算你的檢驗統計量與 p-值。這裡 是使用內建程式的一個有用連結。
z_score,p_value=sm.stats.proportions_ztest([convert_old, convert_new], [n_old, n_new],alternative='smaller')
z_score,p_value
(1.3109241984234394, 0.9050583127590245)
from scipy.stats import norm
norm.cdf(z_score),norm.ppf(1-(0.05))
(0.9050583127590245, 1.6448536269514722)
n. 根據上題算出的 z-score 和 p-value,我們認為新舊頁面的轉化率是否有區別?它們與 j. 與 k. 中的結果一致嗎?
由於z-score為1.3109小於1.64485,則我們無法拒絕零假設,這與之前的結果一致。
III - 迴歸分析法之一
1. 在最後一部分中,你會看到,你在之前的A / B測試中獲得的結果也可以通過執行迴歸來獲取。
a. 既然每行的值是轉化或不轉化,那麼在這種情況下,我們應該執行哪種型別的迴歸?
邏輯迴歸
b. 目標是使用 statsmodels 來擬合你在 a. 中指定的迴歸