
.NET開發之效能優化
資料庫效能之表設計
樹表設計:
樹狀表都是使用ID和IDParent兩個欄位來表示樹關係。對樹進行查詢只能使用自關聯方式,不光寫法麻煩而且記錄多的時候查詢效能會非常差。建議在設計樹表的時候可以考慮加入treePath欄位,記載到該節點記錄需要經歷的樹路徑。雖然會增加Insert和Update的成本。但是對查詢樹關係非常有幫助。可以避免大部分的自關聯查詢。
分割槽表:
記錄超過一百萬的表要考慮是否需要使用分割槽表。對於能夠明確確定分割槽欄位,並且經常通過分割槽訪問記錄的。分割槽表會提高查詢效能。
冗餘欄位:
一些關係查詢只查詢類似Code、Name等很少的欄位。可以考慮將頻繁需要關聯查詢的這種欄位冗餘到主表中。這種表設計會要求同步更新兩個字表,對於大部分查詢,會減少表的關聯,提高查詢效能。對於自定義項引用自由項的需求,使用這種冗餘設計能保證報表查詢的便利,能避免聯查表提高了查詢效率。
Code、Name欄位長度
如果業務表中的Code、Name需要建立唯一索引,那Code長度小於nvarchar(32),Name長度小於nvarchar(200)比較合適,不要超過255,避免超過索引鍵長度900bytes的限制
欄位命名
欄位命名試用版不要使用SQLServer關鍵字,此問題雖然和效能無關,但卻是最容易引發BUG的因素。如果在開發階段不杜絕這一問題,以後再修改會增加很多程式碼修改等連帶成本。
資料庫效能之主鍵、索引設計
無主鍵、索引或者沒有查詢索引無效,是產品查詢慢的最常見問題,以下是資料庫表主鍵和索引設計的主要原則
1、主鍵
主鍵ID,主鍵既是約束也是索引,同時也用於物件快取的鍵值。
2、索引
*組合或者引用關係的子表(資料量較大的時候),需要在關聯主表的列上建立非聚集索引(如訂單明細表中的產品ID欄位、訂單明細表中關聯的訂單ID欄位)
*索引鍵的大小不能超過900個位元組,當列表的大小超過900個位元組或者若干列的和超過900個位元組時,資料庫將報錯。
*表中如果建有大量索引將會影響INSERT、UPDATE和DELETE語句的效能,因為在表中的資料更改時,所有的索引都將必須進行適當的調整。需要避免對經常更新的表進行過多的索引,並且索引應保持較窄,就是說:列要儘可能的少。
*為經常用於查詢的謂詞建立索引,如用於下拉參照快速查詢的code、name等。在平臺現有下拉參照的查詢sql語句中的like條件語句要改成不帶前置萬用字元。還有需要關注Order By和Group By謂詞的索引設計,Order By和Group By的謂詞是需要排序的,某些情況下為Order By和Group By的謂詞建立索引,會避免查詢時的排序動作。
*對於內容基本重複的列,比如只有1和0,禁止建立索引,因為該索引選擇性極差,在特定的情況下會誤導優化器做出錯誤的選擇,導致查詢速度極大下降。
*當一個索引有多個列構成時,應注意將選擇性強的列放在前面。僅僅前後次序的不同,效能上就可能出現數量級的差異。
*對小表進行索引可能不能產生優化效果,因為查詢優化器在遍歷用於搜尋資料的索引時,花費的時間可能比執行簡單的表掃描還長,設計索引時需要考慮表的大小。記錄數不大於100的表不要建立索引。頻繁操作的小數量表不建議建立索引(記錄數不大於5000條)
資料庫效能之阻塞
阻塞原因
在預設事務隔離情況下,資料庫事務越長,一方面獨佔鎖被持有的時間越長,寫操作阻塞讀操作的機會就越多;另一方面,在預設的讀提交隔離模式下,讀操作使用共享鎖與獨佔鎖不相容,讀操作也會阻塞寫操作。
阻塞也是死鎖產生的基本條件,改善了阻塞就能有效減少死鎖。
在軟體開發後期,在對大資料量的整合測試工程中,通過活動檢視器可以觀察到阻塞情況,主要產生阻塞的原因就是讀和寫相互阻塞在對同一個大表的操作上。因此對於讀寫阻塞問題需要加以足夠考慮。
減少阻塞一些指導原則
整體原則
*歸結起來也依賴於程式碼、sql的優化,一方面要使邏輯程式碼優化到最快。另一方面,一個耗時較長的sql語句將會阻塞全部使用者等待幾十秒甚至幾分鐘,針對查詢sql語句的優化也是最重要的。
*修改批量操作的需求,批量操作耗時和記錄數量是成正比的。為此設計時要避免在同一個自動事務服務方法中做批量的迴圈操作,可以將迴圈操作放到UI控制端,這一就使一個長事務變成多個短小的事務,將減少阻塞的機會。
*減少讀寫操作使用鎖的數量,比如減少批更新操作中修改行的數量,保證行鎖定少,同時減少鎖升級至表鎖的機會。
*一些耗時大、鎖定資料多的操作需要避免和正常業務操作衝突,可以使用排程計劃在系統閒置的時候來執行,或者使用互斥機制來保證其它使用者暫退出操作獨立執行,視業務情況而定。
讀寫鎖阻塞的處理原則
*減少讀操作需要的共享鎖
1、將事務隔離級別由預設讀提交(ReadCommited)修改成讀未提交(ReadUnCommited),將不會有讀寫阻塞,但是會造成讀取其它事務未提交的資料。
方法一:如果服務方法為自動事務,則在服務方法特性SerivceMethod指定IsolationLevel屬性為ReadUnCommited
方法二:對於使用手工事務的情況,使用DBSession介面帶隔離級別引數的方法session.beginTransaction(IsolationLevel), level值為 ReadUnCommited.
2、在select語句中帶NoLock提示,事務內無鎖提示也不會有讀寫阻塞,與上面一樣也會有髒讀。
Select上加無鎖控制,在執行select操作時加 with(nolock)。如:SELECT * FROM person WITH(NoLock)
上面兩種方式需要平臺和業務涉及人員根據情況使用。事務隔離級別控制粒度較粗,使用時需要考慮對多個select語句的影響,NoLock提示控制單個select語句,粒度更細。
*在sqlserver2005中使用基於行版本的快照隔離模式
在快照模式下,讀取資料不再使用共享鎖,阻塞的現象能大大減少。
方法:在建立資料庫後執行下面命令:
ALTER DATABASE 替換的資料庫名 SET READ_COMMITIED_SNAPSHOT ON;
ALTER DATABASE 替換的資料庫名 SET ALLOW_SNAPSHOT_ISOLATION ON;
注意:sqlserver2005和with(no lock)語句,這兩種方案都能夠避免阻塞,但是這兩種方式是有區別的。
舉個小例子說明一下:比如資料庫表T1中有兩個欄位Col1且其預設值為1.此時恰好有個A事務通過Update語句修改表T1的Col欄位值為2,但還未提交,如下:
A事務:
{
Begion tran
Update T1 set Col1=2
//Commit;//註釋掉此句,模擬A事務未提交。
}
這時如果另一個事務如果使用Sql server2005的快照模式獲取T1表Col1欄位的值則取到的值是之前預設的1;而使用with(no lock)的方式獲取到Col1欄位的值為2.
其實不管使用哪種方式,得到的資料都不確保是準確的,這要取決於A事務是否執行並提交成功。
資料庫效能之死鎖
死鎖原因:
死鎖是由兩個相互阻塞的執行緒組成,它們互相等待對方完成,一般死鎖情況下兩個資料庫事務之間存在著相反的操作。sqlserver中死鎖監視器定時檢查死鎖,如果發現死鎖,將選擇其中回滾消耗最小的任務,這時候發生1025資料庫錯誤。可以通過啟用sqlserver2005快照模式,避免一些讀/寫的逆向阻塞造成的死鎖.但是對於一些寫/寫阻塞的死鎖可能無法解決,很多時候需要從業務的角度來避免一些寫/寫的逆向操作阻塞情況。
死鎖問題的解決很困難,但是可以通過一些手段來使死鎖最小化。
死鎖最小化方法:
從理論上講,資料庫死鎖無法避免,但是可以遵循一定原則使死鎖發生的概率儘量降低。
寫/寫死鎖
*用相同的順序訪問物件,如果涉及到多於一張表的操作,要保證事務中都按照相同的順序訪問這些表。
*減少一個事務中的大批量更新的操作,大批量操作寫操作涉及記錄獨佔鎖太多而且一直到事務結束才能釋放,更容易與其它事務造成死鎖。
讀/寫死鎖(原則上與前面提到的減少讀/寫阻塞方式一致)
*去掉讀操作的共享鎖
最佳方式是使用sql2005的快照模式,其次方式是使用讀未提交隔離模式或使用NOLock提示,需要平臺和業務設計時依據情況進行sql組織的設計。
按照相同的順序訪問物件可以避免相互持有對方請求資源的情況發生。例如一個操作主從表的處理流程,涉及查詢和修改兩個步驟。如果查詢時是先查主表再查從表,則修改也應先修改主表再修改從表。
另一個降低事務大小的一個主要手段,是將查詢操作儘可能地提前(包括使用一些中間變數記錄下查詢結果提供後續使用),而把插入、修改等操作集中在方法靠後的部分。這樣,可以讓一個事務需要持有獨佔鎖的時間儘可能縮短,減少死鎖的發生概率。
資料庫效能之sql效能優化(一)
1、引數化sql
對於一般簡單查詢,資料庫能自動引數啊以重用計劃快取,如:
在sqlserver內部能自動引數化這個查詢,SELECT * FROM table WHERE [email protected]
但是一旦sql語句中帶有join、union、top……等關鍵字,sqlserver內部將不會自動引數化。
在sql2005中,通過alter database XXX set paramenterization forced的強制引數化命令能夠將所有sql中的常量引數化,但是強制引數化會因為常量型別不一致造成查詢結果誤差。
2、使用查詢中的索引有效
a)、單列索引使用原則
單列索引能響應大部分的簡單比較,包括等價和不等價。對於like操作無前置萬用字元也是有效的。如:
| 能有效使用索引的條件語句: |
| [col1]=1 [col1]>100 [col1] between 0 and 100 [col1] like 'abc%' |
下列條件語句不會有效利用索引: |
ABS([col1])=1 [col1]+1>100 [col1]+10 between 0 and 100 [col1] like '%abc%' |
b)、避免在WHERE字句中對欄位進行函式或表示式操作
看一下下面效率低下的例子和其解決方法
| 效率低下的寫法: |
| SELECT * |
| 高效寫法: |
| SELECT * |
下面是SQLServer2005的優化報告
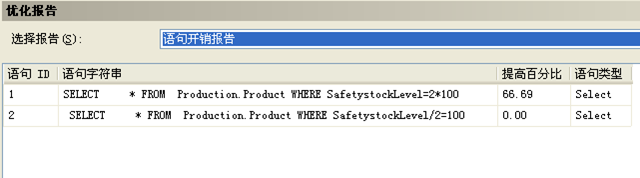
類似的例子:
| 效率低下的寫法 | 高效的寫法 |
| SELECT * |
SELECT * |
| SELECT * |
SELECT * |
任何對列的操作都將導致表掃描,它包括資料庫函式、計算表示式等等,查詢時要儘可能將操作移至等號右邊。
避免使用!=或<>、is null 或is not null、 in、not in等這樣的操作符,因為這會是系統無法使用索引,而只能直接搜尋表中資料。
例如:
select id from employee where id!=’B%’
優化器將無法通過索引來確定將要命中的行數,因此需要搜尋該表的所有行。
c)、多列索引使用原則
則應考慮列的順序。用於等於(=)、大於(>)、小於(<)或between搜尋條件的where 字句或者參與聯接的列應該放在最前面。其它列應該基於其非重要級別進行排序,就是說,從最不重複的列到最重複的列。
例如:
如果表中存在索引定義為LastName、FirstName,則該索引在搜尋條件為where LastName=’Smith’或where LastName=Smith and FirstName like ’j%’時將很有用。不過,查詢優化器不會將此索引用於基於FirstName(where FirstName=’Jane’)而搜尋的查詢。
資料庫效能之sql效能優化(二)
一、SQL拼寫建議
1、查詢時不返回不需要的行、列
業務程式碼要根據實際情況儘量減少對錶的訪問行數,最小化結果集,在查詢時,不要過多地使用萬用字元如:select * from table1語句,要用到幾列就選擇幾列,如:select col1,col2 from table1;在可能的情況下儘量限制結果集行數如:select top 100 col1,col2,col3 from talbe2,因為某些情況下使用者是不需要那麼多的資料的。
2、合理使用EXISTS, NOT EXISTS字句
如下所示:
SELECT SUM(T1.C1) FROM T1 WHERE ((SELECT COUNT(*) FROM T2 WHERE T2.C2=T1.C2)>0)
SELECT SUM(T1.C1) FROM T1 WHERE EXISTS(SELECT * FROM T2 WHERE T2.C2=T1.C2)
兩種產生相同的結果,但是後者的效率顯然要高過於前者。銀行後者不會產生大量鎖定的表掃描或是索引掃描。
經常需要些一個T_SQLL語句比較一個父結果集和子結果集,從而找到是否存在在父結果集中有而在子結果集中乜嘢的記錄,如:
SELECT _a.hdr_key FROM hdr_tb1 a -----------tb1 a 表示tb1用別名a代替
WHERE NOT EXISTS (SELECT * FROM dt1_tb1 b WHERE a.hdr_key = b.hdr_key)
SELECT _a.hdr_key FROM hdr_tb1 a -----------tb1 a 表示tb1用別名a代替
LEFT JION dt1_tb1 b ON a.hdr_key = b.hdr_key WHERE b.hdr_key IS NULL
SELECT hdr_key FROM hdr_tb1
WHERE hdr_key NOT IN (SELECT hdr_key FROM dt1_tb1)
三種寫法都可以得到同樣的結果集,但是效率是依次降低
3、充分利用連線條件
在某種情況下,兩個表之間可能不止一個的連線條件,這時在where 字句中將諒解條件完整的寫上,有可能大大提高查詢速度。
例:
a)、SELECT SUM(A.AMOUNT) FROM ACCOUNT A left jion CARD B on A.CARD_NO = B.CARD_NO
b)、SELECT SUM(A.AMOUNT) FROM ACCOUNT A left jion CARD B on A.CARD_NO = B.CARD_NO AND A.ACCOUNT_NO = B.ACCOUNT_NO
第二句將比第一句執行快得多。
4、WHERE 字句中關係運算符的選擇
a)、在關係運算中,儘量使用=,儘量不要使用<>。
b)、WHERE字句中儘量不要使用NOT運算子,如:NOT IN ,NOT EXISTS, NOT>、NOT<等等NOT運算子一般可以去除。如NOT SALARY >10000K可以改為:salary<=100,如避免使用NOT IN,可以使用 left outer jion代替它。
c)、where 字句中條件表示式間邏輯關係為AND時,將條件為假的概率高的放在前面,概率相同、條件計算簡單的放在前面。
d)、儘可能不要用Order by字句。使用Order by時,儘量減少列數、儘量減少排序資料行數、排序欄位儘量是數字型(儘量不要是字元型)。GROUP BY、 SELECT DITINCT、UNION等字句,也經常導致Order運算。
e)、不要使用Select count(*)方式來判斷記錄是否存在,建議使用Select top 1 from table1 where ……。
f)、不要使用Group by而沒有聚合列。
g)、避免Select 語句的Where 字句條件用於假。如:where 1=0;
h)、如果有多表連線時,應該有主從表之分,並儘量從一個表讀取數,如select a.col1,a.col2 from a jion b on a.col3=b.col4 where b.col5=’a’.
i)、在where 字句中,如果有多個過濾條件,應將所有列或過濾記錄數量最多的條件應該放在前面。
二、使用Truncate清空表
Truncate會將表中記錄全部清空,而不能有選擇性的刪除指定記錄。而DELETE可以指定刪除的記錄。由於Truncate操作在TransactionLog中只記錄被Truncate的頁號,而DELETE需要記載被刪除記錄的詳細內容,因此Truncate會比DELETE更迅速。對大資料表使用Truncate,效果更加明顯。Truncate Table只會刪除表中記錄。而不會對錶的索引和結構造成影響。
三、Union和Union all
Union將兩個結果集合並後,會消除重複記錄,而Union all不會消除重複記錄,而是直接將兩個結果集直接合並。明確得知兩個結果集中沒有重複記錄或者重複記錄不影響使用,建議使用Union all 代替Union。因為Union在消除重複記錄的過程中需要進行排序過濾操作,對大結果集這種排序操作會非常影響效能。下面是Union 和Union all的簡單效能比較:
---------------Union
select * from table1 where code=’01’
Union
select * from table1 where code=’02’
---------------Union all
select * from table1 where code=’01’
union all
select * from talbe1 where code=’02’
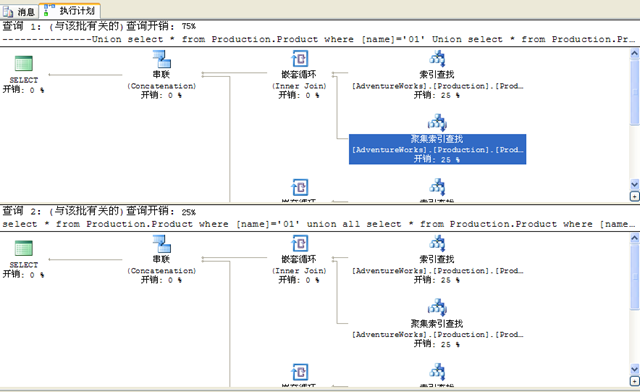
效能優化之C#垃圾回收
垃圾回收時現代語言的標誌之一。垃圾回收解放了手工管理物件釋放的工作,提高了程式的健壯性,但是副作用就是程式程式碼可以對於建立物件變得隨意。
1、避免不必要的物件建立
由於垃圾回收的代價較高,所以C#程式開發要遵循的一個基本原則就是避免不必要的物件建立。以下列舉一些常見的情型。
a)、避免迴圈建立物件
如果物件並不會隨每次迴圈改變而改變狀態,那麼在迴圈中反覆建立物件將帶來效能損耗。例如下面的例子:
SqlBuildResults BuildUpdate(IEntityMap Map,IObjectValue date)
{
SqlBuildResults results = new SqlBuildResults();
foreach(IORMap ormap in map.Maps)
{
UpdateBuilder builder = new UpdateBuilder();
SqlBuildResults result = builder.BuildUpdate(ormap,date);
if(result != null)
results.AddRange(result);
}
return results;
}
高效的做法是將builder物件提到迴圈外面建立。
b)、在需要的邏輯分支中建立物件
如果物件只在默寫邏輯分支中才被用到,那麼應該只在該邏輯分支中建立物件。例如:
protected virtual object OnGetRelation(string childAttrName, IAssociaton association, object relation)
{
ObjectRelationEventArgs args1 = new ObjectRelationEventArgs(association, relation, relation);
if (this.GetRelation != null)
{
this.GetRelation(childAttrName, this.Anchor, args1);
relation = args1.NewRelation;
}
return relation;
}
正確的做法是:
protected virtual object OnGetRelation(string childAttrName, IAssociaton association, object relation)
{
if (this.GetRelation != null)
{
ObjectRelationEventArgs args1 = new ObjectRelationEventArgs(association, relation, relation);
this.GetRelation(childAttrName, this.Anchor, args1);
relation = args1.NewRelation;
}
return relation;
}
c)、使用常量避免建立物件
如下例,程式中存在大量new decimal(0)的程式碼,這會導致小物件頻繁建立及回收;
if (convert1.FromDualQty.RateToBase == new decimal(0))
{
comvert1.FromDualQty.RateToBase == UOMConvertRatio.GetRationBy(……);
}
if (convert1.ToQty.RateToBase == new decimal(0))
{
comvert1.FromDualQty.RateToBase == UOMConvertRatio.GetRationBy(……);
}
正確的做法是使用Decimal.Zero常量。另外,我們也可以學習這個設計手法,應用到類似場景中。
d)、使用StringBuilder做字串連線。
2、不要使用空解構函式
如果類中包含解構函式,則建立物件時會在Finalize佇列中新增物件的引用,以保證當物件無法到達時,人人可以呼叫到Finalize方法。垃圾回收器在執行期間,會啟動一個低優先順序的執行緒處理該佇列。相比之下,沒有解構函式的物件就沒有沒有這些小號。如果解構函式為空,這個消耗就毫無意義,只會導致效能降低!因此,我們儘量不要使用空的解構函式。
從實際情況來看,許多是曾經在解構函式中包含有處理程式碼,但後來因為種種原因被註釋掉或者刪除掉了,只留下一個空的解構函式。此時應該注意把解構函式本身註釋掉或者刪除掉。
3、實現IDisposable介面
垃圾回收事實上只支援託管記憶體的回收,對於其它的非託管的資源,例如:WindowsGDI控制代碼或資料庫連線,在解構函式中是否資源有很大問題,原因是垃圾回收依賴於記憶體緊張情況,雖然資料庫連線可能已瀕臨耗盡,但如果記憶體還很充足的話,垃圾回收是不會執行的。
C#的IDisposable介面是一種顯式釋放資源的機制。通過提供using語句,還簡化了使用方式(編譯器自動生成try…finally塊,並在finally塊中呼叫Dispose方法)。對於申請了非託管資源的物件,應為其實現IDisposable介面,並保證資源一旦超出using語句範圍,即得到及時的釋放。這對於建構函式健壯且效能優良的程式非常有意義!
為防止物件的Dispose方法不被呼叫的情況發生,一般還要提供解構函式,兩者呼叫一個出來資源釋放的公共方法。同時,Dispose方法應呼叫System.GC.SuppressFinalize(this),告訴垃圾回收器無需在處理Finalize方法了。
效能優化之string操作
1、使用StringBuilder做字串連線
string是不變類,使用+操作連線字串會導致建立一個新的字串。如果字串連線次數不是固定的,例如在一個迴圈操作中,則應該使用StringBuilder類來做字串連線工作。因為StringBuilder內部有一個StringBuffer,連線字元操作不會每次分配新的字串空間。只有當連線後的字串超出Buffer大小是,才會申請信的Buffer空間。典型程式碼如下:
StringBuiler sb = new StringBuilder(256);
for(int i = 0; i < str.Count; i++)
{
sb.Append(str[i]);
}
而如果連線字元數十固定的並且只有幾次,此時應該直接用+號連線,保持程式簡潔易讀。實際上,編譯器已經做了優化,會依據加號次數呼叫不同引數個數的String.Concat方法。例如:
String str = str1 + str2 + str3 + str4;
會被編譯成:Sting.Concat(str1,str2,str3,str4).該方法內部會計算總的String長度,僅分配一次,並不會如通常想象的那樣分配三次。作為一個值,當字串連線操作達到10此以上時,則應該使用StringBuilder.
這裡有個細節要注意:StringBuilder內部Buffer的預設值為16,這個實在太小。按照StingBuilder的使用場景,Buffer肯定得重新分配。我建議使用256作為Buffer的初值。當然,如果能計算出最終生成字串長度的話,則應該按這個值來設定Buffer的初值。我曾經開發過一個44位的UUID生成方法,僅僅把new StringBuilder()改為StringBuilder(44)前後就有3倍的效率差異。
2、避免不必要的呼叫ToUpper或ToLower方法
String是不變類,呼叫ToUpper或ToLower方法都會導致建立一個新字串。如果被頻繁呼叫,將導致頻繁建立字串物件。這違背了前面講到的“避免頻繁建立物件”這一基本原則。
例如,bool.Parse方法本身已經是忽略大小寫的,但下面的程式碼每次訪問IsNullable屬性時,都要不必要的呼叫ToLower方法:
public virtual bool IsNullable
{
get
{
if(isSyncDictionary && this.DictionaryItem ! = null)
{
if(this.dictionaryItem.IsNullableValid)
{
return bool.Parse(dictionaryItem.IsNullable.ToString().ToLower());
}
}
}
}
另外一個非常鋪平的場景是字串比較,例如:
foreach (XmlNode node in DocumentElement.ChildNodes)
{
if (node is XmlElement)
{
if (node.Name.ToLower() == "appender")
{
Respoitory.AppenderLoader.Load(node);
}
else if (node.Name.ToLower() == "Render")
{
Respoitory.AppenderLoader.Load(node);
}
else if (node.Name.ToLower() == "Render")
{
Respoitory.RegisterUtilRunner.RunningRegisterUtil(node);
}
}
}
高效的做法是使用Compare方法,這個方法可以做大小寫忽略的比較,並且不會建立新字串:
if(String.Compare(node.Name,"appender",StringComparison.OrdinalIgnoreCase)==0)
最後列舉的一個示例是使用HashTable的時候,有時候無法保證傳遞key的大小寫是否符合預期,往往會把key強制轉換到大小寫方式,例如:myTalbe.Add(myKey.ToLower(),myObject).實際上HashTable有不同的構造方式,完全支援採用忽略大小寫的Key:new HashTable(StringComparer.OrdinalIgnoreCase).
3、最快的空串比較方法
將String物件的Length屬性與0比較式最快的方法:if(str.Length == 0)
其次是與sting.Empty常量或空串比較;if(str == String.Empty)或if(str == "")
注:C#在編譯時會將程式集中宣告的所有字串常量放到保留池中(intern pool),相同常量不會重複分配。
效能優化之多執行緒
1、 執行緒同步
執行緒同步是編寫多執行緒程式需要首先考慮問題。C#為同步提供了 Monitor、Mutex、AutoResetEvent 和 ManualResetEvent 物件來分別包裝 Win32 的臨界區、互斥物件和事件物件這幾種基礎的同步機制。C#還提供了一個lock語句,方便使用,編譯器會自動生成適當的 Monitor.Enter 和 Monitor.Exit 呼叫。
a)、同步粒度
同步粒度可以是整個方法,也可以是方法中某一段程式碼。為方法指定 MethodImplOptions.Synchronized 屬性將標記對整個方法同步。例如:
[MethodImpl(MethodImplOptions.Synchronized)]
public static SerialManager GetInstance()
{
if (instance == null )
{
instance = new SerialManager();
}
return instance;
}
通常情況下,應減小同步的範圍,使系統獲得更好的效能。簡單將整個方法標記為同步不是一個好主意,除非能確定方法中的每個程式碼都需要受同步保護。
b)、同步策略
使用 lock 進行同步,同步物件可以選擇 Type、this 或為同步目的專門構造的成員變數。
避免鎖定Type
鎖定Type物件會影響同一程序中所有AppDomain該型別的所有例項,這不僅可能導致嚴重的效能問題,還可能導致一些無法預期的行為。這是一個很不好的習慣。即便對於一個只包含static方法的型別,也應額外構造一個static的成員變數,讓此成員變數作為鎖定物件。
避免鎖定 this
鎖定 this 會影響該例項的所有方法。假設物件 obj 有 A 和 B 兩個方法,其中 A 方法使用 lock(this) 對方法中的某段程式碼設定同步保護。現在,因為某種原因,B 方法也開始使用 lock(this) 來設定同步保護了,並且可能為了完全不同的目的。這樣,A 方法就被幹擾了,其行為可能無法預知。所以,作為一種良好的習慣,建議避免使用 lock(this) 這種方式。
使用為同步目的專門構造的成員變數
這是推薦的做法。方式就是 new 一個 object 物件, 該物件僅僅用於同步目的。
如果有多個方法都需要同步,並且有不同的目的,那麼就可以為些分別建立幾個同步成員變數。
c)、 集合同步
C#為各種集合型別提供了兩種方便的同步機制:Synchronized 包裝器和 SyncRoot 屬性。
// Creates and initializes a new ArrayList
ArrayList myAL = new ArrayList();
myAL.Add( " The " );
myAL.Add( " quick " );
myAL.Add( " brown " );
myAL.Add( " fox " );
// Creates a synchronized wrapper around the ArrayList
ArrayList mySyncdAL = ArrayList.Synchronized(myAL);
呼叫 Synchronized 方法會返回一個可保證所有操作都是執行緒安全的相同集合物件。考慮 mySyncdAL[0] = mySyncdAL[0] + "test" 這一語句,讀和寫一共要用到兩個鎖。一般講,效率不高。推薦使用 SyncRoot 屬性,可以做比較精細的控制。
2、 使用 ThreadStatic 替代 NameDataSlot
存取 NameDataSlot 的 Thread.GetData 和 Thread.SetData 方法需要執行緒同步,涉及兩個鎖:一個是 LocalDataStore.SetData 方法需要在 AppDomain 一級加鎖,另一個是 ThreadNative.GetDomainLocalStore 方法需要在 Process 一級加鎖。如果一些底層的基礎服務使用了 NameDataSlot,將導致系統出現嚴重的伸縮性問題。
規避這個問題的方法是使用 ThreadStatic 變數。示例如下:
public sealed class InvokeContext
{
[ThreadStatic]
private static InvokeContext current;
private Hashtable maps = new Hashtable();
}
3、多執行緒程式設計技巧
使用 Double Check 技術建立物件
internal IDictionary KeyTable
{
get
{
if ( this ._keyTable == null )
{
lock ( base ._lock)
{
if ( this ._keyTable == null )
{
this ._keyTable = new Hashtable();
}
}
}
return this ._keyTable;
}
}
建立單例物件是很常見的一種程式設計情況。一般在 lock 語句後就會直接建立物件了,但這不夠安全。因為在 lock 鎖定物件之前,可能已經有多個執行緒進入到了第一個 if 語句中。如果不加第二個 if 語句,則單例物件會被重複建立,新的例項替代掉舊的例項。如果單例物件中已有資料不允許被破壞或者別的什麼原因,則應考慮使用 Double Check 技術。
效能優化之型別系統
1、 避免無意義的變數初始化動作
CLR保證所有物件在訪問前已初始化,其做法是將分配的記憶體清零。因此,不需要將變數重新初始化為0、false或null。
//Generally expert 10 or less items private HashTable _items = null; private NameValueCollection = _queryString = null; private string _siteUrl = null; private Uri _currentUri; string rolesCacheKey = null; string authenticationType = "forms"; bool _isUrlRewritten = false; string _rawUrl = null; HttpContext _httpContext = null DateTime requestStarTime = DateTime.Now;
需要注意的是:方法中的區域性變數不是從堆而是從棧上分配,所以C#不會做清零工作。如果使用了未賦值的區域性變數,編譯期間即會報警。不要因為有這個印象而對所有類的成員變數也做賦值動作,兩者的機理完全不同!
2、 ValueType 和 ReferenceType
(1)、 以引用方式傳遞值型別引數
值型別從呼叫棧分配,引用型別從託管堆分配。當值型別用作方法引數時,預設會進行引數值複製,這抵消了值型別分配效率上的優勢。作為一項基本技巧,以引用方式傳遞值型別引數可以提高效能。
private void UseDateByRef(ref DateTime dt){ }
public void foo()
{
DateTime now = DateTime.Now;
UseDateByRef(ref now);
}
(2)、 為 ValueType 提供 Equals 方法
.net 預設實現的 ValueType.Equals 方法使用了反射技術,依靠反射來獲得所有成員變數值做比較,這個效率極低。如果我們編寫的值物件其 Equals 方法要被用到(例如將值物件放到 HashTable 中),那麼就應該過載 Equals 方法。
public struct Rectangle
{
public double Length;
public double Breadth;
public override bool Equals ( object ob)
{
if (ob is Rectangle)
return Equels ((Rectangle)ob))
else
return false ;
}
private bool Equals (Rectangle rect)
{
return this .Length == rect.Length && this .Breadth == rect.Breach;
}
}
(3)、避免裝箱和拆箱
C#可以在值型別和引用型別之間自動轉換,方法是裝箱和拆箱。裝箱需要從堆上分配物件並拷貝值,有一定效能消耗。如果這一過程發生在迴圈中或是作為底層方法被頻繁呼叫,則應該警惕累計的效應。
一種經常的情形出現在使用集合型別時。例如:
ArrayList al = new ArrayList();
for ( int i = 0 ; i < 1000 ; i ++ )
{
al.Add(i); // Implicitly boxed because Add() takes an object
}
int f = ( int )al[ 0 ]; // The element is unboxed
解決這個問題的方法是使用.net2.0支援的泛型集合型別。
效能優化之異常處理
異常也是現代語言的典型特徵。與傳統檢查錯誤碼的方式相比,異常是強制性的(不依賴於是否忘記了編寫檢查錯誤碼的程式碼)、強型別的、並帶有豐富的異常資訊(例如呼叫棧)。
1、不要吃掉異常
關於異常處理的最重要原則就是:不要吃掉異常。這個問題與效能無關,但對於編寫健壯和易於排錯的程式非常重要。這個原則換一種說法,就是不要捕獲那些你不能處理的異常。例如:
private void OnItemStatusSave_Extend(Object sender, UIActionEventArgs e)
{
try
{
this.CommonAction.save(this.VurrentModel.ItemMaster_Status.ContainerModel);
}
catch(Exception)
{
} }
吃掉異常是極不好的習慣,因為你消除了解決問題的線索。一旦出現錯誤,定位問題將非常困難。除了這種完全吃掉異常的方式外,只將異常資訊寫入日誌檔案但並不做更多處理的做法也同樣不妥。
PageDate pageDefine = null;
CSPage page = null;
try
{
pageDefineBp.PageURI = key.ToString();
pageDefine = pageDefineBp.Do();
page = new CSPage();
page.Id =pageDefine.ID.ToString();
page.Name=pageDefine.Name;
page.Title = pageDefine.Title;
page.Orientation = pageDefine.Orientation;
}
catch(Exception ex)
{
logger.Error("PageLoaderProxy ErrorL"+ ex.StackTrace);
}
if(pageDefine.PartRelation != null)
{
foreach(PartRelationData pRelation in pageDefine.PartRelation);
}
如上例,一旦呼叫方法是不,PageDefine 為 null,隨後訪問pageDefine.PartRelation將丟擲NullReferenceException錯誤,這與原始的異常完全不一樣。例如,原始的異常資訊可能指示資料庫配置字串有錯,簡單更改後就OK了。而象現在這樣,如果沒有原始碼,定位問題將很困難。
2、不要吃掉異常資訊
有些程式碼雖然丟擲了異常,但卻把異常資訊吃掉了。例如嚇例,後臺呼叫異常的原因可能是因為編碼輸入重複,未能通過資料庫唯一性約束。但展現的異常資訊卻是一句毫無意義的廢話,原始的異常資訊被吃掉了。本來只需要使用者把編碼修改一下,重新提交就OK了,但現在不得不依靠程式設計師來協助排錯。
為異常披露詳盡的資訊是程式設計師的職責所在。如果不能在保留原始異常資訊含義的前提下附加更豐富和更人性化的內容,那麼讓原始的異常資訊直接展示也要強得多。千萬不要吃掉異常。
3、 避免不必要的丟擲異常
丟擲異常和捕獲異常屬於消耗比較大的操作,在可能的情況下,應通過完善程式邏輯避免丟擲不必要不必要的異常。例如:
private IComplexType GetComplexType(Key key)
{
if(key == null) return null;
if(key.Equals(Key.Empty)) return null;
try
{
if(parentEntity != null)
type = (IComplexType)this.parentEntity.Namespace.Component.FIndTypeBykey(key);
}
catch(Exception ex)
{
//logger.Error("association({0}) load type from designtime error{1}",this.ToString())
}
}
如果this.parentEntity.Namespace等於null ,此方法執行期間會丟擲許多NullReferenceException,應通過增加對Namespace是否為null的檢查,避免丟擲異常。
與此相關的一個傾向是利用異常來控制處理邏輯。儘管對於極少數的情況,這可能獲得更為優雅的解決方案,但通常而言應該避免。
4、 避免不必要的重新丟擲異常
如果是為了包裝異常的目的(即加入更多資訊後包裝成新異常),那麼是合理的。但是有不少程式碼,捕獲異常沒有做任何處理就再次丟擲,這將無謂地增加一次捕獲異常和丟擲異常的消耗,對效能有傷害。例如:
private void OnDeleteCommon(IUIView mView)
{
try
{
if(this.MainView.Fields["IsSelectList"] != null)
{
//遍歷所有checkbox==true的record
……
}
else
{
……
}
//最後置狀態
this.CurrentPart.PageStatus = UFSoft.UBF.UI.IView.PartStateType.Unchanged;
}
catch(Exception ex)
{
throw;
}
}
將這個原則與“不要吃掉異常”比較起來,不要吃掉異常更為重要!例如下例:
try
{
user = Provider.GetUser(username, isOnline, lastAction);
}
catch(Exception ex)
{
//Fixed;讀取使用者資訊資料庫異常處理;
}
程式設計師一句清楚應該在以後補上異常處理動作,但由於吃掉了異常,會給排錯代理極大困難,此時增加一個throw語句要比吃掉異常強的多!
5、使用throw而不是throw e丟擲原來的異常
如果在捕獲異常之後,不必包裝成新的異常,而只是繼承丟擲原來的異常,通常可以看到兩種寫法。
方式1:使用布袋引數的throw語句。示例如下:
try
{
int val = objMember.getMember();
}
catch(Exception ex)
{
throw;
}
方式2:使用帶物件例項的throw語句,示例如下:
try
{
int val = objMember.getMember();
}
catch(Exception ex)
{
throw e;
}
方式2表面上看跟方式一沒有什麼不同,其實有很微妙的差異:throw e 表示在當前位置重新丟擲異常,並不是轉發原來的異常。它會更改異常的內部資訊,最主要的是StackTrace會發生變化,引發異常的程式碼位置將變為throw e程式碼所在的位置而非最初引發異常的程式碼位置!這應該不是希望看到的結果吧,如果檢視IL程式碼會發現一個是rethrow指令,另一個則是throw指令,完全不同。
另外,方式2在效能上也有較大損失,因為異常最主要的消耗不是在new Exception的時候,而是在throw Exception的時候,因為throw語句才會更改包括StackTrace在內的許多異常內部資訊。對於複雜的應用,如果異常時的呼叫鏈很深,構造StockTrace的消耗之大遠遠超乎想象,我們在研究異常消耗時可能會寫一個簡單的控制檯程式,模擬丟擲異常,捕獲異常來研究異常消耗,在這種場景下得到的印象是.net的異常效能還可以,但在真實的運用中你會看到這個消耗能上升2到3個數量級!
因此,綜合考慮這兩方面的因素,我們最好按照throw而不是throw e的方式丟擲原來的異常