
10 行程式碼解決漏斗轉換計算之效能優化
大話資料計算效能優化
大資料分析的效能優化,說道底,就優化一個事情:針對確定的一個計算任務(資料確定,結果確定),以最經濟的方案得到結果。
這個最經濟的方案主要考量三個成本:時間成本、硬體成本、軟體成本。
時間成本:根據計算任務的特點,能容忍的最長時間各不相同。那些 T+0 的計算任務,實時性要求就比較高,T+1 再算出結果就失去了意義。
硬體成本:可以使用的硬體資源,對一個公司來說一般不是經常變化的,機器配置、可叢集數量就那麼多。即便使用雲端計算產品,也只是多了擴容的靈活性,成本是少不掉的。
軟體成本:編寫出這個計算演算法的人工費 + 軟體環境的成本。這個成本也與前兩項相關,程式控制力度粗獷一些,實現邏輯簡單一些,程式就容易編寫,那軟體成本就會低一些,帶來的副作用是執行時間超長或者需要昂貴的硬體。
這三個因素裡面,一般對於計算任務來說,自然是越快越好,當然只要不慢過能容忍的時長,也就還算是有意義的計算;而硬體因素的彈性就比較小,有多少資源是相對固定的;所以,剩下的可以大做文章的就是軟體成本了。軟體成本里,程式設計師的工資是很重要的一項,而有沒有順手的軟體環境讓程式設計師能高效的把計算描述出來,就成了關鍵。最典型的例子就是理論上用匯程式設計序能寫出所有的程式,但它明顯不如 SQL 或 JAVA 做個常規計算來的容易。
說到 SQL 和 JAVA,成規模的計算中心的一些維護者估計也會皺眉,使用它們的時間越長,越能體會需求變動或優化演算法過程中的痛苦,明明演算法過程自己想的很清楚了,但編寫成可執行的程式就困難重重。這些困難主要來自兩個方面:
首先,一些基礎的資料操作方法是自己逐漸積累的,沒有經過整體的優化設計,這些個人工具對個人的開發效率有不錯的提升,但沒法通用,也不全面,這個困難主要表現在用 JAVA 等高階語言實現的一些 UDF 上。
第二,主要是思維方式上的,在生產場景下用習慣了 SQL 查詢,在計算場景下遇到的效能問題自然而然就想通過優化 SQL 語句的方式把問題緩解掉。但實際上這可能是個溫水煮青蛙的過程。越深入搞,把簡單的過程問題越可能搞成龐大不可拆分的邏輯塊,到最後只有原創作者或高手才敢碰它。我這個老程式設計師,十多年前剛入行的時候,八卦中耳聞過 ORACLE 的系統管理員,尤其是有效能優化能力的,比普通程式設計師貴多了,可見這個難題在資料規模相對較小的十年前已經凸顯了。
(注:生產場景和計算場景在初始階段的軟體系統裡一般很難截然分開,資料都是從生產場景積累起來的,等積累多了,慢慢會增加計算需求,逐漸獨立出計算中心和資料倉庫。這個量變引起質變的過程,如果不在思維上轉變,不引入新辦法,那就將成為被煮的青蛙。)
為了節省讀者的時間,我們先把效能優化的常用手段總結一下,方便有需求的使用者逐條對比進行實際操作。
1、 只加載計算相關資料。
列存方式儲存資料;
常用的欄位和不常用的分開儲存;
用獨立的維表儲存維的屬性,減少事實表的資訊冗餘;
按照某些常用作查詢條件的欄位分開儲存,如按年份、性別、地區等獨立儲存;
2、 精簡計算涉及到的資料
用來分析時,一些冗長的編號,可以序號化處理,用 1、2、……替代 TJ001235-078、 TJ001235-079、……,這樣即能加快載入資料的速度,又能加快計算速度。
日期時間,如果用字串型別按照我們熟悉的格式 (2011-03-08) 儲存,那載入和計算都會慢。前面這個日期可以儲存成 110308 這樣的數值型別,也可以儲存成相對於一個開始時間的毫秒數(如相對於最早的資料 2010-01-01 的毫秒數)。
3、 演算法的優化
計算量小的條件寫在前面,如 boolean 型別的判斷,要早於字串查詢,這樣用較少的計算就能排除掉不符合要求的資料;
減少對大事實表的遍歷次數。具體方法有:在一次遍歷過程中,同時給多個獨立的運算操作提供資料(後面會提到的集算器裡的管道概念),而不是每個運算操作遍歷一次資料;做 JOIN 時,在記憶體裡的維表裡檢索事實表資料,而不是用每條維表資料去遍歷一次事實表。
查詢時借用 HASH 索引、二分法、序號直接對位等方式加快速度。
4、 平行計算
載入資料和計算兩個步驟都可以並行。考量計算特點,根據載入資料和運算哪個量更大來判斷瓶頸是計算機的磁碟還是 CPU,磁碟陣列適合並行載入資料,多核 CPU 適合並行運算。
多機叢集的並行任務,要考慮主程式和子程式的通訊問題,儘量把複雜計算獨立到節點機上完成,網路傳輸較慢,要減少節點機之間的資料交換。
實操效果
兵馬未動糧草先行,有了上面這些指導思想,我們下面就切入正題實現漏斗計算的優化,看一下實際的優化效果。
1、未做任何優化,直接開工
資料:
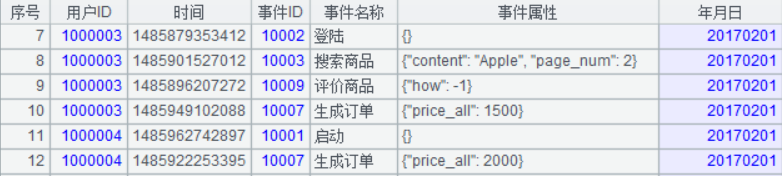
程式:(附件中的 1-First.dfx,也附帶了測試資料檔案,可在集算器裡直接執行)
漏斗轉換計算核心程式碼的邏輯細節在上一篇中詳細介紹過,這裡就不再贅述。
結果:(注:之後的測試都以 118 萬條資料為基礎,成倍增加)
118 萬條記錄 /70MB/ 使用者數量 8000/31 秒;
590 萬條記錄 /350MB/ 使用者數量 4 萬 /787 秒。
分析:
資料量增加到 5 倍,但耗時增加到了 26 倍,效能下降得厲害,而且不是線性的。原因是被分析的使用者列表擴大了 5 倍,同時被分析的記錄數也擴大 5 倍,那檢索使用者次數理論上就擴大了 5*5 倍。接下來採用以下優化方式↓
2、按使用者 ID 順序插入使用者列表,用二分法查詢使用者。
程式:(2-BinarySearch.dfx)
B12 給 find 增加 @b 選項,指明用二分法查詢;D13 中卻去掉 insert 的第一個位置引數 0 後,新使用者就不直接追加到最後了,而是按主鍵順序插入。
A |
B |
C |
D |
|
11 |
…… |
|||
12 |
for A11 |
>[email protected](A12.使用者 ID) |
||
13 |
if user==null |
if A12.事件 ID==events(1) |
>A10.insert(,A12.使用者 ID: 使用者 ID,1:maxLen,[[A12. 時間,1]]:seqs) |
|
14 |
…… |
結果:
118 萬條記錄 /70MB/ 使用者數量 8000/10 秒;
590 萬條記錄 /350MB/ 使用者數量 4 萬 /47 秒。
分析:
優化後,1 倍的資料量耗時縮減到 1/3;5 倍的資料量提速比較明顯,縮減到 1/16。進一步觀察,5 倍資料量是 350MB,從硬碟載入資料的速度慢點算也會有 100M/ 秒,假如 CPU 夠快的話,極限速度應該能到 4 秒左右,而現在的 47 秒證明 CPU 耗時還比較嚴重,根據經驗可以繼續優化↓
3、批量讀入遊標資料
程式:(3-BatchReadFromCursor.dfx)
12~17 行整體剪下後,向右移一個格子之後,在 A12 增加一個批量載入遊標資料的迴圈,表示 A11 中的遊標每次取 10000 條,B12 再對取出來的這 10000 條資料迴圈處理。
A |
B |
C |
|
11 |
…… |
||
12 |
for A11,10000 |
for A12 |
…… |
13 |
…… |
結果:
118 萬條記錄 /70MB/ 使用者數量 8000/4 秒;
590 萬條記錄 /350MB/ 使用者數量 4 萬 /10 秒;
5900 萬條記錄 /3.5GB/ 使用者數量 40 萬 /132 秒;
11800 萬條記錄 /7GB/ 使用者數量 80 萬 /327 秒。
分析:
優化後,1 倍資料量耗時縮減到 2/5;5 倍的資料量縮減到 1/5;新測試的 50 倍、100 倍效能也大體隨資料量保持了線性。注意到原始資料有一些欄位用不到,用到的欄位也可以通過序號化等手段再簡化,簡化後的檔案會小几倍,從而達到從硬碟減少讀取時間的目的,具體優化方式如下↓
4、精簡資料
思路:
先觀察一下原始資料:使用者 ID 用從 1 開始的序號替代,除了減少少許儲存空間外,還可以在後續計算時通過序號快速定位到使用者,減少查詢時間。時間和年月日欄位資訊重複,去掉年月日,長整型的時間欄位也可以進一步精簡成相對 2017-01-01 這個開始時間的毫秒數;事前我們知道只有 10 種事件,那事件 ID 和事件名稱可以單獨提取出個維表記錄,這個事實表裡只儲存序號化的事件 ID(1、2、3…10)就夠了;事件屬性是 JSON 格式,種類不多,那對於某一種事件,可以用序列儲存事件屬性的值,在序列中的位置表示某種屬性,這樣即縮減儲存空間,又能提升查詢屬性的效率。
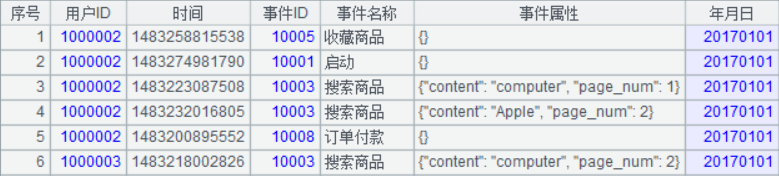
除了上面這些欄位值的精簡,我們儲存資料的格式棄用文字方式,改變成集算器二進位制格式,儲存空間更小,載入速度更快,精簡後的事實表如下:

實現:
精簡事實表資料之前,要先通過事實表生成使用者表、事件表兩個維表的(genDims.dfx,執行後生成 user.bin 和 event.bin):
A |
|
1 |
>beginTime=now() |
2 |
>fPath="e:/ldsj/demo/" |
3 |
=file(fPath+"src-11800.txt")[email protected]() |
4 |
=channel(A3) |
5 |
=A4.groups(#1:使用者 id) |
6 |
=A3.groups(#3:事件 ID,#4: 事件名稱; iterate(~~&#[email protected]().fname()): 屬性名稱) |
7 |
=file(fPath+"event.bin")[email protected](A6) |
8 |
=file(fPath+"user.bin")[email protected](A4.result()) |
9 |
[email protected](beginTime,now()) |
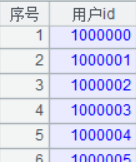
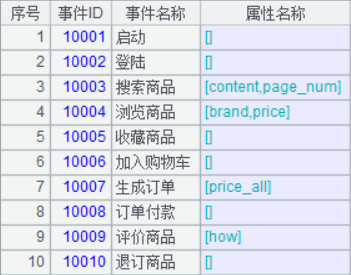
提取維表的這段程式,仍然有優化的手段體現。提取兩個維表,常規思維是每遍歷一遍資料,生成一個維表;從硬碟讀入大量資料進行遍歷,讀入慢,但讀入後的計算量卻非常小。針對這種情況,那有什麼手段可以在讀入資料時,同時用於多種獨立的計算呢,答案就是“管道”,多定義了幾個管道,就多定義了幾種運算。A4 針對 A3 遊標定義管道,A5 定義 A4 管道的分組計算,A6 定義另外一個分組計算,A7 匯出 A6 的結果,A8 匯出 A4 管道的結果。最終得到的兩個維表如下:
基於上面兩個維表對事實表進行精簡(toSeq.dfx),6.8G 的文字檔案精簡後,得到 1.9G 的二進位制檔案,縮小了 3.5 倍。
A |
B |
C |
D |
|
1 |
>beginTime=now() |
|||
2 |
>fPath="e:/ldsj/demo/" |
|||
3 |
=file(fPath+"src-11800.txt")[email protected]() |
|||
4 |
=file(fPath+"event.bin")[email protected]() |
=A4.(事件 ID) |
=A4.(屬性名稱 ) |
|
5 |
=file(fPath+"user.bin")[email protected]() |
=A5.(使用者 ID) |
||
6 |
||||
7 |
func |
|||
8 |
||||
9 |
=[] |
|||
10 |
for B7 |
|||
11 |
>B9.insert(0,eval("B8."+B10)) |
|||
12 |
return B9 |
|||
13 |
||||
14 |
for A3,10000 |
|||
15 |
=A14.new([email protected](使用者 ID): 使用者 ID,[email protected]( 事件 ID): 事件 ID, 時間: 時間,func(A7, 事件屬性,D4([email protected]( 事件 ID))): 事件屬性 ) |
|||
16 |
=file(fPath+"src-11800.bin")[email protected](B15) |
|||
17 |
[email protected](beginTime,now()) |
這段程式碼出現了一個新的知識點,第 7~12 行定義了一個函式來處理 json 格式的事件屬性,B15 裡精簡每一行資料時,呼叫了這個函式。B16 把每次精簡好的一萬條記錄追寫入同一個二進位制檔案。
程式:(4-Reduced.dfx)
在上一次程式的基礎上改造了這麼幾個格子:
A3/A4 中的時間相對於 2017-01-01;
A6 事件序列改用序號;
A7 中屬性過濾,用精確匹配值的方式替換以前低效的模糊匹配字串方式; A10 初始化使用者序列,長度為使用者數,該序列中的位置代表使用者的序號;
C12 用序號方式查詢使用者;
E13 用序號方式儲存新使用者:
A |
B |
C |
D |
E |
|
2 |
…… |
||||
3 |
>[email protected](date(2017,1,1),date(2017,1,1)) |
||||
4 |
>[email protected](date(2017,1,1),date(2017,3,1)) |
||||
5 |
>dateWindow=10*24*60*60*1000 |
||||
6 |
>events=[3,4,6,7] |
||||
7 |
>filter="if(事件 ID!=4||(事件屬性.len()>0&& 事件屬性 (1)==\"Apple\");true)" |
||||
8 |
|||||
9 |
/開始執行漏斗轉換計算程式 |
||||
10 |
=to(802060).(null) |
||||
11 |
=file(dataFile)[email protected]().select(時間 >=begin&& 時間 <end && events.pos(事件 ID)>0 && ${filter}) |
||||
12 |
for A11,10000 |
for A12 |
>user=A10(B12.使用者 ID) |
||
13 |
if user==null |
if B12.事件 ID==events(1) |
>A10(B12.使用者 ID)=[B12. 使用者 ID,1,[[B12. 時間,1]]] |
||
14 |
…… |
結果:
11800 萬條記錄 /1.93GB/ 使用者數量 80 萬 /225 秒。
分析:
優化後,100 倍資料量耗時縮減到上一步的 2/3。除了精簡涉及的查詢欄位,我們再看看另一種能有效縮減查詢資料量的方法↓
5、把資料預先拆分儲存,計算的時候只加載涉及到的資料
思路:
如何拆分資料和查詢特點有關,這個例子中經常查詢不定時間段,那按照日期拆分比較合適,按照事件 ID 拆分就沒有意義了。
拆分資料的程式(splitData.dfx):
A4 每次取出 10 萬條資料;B4 迴圈 60 天;C6 按照日期查詢到資料後,通過 C9 追加到各自日期的檔案裡。
A |
B |
C |
D |
|
1 |
=dataFile=file("e:/ldsj/demo/src-11800.bin")[email protected]() |
|||
2 |
>destFolder="e:/ldsj/demo/dates/" |
|||
3 |
>oneDay=24*60*60*1000 |
|||
4 |
for A1,100000 |
for 60 |
>begin=long(B4-1)*oneDay |
|
5 |
>end=long((B4))*oneDay |
|||
6 |
=A4.select(時間 >=begin && 時間 <end) |
|||
7 |
if (C6 == null) |
next |
||
8 |
>filename= string(date(long(date(2017,1,1))+begin), "yyyyMMdd")+".bin" |
|||
9 |
=file(destFolder+fileName)[email protected](C6) |
執行後生成 59 天的資料檔案:
程式:(5-SplitData.dfx)
A2 中把以前被分析的檔案定義換成目錄;
A3/A4 的起止日期條件有所變動,以前是查詢日期欄位,現在變成查詢日期檔案;
A11 把目錄下的日期檔案排序,選出要分析的多個日期檔案,然後組合成一個遊標之後再進行事件過濾就可以了。
A |
|
1 |
…… |
2 |
>fPath="e:/ldsj/demo/dates/" |
3 |
>begin="20170201.bin" |
4 |
>end="20170205.bin" |
5 |
…… |
11 |
=directory(fPath+"2017*").sort().select(~>=begin&&~<=end).(file(fPath+~:"UTF-8")).([email protected]()).conjx().select(events.pos(事件 ID)>0 && ${filter}) |
12 |
…… |
結果:
目標資料選擇 2017-02-01 至 2017-02-05 這 5 天,全量掃描資料 168 秒;只掃描 5 個檔案得到相同結果 7 秒,效果顯著。到目前為止,讀取資料和計算都是單執行緒的,下面我們再試試平行計算↓
6、平行計算
單執行緒載入資料,多執行緒計算
程式:(6-mulit-calc.dfx)
增加 B 列,B2 中啟動 4 個執行緒處理 A12 里加載的 100000 條資料,C12 中依據使用者 ID%4 的餘數分成 4 組,分別給 4 個執行緒進行運算。
A |
B |
C |
|
11 |
…… |
||
12 |
for A11,100000 |
fork to(4) |
for A12.select(使用者 ID%4==B12-1) |
13 |
…… |
結果:
11800 萬條 /1.93GB/ 使用者數 80 萬 /4 執行緒 / 一次性讀入 10 萬條資料 /262 秒;
11800 萬條 /1.93GB/ 使用者數 80 萬 /4 執行緒 / 一次性讀入 40 萬條資料 /161 秒;
11800 萬條 /1.93GB/ 使用者數 80 萬 /4 執行緒 / 一次性讀入 80 萬條資料 /233 秒;
11800 萬條 /1.93GB/ 使用者數 80 萬 /4 執行緒 / 一次性讀入 400 萬條資料 /256 秒。
分析:
筆者測試機器是單個機械硬碟,載入資料速度是瓶頸,所以對提速不太明顯。但調整單次載入的資料量,還是會有明顯的效能差異。每次處理 40 萬條資料時效能最優。
多執行緒載入資料
預處理:(splitDataByUserId.dfx)
雖然 4 個執行緒可以同時讀全量資料的同一個檔案,但每個執行緒讀出 3/4 的無用資料必然拖慢速度,所以預先按照使用者 ID%4 拆分一下檔案能更快些。C3 查詢出 ID%4 的資料,C6 把查詢的資料存入相應的拆分檔案。
A |
B |
C |
D |
|
1 |
=file("e:/ldsj/demo/src-11800.bin")[email protected]() |
|||
2 |
e:/ldsj/demo/users/ |
|||
3 |
for A1,100000 |
for to(4) |
=A3.select(使用者 ID%4==B3-1) |
|
4 |
if (C3 == null) |
next |
||
5 |
="src-11800-"+string(B3)+".bin" |
|||
6 |
=file(A2+C5)[email protected](C3) |
程式:(6-mulit-read.dfx)
把多執行緒程式碼前移到 A11,每個執行緒內讀取各自的檔案進行計算 (B11)。
A |
B |
C |
|
9 |
…… |
||
10 |
=to(802060).(null) |
||
11 |
fork to(4) |
=file(fPath+"src-11800-"+string(A11)+".bin")[email protected]().select(時間 >=begin&& 時間 <end && events.pos(事件 ID)>0 && ${filter}) |
|
12 |
for B11,10000 |
…… |
|
13 |
…… |
結果:
11800 萬條記錄 /1.93GB/ 使用者數量 80 萬 /4 執行緒 /113 秒。
分析:
同樣受限於載入資料速度,提速也有限。如果用多臺機器叢集,每臺機器處理 1/4 的資料,因為是多個硬碟並行,速度肯定會有大幅提升,下面我們就看一下如何實現多機並行↓
多機叢集平行計算
集算器如何部署叢集計算,如何寫叢集的主、子程式的知識點不是本文重點關注的,可以移步相關的文件詳細瞭解:http://doc.raqsoft.com.cn/esproc/tutorial/jqjs.html。
主程式:(6-multi-pc-main.dfx)
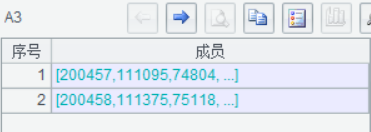
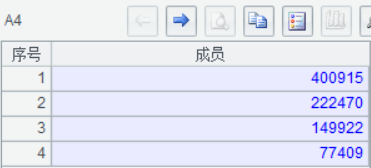
A3 中用 callx 呼叫子程式 6-multi-pc-sub.dfx,引數序列 [1,2,3…] 傳入每個子程式控制處理哪一部分資料;返回的結果再通過 B6 彙總到一起,結果存放在 A4 格子裡。
A |
B |
|
1 |
>beginTime=now() |
|
2 |
[127.0.0.1:8281,127.0.0.1:8282] |
|
3 |
=callx("e:/ldsj/demo/6-multi-pc-sub.dfx",to(2),"e:/ldsj/demo/users/";A2) |
|
4 |
||
5 |
for A3 |
|
6 |
>A4=if(A4==null,A5,A4++A5) |
|
7 |
[email protected](beginTime,now()) |
A3 得到結果序列:
A4 彙總出最終結果:
節點機子程式:(6-multi-pc-sub.dfx)
相比較上一步單機多執行緒載入資料的程式,去掉 A11 的多執行緒 fork to(4);節點機計算哪個拆分檔案是通過 taskSeq 引數由主程式傳過來的(B11);A22 把 A20 裡的結果返回給主程式。
A |
B |
C |
|
9 |
…… |
||
10 |
=to(802060).(null) |
||
11 |
=file(fPath+"src-11800-"+string(taskSeq)+".bin")[email protected]().select(時間 >=begin&& 時間 <end && events.pos(事件 ID)>0 && ${filter}) |
||
12 |
for B11,10000 |
…… |
|
13 |
…… |
||
22 |
return A20 |
結果:
11800 萬條記錄 /1.93GB/ 使用者數量 80 萬 / 單節點機處理四分之一資料 /38 秒。主程式彙總的時間很短忽略不計,也就是 4 個 PC 的四塊硬碟並行載入資料時,能把速度提升到 38 秒。
程式和測試資料在百度網盤下載 。安裝好集算器,修改下程式裡的檔案路徑,就可以執行看效果了。
結束語 - 前瞻
看到上面這麼多的優化細節,估計有人質疑,這麼費力的把這事做到極致,是不是吹毛求疵了?資料庫應該是內建了一些自動的優化演算法,目前已有共識的是尤其 ORACLE 在這方面已經做的很細緻,這些細節根本不需要使用者操心。確實,自動效能優化的重要意義是肯定的,但近幾年隨著資料環境的複雜化,資料量的劇增,更精細的控制資料的能力也就有了越來越多的應用場景,雖然會增加學習成本,但也會帶來更高的資料收益。而且這個學習成本除了解決效能問題外,還能更好地解決根本上的描述複雜計算、整理資料方面的業務需求,更何況這類問題是無法自動化的,因為是“決策要做什麼”變複雜了,因此只能提供更方便的程式語言提高描述效率,正視問題。計算機再智慧,也不能替代人類做決策。自動和手動兩種方式不是對立,而是互補的關係!
上面這些優化的思路是我們程式設計師能預先想到的,同時也大概能根據計算任務特點選擇效果顯著的優化方式。但我要說的是計算機系統太複雜了:特點迥異的計算需求、不穩定的硬碟讀寫速度、不穩定的網路速度、無法估量的 CPU 具體計算量!所以實際業務中我們還需要依靠經驗根據實際優化的效果來選擇優化方法。
SPL 出現以前,因為優化方式的實現和維護都比較困難,因此試驗動作就難以密集進行,優化成果不多也就是自然的了;同時因為缺乏密集“倒騰”資料的鍛鍊,優化經驗的積累也不容易,這也從另一個角度驗證了高階資料分析師人才昂貴的現狀。使用高效工具的第一批人,永遠是獲益最大的那一群人,第一批用弓箭的,第一批用槍的,第一批用坦克的,第一個用×××的……而你就是第一批用 SPL 的程式設計師。程式設計師的龐大隊伍裡分化出一支專業搞資料處理、分析的資料程式設計師,形成一個有獨立技能的職業,這是必然的趨勢。您的職業規劃,方向選擇也要儘早有個打算,才有佔領某一高地的可能。
最後還要說一句,目前這個結果仍然還有優化餘地。如果再將資料壓縮儲存,還可以進一步減少硬碟訪問時間,而資料經過一定的排序並採用列式儲存後確實還可以再壓縮。另外,這裡的叢集運算拆分成了 4 個子任務,而即使配置相同的機器,也可能運算效能不同,這時候就會發生運算快的要等運算慢的,最終完成時間是以計算最慢的那臺機器為準,如果我們能把任務拆得更細一些,就可以做到更平均的效率,從而進一步提高計算速度。這些內容,我們將在後面的文章繼續講述。