
LRN 區域性響應歸一化詳解
1、其中LRN就是區域性響應歸一化:
這個技術主要是深度學習訓練時的一種提高準確度的技術方法。其中caffe、tensorflow等裡面是很常見的方法,其跟啟用函式是有區別的,LRN一般是在啟用、池化後進行的一中處理方法。
AlexNet將LeNet的思想發揚光大,把CNN的基本原理應用到了很深很寬的網路中。AlexNet主要使用到的新技術點如下。
(1)成功使用ReLU作為CNN的啟用函式,並驗證其效果在較深的網路超過了Sigmoid,成功解決了Sigmoid在網路較深時的梯度彌散問題。雖然ReLU啟用函式在很久之前就被提出了,但是直到AlexNet的出現才將其發揚光大。
(2)訓練時使用Dropout隨機忽略一部分神經元,以避免模型過擬合。Dropout雖有單獨的論文論述,但是AlexNet將其實用化,通過實踐證實了它的效果。在AlexNet中主要是最後幾個全連線層使用了Dropout。
(3)在CNN中使用重疊的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。並且AlexNet中提出讓步長比池化核的尺寸小,這樣池化層的輸出之間會有重疊和覆蓋,提升了特徵的豐富性。
(4)提出了LRN層,對區域性神經元的活動建立競爭機制,使得其中響應比較大的值變得相對更大,並抑制其他反饋較小的神經元,增強了模型的泛化能力
其中LRN的詳細介紹如下: (連結地址:tensorflow下的區域性響應歸一化函式tf.nn.lrn)
實驗環境:windows 7,anaconda 3(Python 3.5),tensorflow(gpu/cpu)
函式:tf.nn.lrn(input,depth_radius=None,bias=None,alpha=None,beta=None,name=None)
函式解釋援引自tensorflow官方文件
https://www.tensorflow.org/api_docs/python/tf/nn/local_response_normalization
The 4-D input tensor is treated as a 3-D array of 1-D vectors (along the last dimension), and each vector is normalized independently. Within a given vector, each component is divided by the weighted, squared sum of inputs within depth_radius. In detail,
sqr_sum[a, b, c, d] =
sum(input[a, b, c, d - depth_radius : d + depth_radius + 1] ** 2)
output = input / (bias + alpha * sqr_sum) ** beta
背景知識:
tensorflow官方文件中的tf.nn.lrn函式給出了局部響應歸一化的論文出處
詳見http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
為什麼要有區域性響應歸一化(Local Response Normalization)?
詳見http://blog.csdn.net/hduxiejun/article/details/70570086
區域性響應歸一化原理是仿造生物學上活躍的神經元對相鄰神經元的抑制現象(側抑制),然後根據論文有公式如下
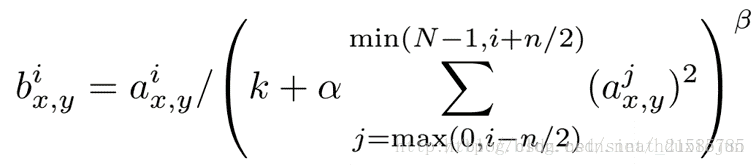
公式解釋:
因為這個公式是出自CNN論文的,所以在解釋這個公式之前讀者應該瞭解什麼是CNN,可以參見
http://blog.csdn.net/whiteinblue/article/details/25281459
http://blog.csdn.net/stdcoutzyx/article/details/41596663
http://www.jeyzhang.com/cnn-learning-notes-1.html
這個公式中的a表示卷積層(包括卷積操作和池化操作)後的輸出結果,這個輸出結果的結構是一個四維陣列[batch,height,width,cha
nnel],這裡可以簡單解釋一下,batch就是
批次數(每一批為一張圖片),height就是圖片高度,width就是圖片寬度,channel就是通道數可以理解成一批圖片中的某一個圖片經
過卷積操作後輸出的神經元個數(或是理解
成處理後的圖片深度)。ai(x,y)表示在這個輸出結構中的一個位置[a,b,c,d],可以理解成在某一張圖中的某一個通道下的某個高度和某
個寬度位置的點,即第a張圖的第d個通道下
的高度為b寬度為c的點。論文公式中的N表示通道數(channel)。a,n/2,k,α,β分別表示函式中的input,depth_radius,bias,alpha,beta,其
中n/2,k,α,β都是自定義的,特別注意一下∑疊加的方向是沿著通道方向的,即每個點值的平方和是沿著a中的第3維channel方向
的,也就是一個點同方向的前面n/2個通
道(最小為第0個通道)和後n/2個通道(最大為第d-1個通道)的點的平方和(共n+1個點)。而函式的英文註解中也說明了把input當
成是d個3維的矩陣,說白了就是把input的通道
數當作3維矩陣的個數,疊加的方向也是在
通道方向。
畫個簡單的示意圖: 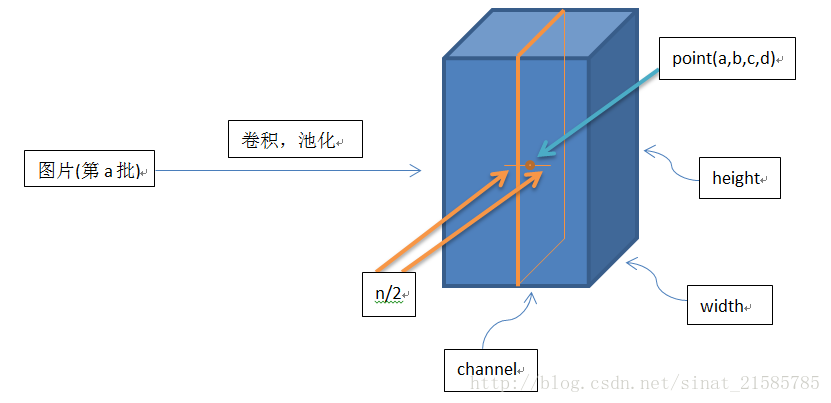
實驗程式碼:
import tensorflow as tf
import numpy as np
x = np.array([i for i in range(1,33)]).reshape([2,2,2,4])
y = tf.nn.lrn(input=x,depth_radius=2,bias=0,alpha=1,beta=1)
with tf.Session() as sess:
print(x)
print('#############')
print(y.eval())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

結果解釋:
這裡要注意一下,如果把這個矩陣變成圖片的格式是這樣的 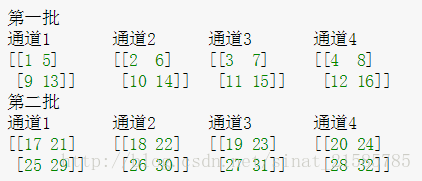
然後按照上面的敘述我們可以舉個例子比如26對應的輸出結果0.00923952計算如下
26/(0+1*(25^2+26^2+27^2+28^2))^1