
python之爬蟲的入門06------scrapy框架
1、安裝scrapy框架:
pip install scrapy
2、scrapy原理圖:
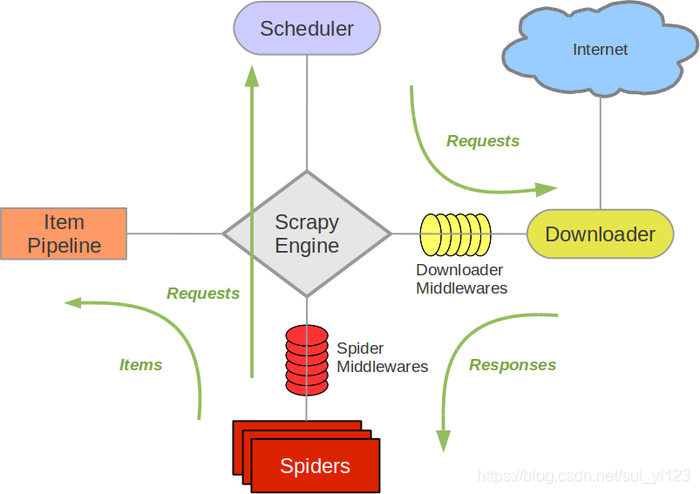
3、介紹:
Scrapy Engine引擎
引擎負責控制資料流在系統中所有元件中流動,並在相應動作發生時觸發事件。
排程器(Scheduler)
排程器從引擎接受request並將他們入隊,以便之後引擎請求他們時提供給引擎。
下載器(Downloader)
下載器負責獲取頁面資料並提供給引擎,而後提供給spider。
Spiders(爬蟲)
Spider是Scrapy使用者編寫用於分析response並提取item(即獲取到的item)或額外跟進的URL的類。 每個spider負責處理一個特定(或一些)網站。
Item Pipeline
Item Pipeline負責處理被spider提取出來的item。典型的處理有清理、 驗證及持久化(例如存取到資料庫中)。
下載器中介軟體(Downloader middlewares)
下載器中介軟體是在引擎及下載器之間的特定鉤子(specific hook),處理Downloader傳遞給引擎的response(也包括引擎傳遞給下載器的Request)。 其提供了一個簡便的機制,通過插入自定義程式碼來擴充套件Scrapy功能。
一句話總結就是:處理下載請求部分
Spider中介軟體(Spider middlewares)
Spider中介軟體是在引擎及Spider之間的特定鉤子(specific hook),處理spider的輸入(response)和輸出(items及requests)。 其提供了一個簡便的機制,通過插入自定義程式碼來擴充套件Scrapy功能。
一句話總結就是:處理解析部分
4、資料量過程:
1.引擎開啟一個網站(open a domain),找到處理該網站的Spider並向該spider請求第一個要爬取的URL(s)。
2.引擎從Spider中獲取到第一個要爬取的URL並在排程器(Scheduler)以Request排程。
3.引擎向排程器請求下一個要爬取的URL。
4.排程器返回下一個要爬取的URL給引擎,引擎將URL通過下載中介軟體(請求(request)方向)轉發給下載器(Downloader)。
5.一旦頁面下載完畢,下載器生成一個該頁面的Response,並將其通過下載中介軟體(返回(response)方向)傳送給引擎。
6.引擎從下載器中接收到Response並通過Spider中介軟體(輸入方向)傳送給Spider處理。
7.Spider處理Response並返回爬取到的Item及(跟進的)新的Request給引擎。
8.引擎將(Spider返回的)爬取到的Item給Item Pipeline,將(Spider返回的)Request給排程器。
9.(從第二步)重複直到排程器中沒有更多地request,引擎關閉該網站。
5、建立一個scrapy專案:
scrapy startproject mySpider
#mySpider是爬蟲專案名字
6、進入專案,建立爬蟲:
scrapy genspider xxx url
#xxx是爬蟲的名字,不能重複。url是你需要爬取的網頁的url地址
7、用pycharm開啟專案檔案,配置setting:
ROBOTSTXT_OBEY = False
USER_AGENT = ‘你的瀏覽器核心型號’
8、開啟爬蟲開始第一次爬取HTML頁面:
scrapy crawl xxx
#xxx是爬蟲名字
看到200的狀態碼:
(200) <GET https://hr.tencent.com/position.php> (referer: None)
就是爬取已經成功了!!!
class Tx01Spider(scrapy.Spider):
name = "tx01"
allowed_domains = ["https://hr.tencent.com"]
start_urls = (
'https://hr.tencent.com/position.php',
)
def parse(self, response):
print('爬取成功')
在spider的tx01.py 的 parse裡面 對取到的response進行資料提取