
資料探勘之FP_Tree演算法實現
轉自http://www.cnblogs.com/zhangchaoyang/articles/2198946.html
(格式複製之後有變化,建議直接點連結去部落格園看原文)
python程式碼見https://github.com/yantijin/Lean_DataMining
FP-Tree演算法的實現
在關聯規則挖掘領域最經典的演算法法是Apriori,其致命的缺點是需要多次掃描事務資料庫。於是人們提出了各種裁剪(prune)資料集的方法以減少I/O開支,韓嘉煒老師的FP-Tree演算法就是其中非常高效的一種。
名詞約定
舉個例子,設事務資料庫為:
A E F G A F G A B E F G E F G
每一行為一個事務,事務由若干個互不相同的專案構成,任意幾個專案的組合稱為一個模式。
上例中一共有4個事務。
模式{A,F,G}的支援數為3,支援度為3/4。支援數大於閾值minSuport的模式稱為頻繁模式(Frequent Patten)。
{F,G}的支援度數為4,支援度為4/4。
{A}的支援度數為3,支援度為3/4。
{F,G}=>{A}的置信度為:{A,F,G}的支援度數 除以 {F,G}的支援度數,即3/4
{A}=>{F,G}的置信度為:{A,F,G}的支援度數 除以 {A}的支援度數,即3/3
強關聯規則挖掘是在滿足一定支援度的情況下尋找置信度達到閾值的所有模式。
FP-Tree演算法描述
演算法描述:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
演算法的核心是FPGrowth函式,這是一個遞迴函式。CPB的全稱是Conditional Pattern Base(條件模式基),我們可以把CPB理解為演算法在不同階段的事務集合。PostModel稱為字尾模式,它是一個List。後文會詳細講CPB和PostModel是如何生成的,初始時令PostModel為空,令CPB就是原始的事務集合。
下面我們舉個例子來詳細講解FPGrowth函式的完整實現。
事務資料庫如下,一行表示一條購物記錄:

牛奶,雞蛋,麵包,薯片 雞蛋,爆米花,薯片,啤酒 雞蛋,麵包,薯片 牛奶,雞蛋,麵包,爆米花,薯片,啤酒 牛奶,麵包,啤酒 雞蛋,麵包,啤酒 牛奶,麵包,薯片 牛奶,雞蛋,麵包,黃油,薯片 牛奶,雞蛋,黃油,薯片
令minSuport=3,統計每一個專案出現的次數,把次數低於minSuport的專案刪除掉,剩下的專案按出現的次數降序排列,得到F1:
薯片:7 雞蛋:7 麵包:7 牛奶:6 啤酒:4
對於每一條事務,按照F1中的順序重新排序,不在F1中的被刪除掉。這樣整個事務集合變為:
薯片,雞蛋,麵包,牛奶 薯片,雞蛋,啤酒 薯片,雞蛋,麵包 薯片,雞蛋,麵包,牛奶,啤酒 麵包,牛奶,啤酒 雞蛋,麵包,啤酒 薯片,麵包,牛奶 薯片,雞蛋,麵包,牛奶 薯片,雞蛋,牛奶
上面的事務集合即為當前的CPB,當前的PostModel依然為空。由CPB構建FP-Tree的步驟如下。
插入第一條事務(薯片,雞蛋,麵包,牛奶)之後

插入第二條事務(薯片,雞蛋,啤酒)

插入第三條記錄(麵包,牛奶,啤酒)

估計你也知道怎麼插了,最終生成的FP-Tree是:

上圖中左邊的那一叫做表頭項,樹中相同名稱的節點要連結起來,連結串列的第一個元素就是表頭項裡的元素。不論是表頭項節點還是FP-Tree中有節點,它們至少有2個屬性:name和count。
現在我們已進行完演算法描述的第10行。go on
遍歷表頭項中的每一項,我們拿“牛奶:6”為例。
新的PostModel為“表頭項+老的PostModel”,現在由於老的PostModel還是空list,所以新的PostModel為:[牛奶]。新的PostModel就是一條頻繁模式,它的支援數即為表頭項的count:6,所以此處可以輸出一條頻繁模式<[牛奶], 6>
從表頭項“牛奶”開始,找到FP-Tree中所有的“牛奶”節點,然後找到從樹的根節點到“牛奶”節點的路徑。得到4條路徑:
薯片:7,雞蛋:6,牛奶:1 薯片:7,雞蛋:6,麵包:4,牛奶:3 薯片:7,麵包:1,牛奶:1 麵包:1,牛奶:1
對於每一條路徑上的節點,其count都設定為牛奶的count
薯片:1,雞蛋:1,牛奶:1 薯片:3,雞蛋:3,麵包:3,牛奶:3 薯片:1,麵包:1,牛奶:1 麵包:1,牛奶:1
因為每一項末尾都是牛奶,可以把牛奶去掉,得到新的CPB:
薯片:1,雞蛋:1 薯片:3,雞蛋:3,麵包:3 薯片:1,麵包:1 麵包:1
然後遞迴呼叫FPGrowth(新的CPB,新的PostModel),當發現新有CPB為空時遞迴就可以退出了。
幾點說明
- 可以在構建FP-Tree之前就把CPB中低於minSuport的專案刪掉,也可以先不刪,而是在構建FP-Tree的過程當中如果遇到低於minSuport的專案不把它插入到FP-Tree中就可以了。FP-Tree演算法之所以高效,就是因為它在每次FPGrowth遞迴時都對資料進行了這種裁剪。
- 沒必要每次FPGrowth遞迴時都把CPB中的事務按F1做一次重排序,只需要第一次構建CPB時按F1做一次排序,以後每次構建新的CPB時保持與老的CPB各專案順序不變就可以了。
- 對於FP-Tree已經是單枝的情況,就沒有必要再遞迴呼叫FPGrowth了,直接輸出整條路徑上所有節點的各種組合+postModel就可了。例如當FP-Tree為:
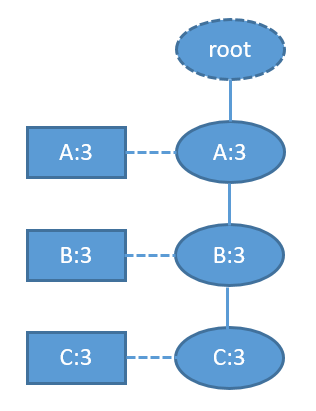
樹上只有一條路徑{A-B-C},在保證A-B-C這種順序的前提下,這三個節點的所有組合是:A,B,C,AB,AC,BC,ABC。每一種組合與postModel拼接形成一條頻繁模式,模式的支援數即為表頭項的計數(單枝的情況下所有表頭項和所有樹節點的計數都是相同的)。
Java實現
StrongAssociationRule.java
 View Code
View Code
TreeNode.java
View Code
FPTree.java
View Code
輸入trolley.txt
牛奶,雞蛋,麵包,薯片
雞蛋,爆米花,薯片,啤酒
雞蛋,麵包,薯片
牛奶,雞蛋,麵包,爆米花,薯片,啤酒
牛奶,麵包,啤酒
雞蛋,麵包,啤酒
牛奶,麵包,薯片
牛奶,雞蛋,麵包,黃油,薯片
牛奶,雞蛋,黃油,薯片
輸出pattens.txt
模式 頻數 麵包,啤酒 3 雞蛋,牛奶 4 麵包,薯片 5 薯片,雞蛋 6 啤酒 4 薯片 7 麵包,薯片,雞蛋,牛奶 3 雞蛋,啤酒 3 麵包,牛奶 5 薯片,雞蛋,牛奶 4 麵包,雞蛋,牛奶 3 麵包 7 牛奶 6 麵包,薯片,雞蛋 4 薯片,牛奶 5 雞蛋 7 麵包,雞蛋 5 麵包,薯片,牛奶 4
輸出rule.txt
條件 結果 支援度 置信度
[啤酒]->麵包 3 0.75
[牛奶]->雞蛋 4 0.67
[薯片]->麵包 5 0.71
[薯片]->雞蛋 6 0.86
[薯片, 雞蛋, 牛奶]->麵包 3 0.75
[麵包, 薯片, 牛奶]->雞蛋 3 0.75
[啤酒]->雞蛋 3 0.75
[牛奶]->麵包 5 0.83
[薯片, 牛奶]->雞蛋 4 0.8
[雞蛋, 牛奶]->麵包 3 0.75
[麵包, 牛奶]->雞蛋 3 0.6
[薯片, 雞蛋]->麵包 4 0.67
[麵包, 薯片]->雞蛋 4 0.8
[雞蛋]->麵包 5 0.71
[麵包]->雞蛋 5 0.71
[薯片, 牛奶]->麵包 4 0.8
MapReduce實現
在上面的程式碼我們把整個事務資料庫放在一個List<List<String>>裡面傳給FPGrowth,在實際中這是不可取的,因為記憶體不可能容下整個事務資料庫,我們可能需要從關係關係資料庫中一條一條地讀入來建立FP-Tree。但無論如何 FP-Tree是肯定需要放在記憶體中的,但記憶體如果容不下怎麼辦?另外FPGrowth仍然是非常耗時的,你想提高速度怎麼辦?解決辦法:分而治之,平行計算。
按照論文《FP-Growth 演算法MapReduce 化研究》中介紹的方法,把以相同專案結尾的patten輸出一個Reducer裡面去,在Reducer中僅對這一部分patten建立FPTree,這種FPTree會小很多,一般不會佔用太多的記憶體。另外論文中的方法不需要維護表頭項。
結束語
在實踐中,關聯規則挖掘可能並不像人們期望的那麼有用。一方面是因為支援度置信度框架會產生過多的規則,並不是每一個規則都是有用的。另一方面大部分的關聯規則並不像“啤酒與尿布”這種經典故事這麼普遍。關聯規則分析是需要技巧的,有時需要用更嚴格的統計學知識來控制規則的增殖