
MYSQL的查詢優化(學習優化sql的步驟)
1.慢查詢
mysql自身是有一個慢查詢時間和慢查詢記錄的,但是在預設情況下,我們的mysql不會記錄慢查詢,需要在啟動mysql時候,指定記錄慢查詢才可以
(1)使用show variables like 'long_query_time'命令,檢視慢查詢時間
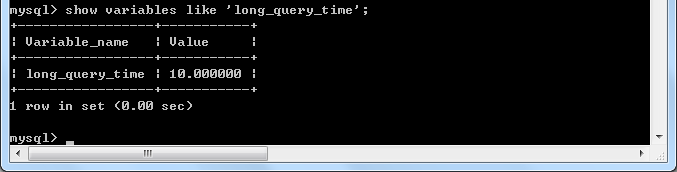
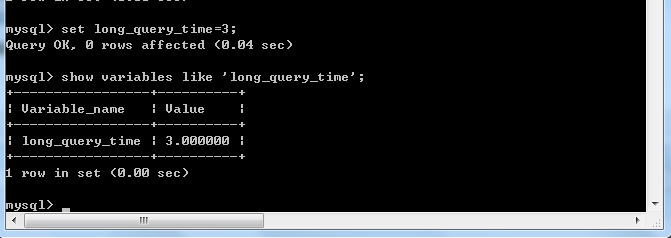
現在慢查詢時間是10s,但是我們可以通過set long_query_time對其進行臨時修改(關閉掉這次會話之後慢查詢時間會被重置回10)
另外,我們也可以通過show variables like '%slow%'這個命令來檢視慢查詢的配置
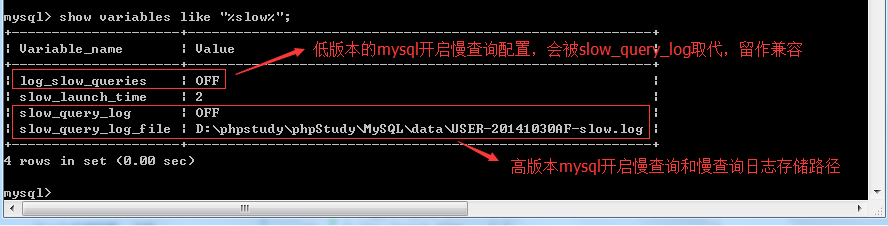
慢查詢日誌預設是不啟用的,所以我們要開啟它,有兩種方法,一種是用set重新設定變數,另一種就是直接修改配置檔案,這裡建議用修改變數的方法(因為是臨時的)
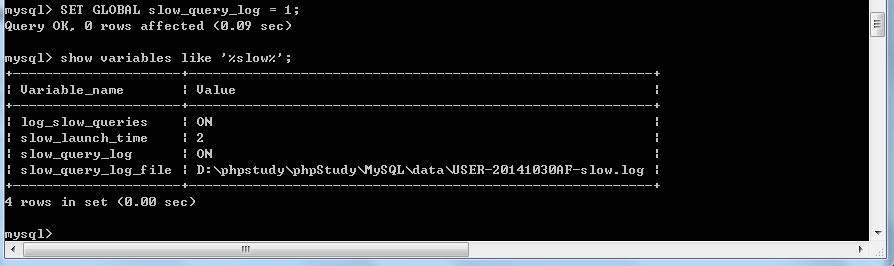
想要測試是否開啟慢查詢,可以使用select sleep(3),執行之後去對應的目錄找到慢查詢日誌是否有記錄就可以了,這裡就不再多說了。
2.構建大資料量進行測試
因為之前優化的查詢裡面儲存著客戶的資料,這裡不方便用於展示,所以我們可以自己來構建一個大資料的表,這裡就用到了mysql的儲存過程(使用儲存過程無非就是想要插入資料執行的時間減少而已,其實我們可以通過php寫程式碼批量插入)
儲存過程怎樣寫我就不多說了,而且網上也能找到大量的測試資料程式碼,所以這裡我就直接上程式碼了
(1)建立表
CREATE TABLE dept(
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '編號',
dname VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名稱',
loc VARCHAR(13) NOT NULL DEFAULT "" COMMENT '地點'
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE emp (
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '編號',
ename VARCHAR(20) NOT NULL DEFAULT "" COMMENT '名字',
job VARCHAR(9) NOT NULL DEFAULT "" COMMENT '工作',
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '上級編號',
hiredate DATE NOT NULL COMMENT '入職時間',
sal DECIMAL(7,2) NOT NULL COMMENT '薪水',
comm DECIMAL(7,2) NOT NULL COMMENT '紅利',
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '部門編號'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
分別是部門表(dept)和員工表(emp),這裡我是故意沒有建立主鍵,等下留作演示用
(2)建立自定義函式
delimiter $$
建立一個自定義函式,目的是返回1-10的隨機數
create function rand_num()
returns int
begin
return floor(1+rand()*10);
end$$
建立一個自定義函式,目的是返回隨機字串
create function rand_string(n INT) returns varchar(255) begin declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end$$
為了能使儲存過程正常執行,要先把mysql的語句結束符號修改成$$,建立完後用delimiter命令改回;就可以了
(3)建立插入資料的儲存過程
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit設定成0
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
(4)呼叫call insert_emp(100001,4000000)建立400w條資料

插入400w條資料用了8分半鐘,這時我們可以去看下慢查詢日誌是否記錄了

3.查詢優化
首先,我們在沒有索引的情況下,對員工表進行查詢
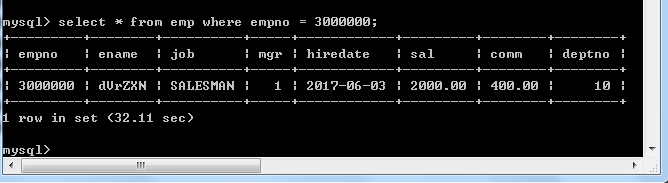
查詢員工號為300w的資料,用時32.11s,這估計是誰都不能忍的事,要是被老闆發現了,估計就要直接掀桌了,所以我們就用explain工具來分析一下這條查詢

那麼,現在我們為員工編號加上主鍵索引,結果又會如何呢
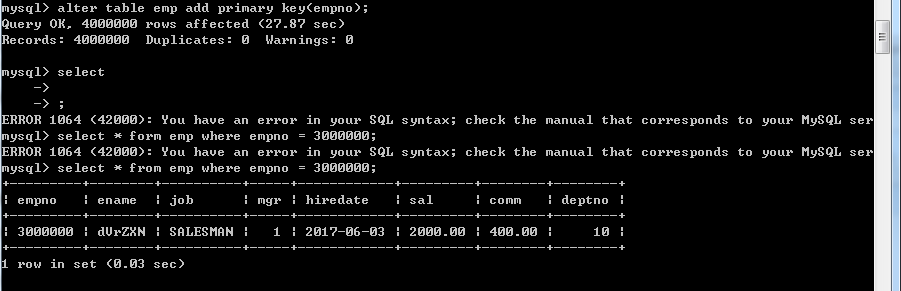
只用了0.03秒,查詢效率提高了1000倍以上!
現在我們來分析一下這個查詢語句吧

那麼,現在我們來試試多表查詢的情況,先向部門表插入幾條資料,這裡就不再多說了

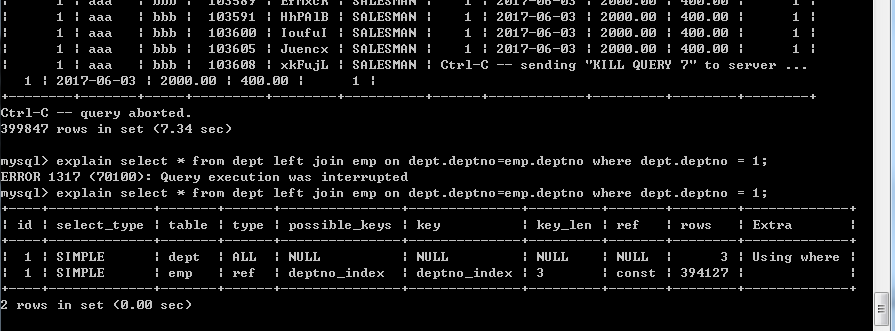
可以發現,用了51s才查詢完畢(因為資料過多,所以用ctrl+c中斷輸出,這裡補充上查詢語句select * from dept left join emp on dept.deptno=emp.deptno where dept.deptno=1;)

用explain分析可以看出兩個表都是全表掃描
為emp表加上deptno的索引後,查詢結果和分析結果如下
只用了7.34s,而且查詢數量明顯相比第一次只查詢了不到40w條,查詢效率提高了7倍以上
然而我們也發現了,dept表仍然沒有用到索引,所以我們試試看為dept表加上主鍵索引
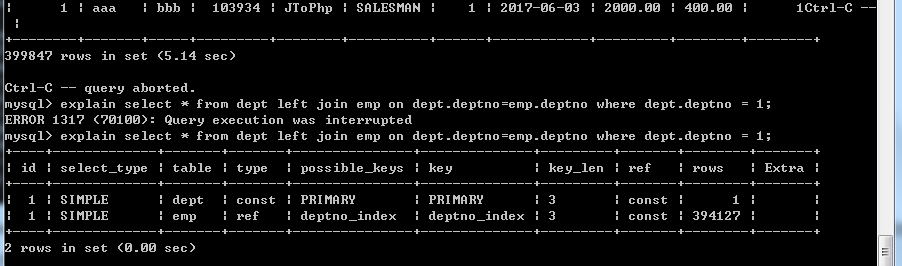
雖然有所優化,但是並不明顯,其實上述實驗結果也可以看出,總查詢條數(rows)/總資料量的比值越小,索引優化查詢的效果越明顯
mysql的查詢優化就暫時先介紹到這裡了,想要具體的對mysql進行優化,其實還需要explain各引數的詳解和使用索引的注意事項等