
【mysql優化五】——sql語句優化查詢
前言
上篇講解了索引搜尋優化,其實索引只是sql查詢優化的一部分,本篇主要講解的是sql優化主要要優化的部分!
內容
| 一.order by 優化 |
- orderby最好使用index排序方式,避免使用FileSort方式排序;
- 在索引列上完成排序,遵照索引最佳做字首
- orderby最好不要使用select *;
- 如果使用fileSort方式,嘗試提高sort_buffer_size
- 如果使用fileSort方式,嘗試提高max_length_for_sort_data
使用filesort排序優化策略
orderby最好不要使用select *;
提高max_length_for_sort_data
提高sort_buffer_size
【解答】:
1.為什麼不用select *?
當query的欄位大小總和小於max_length_sort_data,而且排序欄位不是text|blob型別,會用改進後的演算法單路排序,否則多路排序。
1.雙路排序,兩次掃描磁碟,最終得到資料;讀取行指標和orderby列,對他們進行排序,然後掃描已經排序好的列表,按照列表中的資料從磁碟中取排序的欄位,在buffer進行排序,再從磁碟中去其他欄位(mysql4.1之前)
2.單路排序,從磁碟讀取需要的所有列,按照order by列在buffer對他們進行排序,然後掃描排序後的列表進行輸出,它的效率更快一些,避免了第二次讀取資料,並且報隨機I/O變成了順序I/O,但是它會使用更多的空間。
2.為什麼要提高sort_buffer_size?
上訴兩種演算法的資料都有可能超出sort_buffer的容量,超出之後,會建立tmp檔案進行合併排序,導致多次的i/O操作,但是單路排序的演算法風險會更大一些,所以提高sort_buffer_size.
3.如何提高sort_buffer_size和max_length_for_sort_data引數值?
檢視本sql的sort_buffer_size;
show variables like '%sort_buffer%';+-------------------------+---------+
| Variable_name | Value |
+-------------------------+---------+
| innodb_sort_buffer_size | 1048576 |
| myisam_sort_buffer_size | 8388608 |
| sort_buffer_size | 262144 |
+-------------------------+---------+其中以後位元組為單位的,所以sort_buffer_size=262144/1024=256KB
設定本sql的中sort_buffer_size:
SET GLOBAL sort_buffer_size = 1024*1024; //2MB的buffer大小3.是不是buffer的大小越大越好?
Sort_Buffer_Size 並不是越大越好,由於是connection級的引數,過大的設定+高併發可能會耗盡系統記憶體資源。
參考部落格:
http://www.cnblogs.com/wy123/p/7744171.html
https://blog.csdn.net/mydriverc2/article/details/79026337
order by索引方式優化策略
orderby最好不要使用select *;
在索引列上完成排序,遵照索引最佳做字首
建立複合索引:
create index idx_three on tblA(age,birth,addr);
1.索引最左字首,orderby 使用索引有效
select * from tblA order by age;
select * from tblA order by age,birth;
select * from tblA order by age, birth,addr;2.where索引的最左字首為常量,orderby 使用索引有效
第一種情況最普遍:
explain select * from tblA where age=24 order by birth,addr;第二種情況,如果birth使用了範圍,但是由於頭索引生效了,所以order by使用索引生效。
mysql> explain select * from tblA where age=24 and birth >'2018-07-11 18:09:10' order by birth,addr;| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------+-----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | tblA | NULL | range | idx_A_ageBirth,idx_three | idx_three | 9 | NULL | 1 | 100.00 | Using where; Using index |【注意】
三種情況導致索引失效:
1.複合索引頭索引不存在;
explain select * from tblA order by birth,addr;+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | tblA | NULL | index | NULL | idx_three | 100 | NULL | 3 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
1.複合索引中間的索引不存在
explain select * from tblA where age=24 and birth >'2018-07-11 18:09:10' order by addr;
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | tblA | NULL | index | NULL | idx_three | 100 | NULL | 3 | 100.00 | Using index; Using filesort |
+----+-------------+-------+------------+-------+---------------+-----------+---------+------+------+----------+-----------------------------+
報告中分析extra指標中存在 using filesort說明這條語句寫的糟糕
3.order by中存在了不是複合索引中的欄位
explain select * from tblA order by age,birth,addr,xing1;4.範圍查詢也會導致索引失效;
explain select * from tblA where age in (22,24) order by birth,addr;
+----+-------------+-------+------------+-------+--------------------------+-----------+---------+------+------+----------+------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+--------------------------+-----------+---------+------+------+----------+------------------------------------------+
| 1 | SIMPLE | tblA | NULL | range | idx_A_ageBirth,idx_three | idx_three | 5 | NULL | 2 | 100.00 | Using where; Using index; Using filesort |
+----+-------------+-------+------------+-------+--------------------------+-----------+---------+------+------+----------+------------------------------------------+
檢視分析中type為range,說明是範圍查詢,實際用了idx_three,但是依舊存在filesort說明語句還是糟糕。像這種情況我們只能根據需求的不同,建立合適的索引了。
優化原則:
小表驅動大表,小的資料集驅動大的資料集。
【分析】:
子查詢結果集必須要比主查詢結果集大,因為in和exists本質是一個for迴圈,內部多次迴圈可以減少從內部到外部的時間,減少執行的時間。
in和exists語句中,in 後面的語句先執行,所以是外迴圈,必須要保證in後面的表比in前面的表小;exists前面的語句先執行,所以是外迴圈,必須要保證前面表的資料集小於後面的表:

select * from tb1_emp e where e.deptId in (select id from tb1_dept d);select * from tb1_emp e where exists(select 1 from tb1_dept d where d.id=e.deptiD);
| 二.索引優化 |
可以參照我之前部落格:【mysql學習三】——索引搜尋優化
| 三.group by |
- 本質排序好了進行分組,遵照索引建的最佳前索引
- 使用filesort方式時,增大max_length_for_sort_data引數設定
- 使用filesort方式時,增大sort_buffer_size引數設定
- where高於having,能寫where限定條件就不要去寫having的限定
【分析】
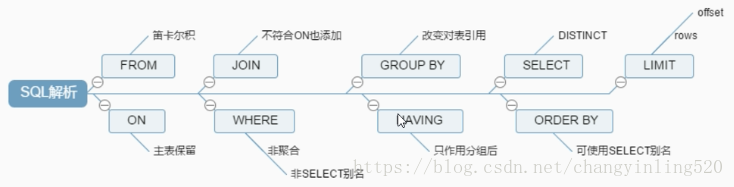
由圖中中可以看出來,執行的順序依次是from,on,(join,where),group by ,having,select ,order by limit;
| 四.join優化 |
1,儘可能減少Join 語句中的Nested Loop 的迴圈總次數,用小結果集驅動大結果集; 注意不是:小表連線大的快,而是結果集
2,優先優化Nested Loop 的內層迴圈; 做索引
3,保證Join 語句中被驅動表上Join 條件欄位已經被索引;
4,擴大join buffer的大小;| 五.limit優化 |
資料量少的時候我們可以使用
Select * from A order by id limit 1,10;但是資料量大的時候,可以在id上建立一個索引,寫成如下的方式:
Select * from A where id>=(Select id from a limit 10000000,1) limit 10;或者寫成如下:
Select * from A where id between 10000000and 10000010;| 六.where子句優化 |
- 去除不必要的括號
- 去除不必要的條件判斷
需要取出一條語句,使用limit:
Select * from A where namelike ‘%xxx’ limit 1; // 防止引擎繼續掃描表或者索引參考部落格:
https://blog.csdn.net/kevinlifeng/article/details/43233227
https://www.jb51.net/article/39221.htm總結
sql查詢優化講解完了,如果你遇到其他的優化解決方案,咱們再一起討論!歡迎訪問我的部落格,希望對你有幫助