
機器學習筆記——貝葉斯分類器
一,貝葉斯最優分類器
期望損失(條件風險):假設有N種可能的類別標記,即y = {c1,c2,...,cN},λij是將一個真實標記為cj的樣本誤分類為ci所產生的損失。將樣本x分類ci所產生的期望損失為:
我們的任務是尋找一個假設h,以最小化總體風險:
貝葉斯判定準則:為最小化總體風險,只需在每個樣本上選擇那個能使條件風險R(c|x)最小的類別標記,即:
此時,h*稱為貝葉斯最優分類器,與之對應的總體風險R(h*)稱為貝葉斯風險。
若目標是最小化分類錯誤率,則誤判損失λij可寫為:
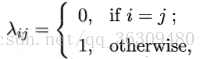
此時條件風險:
貝葉斯最優分類器為:
即對每個樣本x,選擇能使後驗概率P(c|x)最大的類別標記。
鑑於貝葉斯定理:

因此,估計P(c|x)的問題就轉化為如何基於訓練集D來估計先驗P(c)和類條件概率(似然)P(x|c)。
二,極大似然估計
令Dc表示訓練集D中第c類樣本組成的集合,假設這些樣本是獨立同分布的,則引數θc對於Dc的似然是:
對θc進行極大似然估計,就是去尋找能最大化似然P(Dc|θc)的引數值θc。
通常對上式使用對數似然再求解引數:

這種估計方式結果的準確姓嚴重依賴於所假設的概率分佈形式是否符合潛在的真實資料分佈。
三,樸素貝葉斯分類器
估計後驗概率P(c|x)的主要困難在於:類條件概率P(x|c)是所有屬性上的聯合分佈,難以從有限的訓練樣本直接估計而得。
為避開這個障礙,樸素貝葉斯分類器採用了“屬性條件獨立性假設”:對已知類別,假設所有屬性相互獨立。
貝葉斯公式可重寫為:
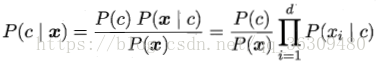
其中d為屬性數目,xi為x在第i個屬性上的取值。
樸素貝葉斯分類器的表示式為:

顯然,樸素貝葉斯分類器的訓練過程就是基於訓練集D來估計類先驗概率P(c),併為每個屬性估計條件概率P(xi|c)。
最後再來簡單說一下拉普拉斯修正。具體來說,令N表示訓練集D中可能的類別數,Ni表示第i個屬性可能的取值數,則有:
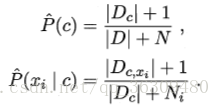
顯然,拉普拉斯修正避免了因訓練樣本不足而導致概率估值為零的問題。