
機器學習系列——樸素貝葉斯分類器(二)
貝葉斯定理:
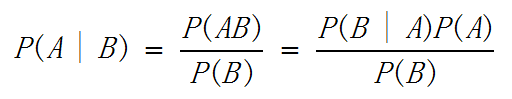
其中: 表示事件B已經發生的前提下,事件A發生的概率,叫做事件B發生下事件A的條件概率。其基本求解公式為:
。
機器學習系列——樸素貝葉斯分類器(二)
相關推薦
機器學習系列——樸素貝葉斯分類器(二)
表示 -h line log ima 條件 code 樸素貝葉斯 spa 貝葉斯定理: 其中: 表示事件B已經發生的前提下,事件A發生的概率,叫做事件B發生下事件A的條件概率。其基本求解公式為:。 機器學習系列——樸素貝葉斯分類器(二)
機器學習:貝葉斯分類器(二)——高斯樸素貝葉斯分類器代碼實現
mod ces 數據 大於等於 即使 平均值 方差 很多 mode 一 高斯樸素貝葉斯分類器代碼實現 網上搜索不調用sklearn實現的樸素貝葉斯分類器基本很少,即使有也是結合文本分類的多項式或伯努利類型,因此自己寫了一遍能直接封裝的高斯類型NB分類器,當然與真正的源碼相
機器學習:樸素貝葉斯分類器,決策函式向量化處理,mask使用技巧
文章目錄 前面實現的樸素貝葉斯分類器,決策函式是非向量化的: 藉助於numpy向量化處理,相當於平行計算,注意mask使用技巧,用途較廣: 前面實現的樸素貝葉斯分類器,決策函式是非向量化的: 前面提到過大資料處理,儘量避免個人的遍歷等一些函式
機器學習:樸素貝葉斯分類器程式碼實現,決策函式非向量化方式
文章目錄 樸素貝葉斯離散型的演算法描述: 程式碼實現: 實現一個NaiveBayes的基類,以便擴充套件: 實現離散型樸素貝葉斯MultiomialNB類: 實現從檔案中讀取資料: 測試資料: 程式碼測試:
機器學習之樸素貝葉斯分類器附C++程式碼
一、基本概念: 先驗概率(prior probability):是指根據以往經驗和分析得到的概率,如全概率公式,它往往作為"由因求果"問題中的"因"出現的概率。比如,拋一枚硬幣,正面朝上的概率P(A)=1/2,就是先驗概率。聯合概率:表示兩個事件共同發生的概率。A與B的
機器學習之樸素貝葉斯分類器實現
問題如下 比如:有如下的需求,要判斷某一句英語是不是侮辱性語句 分析思路 對於機器來說,可能不容易分辨出某一句話是不是侮辱性的句子,但是機器可以機械的進行分析,何為機械的進行分析,就是判斷某一個句子中侮辱性的單詞是不是達到一定數量(當然這
【機器學習】樸素貝葉斯分類器
前言:在正式講述樸素貝葉斯分類器之前,先介紹清楚兩個基本概念:判別學習方法(Discriminative Learning Algorithm)和生成學習方法(Generative Learning Algorithm)。 上篇博文我們使用Logist
貝葉斯分類器(二)
不同特徵獨立性假設條件下的貝葉斯分類器介紹 在貝葉斯分類器(一)一節,我們簡要證明了貝葉斯分類器相較於其他判別規則具有最小誤分類概率。我們知道貝葉斯分類的關鍵包括對類先驗概率的確定以及類樣本概率密度的確定。當使用不同的方法估計類樣本概率密度時,我們基於貝葉斯分類
機器學習---樸素貝葉斯分類器(Machine Learning Naive Bayes Classifier)
垃圾郵件 垃圾 bubuko 自己 整理 href 極值 multi 帶來 樸素貝葉斯分類器是一組簡單快速的分類算法。網上已經有很多文章介紹,比如這篇寫得比較好:https://blog.csdn.net/sinat_36246371/article/details/601
機器學習之樸素貝葉斯分類方法
本文轉載自http://holynull.leanote.com/post/Logistic-2 樸素貝葉斯分類方法 前言 樸素貝葉斯分類演算法是機器學習領域最基本的幾種演算法之一。但是對於作者這樣沒有什麼資料基礎的老碼農來說,理解起來確實有一些困難。所以撰寫此文幫
機器學習實戰——樸素貝葉斯分類
準備資料:從文字中構建詞向量 前期測試函式用的資料 def loadDataSet(): '''建立一些實驗樣本''' postingList = [['my','dog','has','flea','problems','help','
sklearn庫學習之樸素貝葉斯分類器
樸素貝葉斯模型 樸素貝葉斯模型的泛化能力比線性模型稍差,但它的訓練速度更快。它通過單獨檢視每個特徵來學習引數,並從每個特徵中收集簡單的類別統計資料。想要作出預測,需要將資料點與每個類別的統計資料進行比較,並將最匹配的類別作為預測結果。 GaussianNB應用於任意連續資料,
機器學習之多項式貝葉斯分類器multinomialNB
機器學習之多項式貝葉斯分類器multinomialNB # -*- coding: utf-8 -*- """ Created on Sun Nov 25 11:28:25 2018 @author: muli """ from sklearn import nai
機器學習入門-貝葉斯分類器(一)
今天學習的內容是貝葉斯分類器。 在正式介紹之前,先說兩個名詞: 標稱型資料:只在有限的目標集中取值,如真與假(主要用於分類) 數值型資料:可從無限的數值集合中取值(主要用於迴歸分析) 貝葉斯決策論 Bayes Decision theor
機器學習筆記(七)貝葉斯分類器
7.貝葉斯分類器 7.1貝葉斯決策論 貝葉斯決策論(Bayesiandecision theory)是概率框架下實施決策的基本方法。對分類任務來說,在所有相關概率都已知的理想情形下,貝葉斯決策論考慮如何基於這些概率和誤判損失來選擇最優的類別標記。這其實是關係到兩個基本概念:
深度學習理論——樸素貝葉斯分類器
大家好,繼續理論學習,終於開始學習貝葉斯啦!本文主要參考周志華的西瓜書和眾多部落格加上自己的理解。 拉普拉斯修正避免了因訓練集樣本不充分造成的概率估值為零的問題,並且在訓練集變大時,修正引入的先驗的影響也會減小,概率趨近於真實概率。 貝葉斯應該還沒有完結,可能會有下一
樸素貝葉斯分類器(Naive Bayes Classifiers)
本文討論的是樸素貝葉斯分類器( Naive Bayes classifiers)背後的理論以及其的實現。 樸素貝葉斯分類器是分類演算法集合中基於貝葉斯理論的一種演算法。它不是單一存在的,而是一個演算法家族,在這個演算法家族中它們都有共同的規則。例如每個被分類的
常用分類問題的演算法-樸素貝葉斯分類器(Naive Bayes Classifiers)
樸素貝葉斯分類器是分類演算法集合中基於貝葉斯理論的一種演算法。它不是單一存在的,而是一個演算法家族,在這個演算法家族中它們都有共同的規則。例如每個被分類的特徵對與其他的特徵對都是相互獨立的。 樸素貝葉斯分類器的核心思想是: 1、將所有特徵的取值看成已經發生的
樸素貝葉斯分類器(Python實現)
基本思想: 樸素貝葉斯分類器,在當給出了特徵向量w情況下,分類為ci的條件概率p(ci | w)。 利用貝葉斯公式:p(ci | w) = p(w | ci) * p(ci) / p(w),可以完成轉化,觀察公式可以發現分母p(w)都一樣,所以只要比較分子的
情感分析方法之snownlp和貝葉斯分類器(三)
《情感分析方法之nltk情感分析器和SVM分類器(二)》主要使用nltk處理英文語料,使用SVM分類器處理中文語料。實際的新聞評論中既包含英文,又包含中文和阿拉伯文。本次主要使用snownlp處理中文語料。一、snownlp使用from snownlp import Snow