
斯坦福大學-自然語言處理與深度學習(CS224n) 筆記 第二課 詞向量(word vector)
課程概要
1、單詞含義
2、word2vec介紹
3、word2vec目標函式的梯度推導
4、目標函式優化:梯度下降法
一、單詞含義
含義(meaning)指的是由單詞表達的觀點。我們一般使用單詞含義的方法是,使用像WordNet那樣的分類詞典,給每個單詞對應的上下義關係以及同義詞集合(具體可見斯坦福大學-自然語言處理入門 筆記 第十九課 單詞含義與相似性第二節)。
上面的這種方法會存在的問題有:會忽略一些細微差別,比如同義詞之間的差別;無法即時收錄一些新的單詞;主觀性;需要花費人工去修正和創造;很難準確去計算單詞之間的相似程度。
在NLP中非常常見的一種文字的表徵方法是項文字矩陣,即矩陣的行代表單詞,矩陣的列代表文字,每一格則表示該列文件是否有該行單詞,有為1,沒有為0。這樣的話,一個單詞的表徵向量就是對應行的向量,但是當我們去看兩個單詞的相似度的時候會發現兩者是正交的。

另外一種表徵的方法是,利用單詞的上下文來表示單詞本身。我們希望利用一個向量來表示單詞,最好這個向量可以幫助我們預測它上下文的其他單詞,然後再用向量來表示其他的單詞。上面的觀點用數學公式和統計思想抽象出來的話就是:p(context|wt) =…,對應的損失函式是如下圖,通過使得該損失函式最小化,來幫助我們獲得單詞的表徵向量。
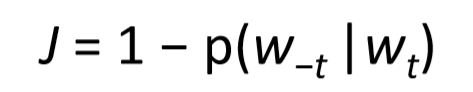
相關理論的發展如下:
Old idea.Relevant for this lecture & deep learning:
• Learning representations by back-propagating errors (Rumelhartet al., 1986)
• A neural probabilistic language model (Bengioet al., 2003)
• NLP (almost) from Scratch (Collobert & Weston, 2008)
• A recent, even simpler and faster model: word2vec (Mikolovet al. 2013) àintro now
二、word2vec的主要觀點介紹
word2vec主要涉及到兩個演算法,Skip-grams(SG)在位置獨立的假設下,根據中心詞預測上下文;Continuous Bag of Words (CBOW) 從詞包的上下文來預測目標單詞。兩個比較有效的訓練方法,分別是Hierarchical softmax 以及Negative sampling 。這裡主要介紹一下Skip-grams演算法。
Skip-grams演算法的主要思想是利用每一個單詞來預測半徑為m的視窗內的每個單詞。目標函式是在給定中心詞的情況下,使得上下文單詞的概率最大。用公式表示的話如下,第一行是極大似然的公式,第二行是加入負號的極大似然對數(把求極大變成了求極小),也就是我們的損失函式,其中的θ表示的是我們需要求的引數。
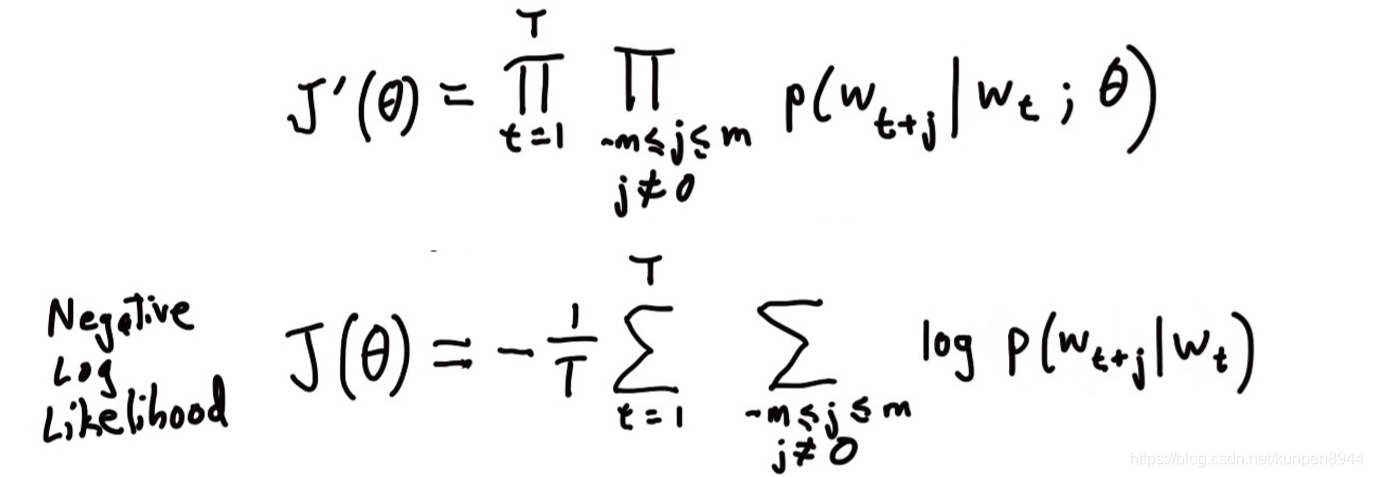
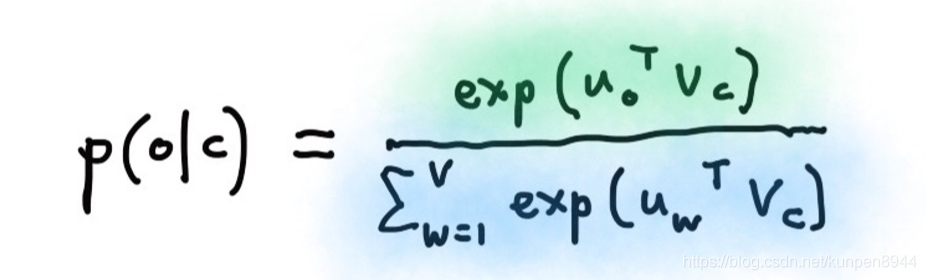 Skip-grams演算法的主要流程:
Skip-grams演算法的主要流程: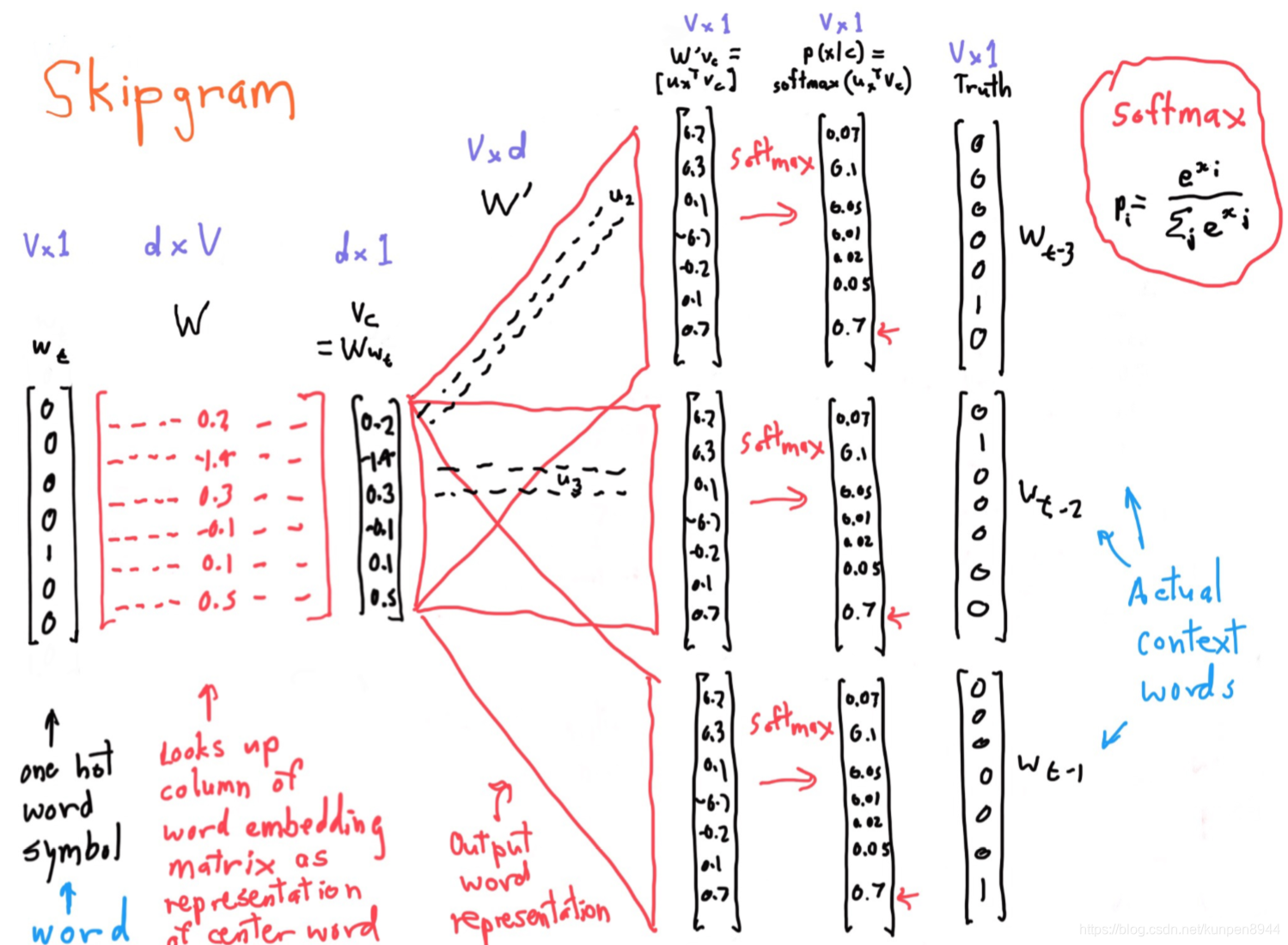 對於整個問題的求解而言,求解的引數就是每個單詞對應的兩個向量的值,假設有V個單詞,向量是d維的話,一共要求解2dv個引數
對於整個問題的求解而言,求解的引數就是每個單詞對應的兩個向量的值,假設有V個單詞,向量是d維的話,一共要求解2dv個引數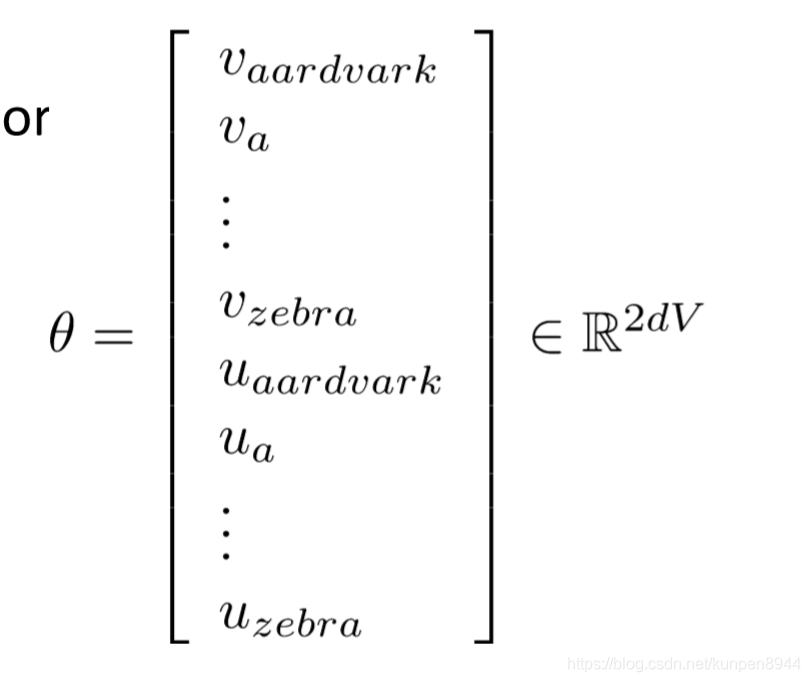
三、word2vec目標函式的梯度推導


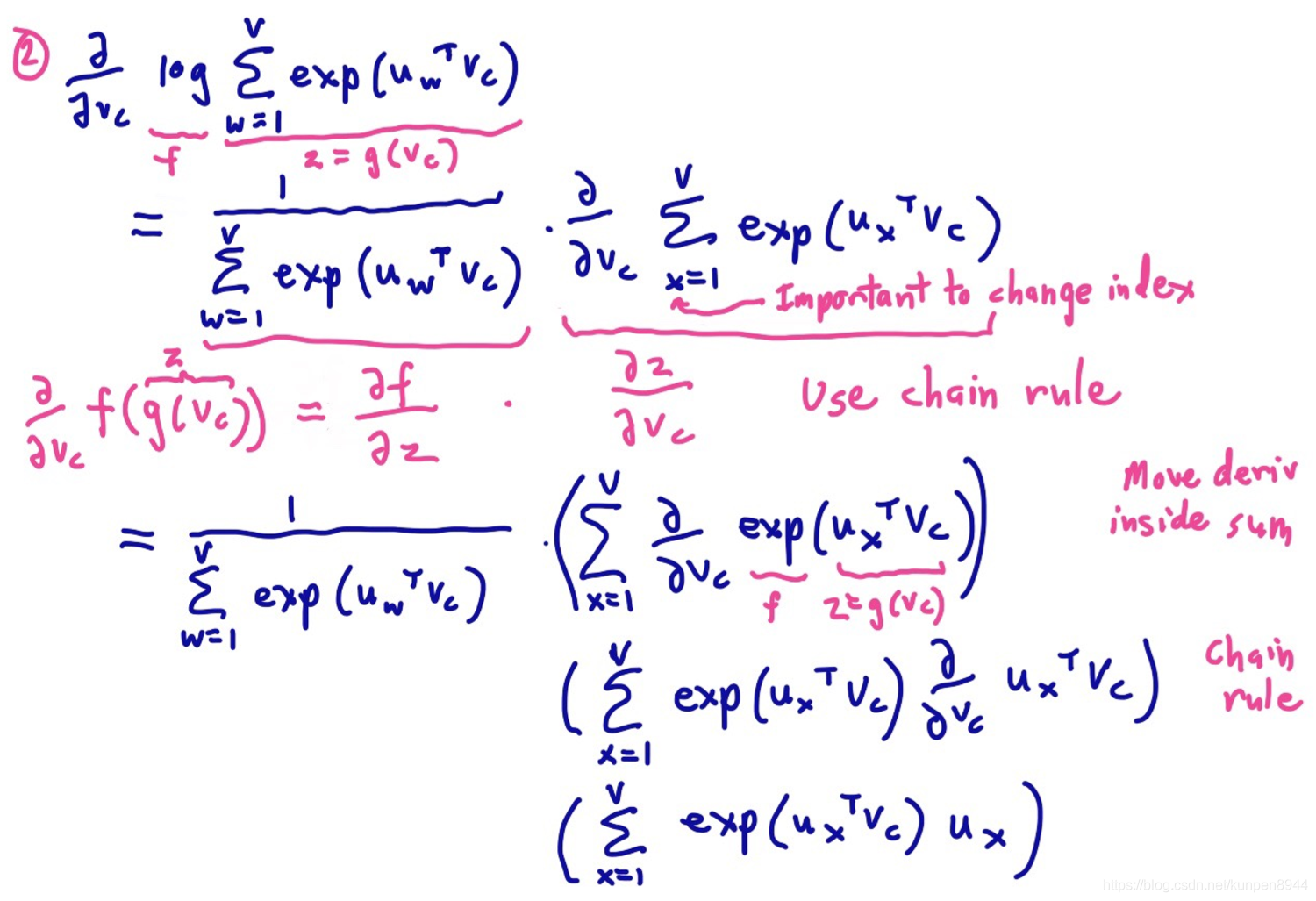

這裡知識計算了中心向量引數的導數,同時也需要外部(output)向量引數的導數,這兩者是相似的。
四、目標函式優化:梯度下降法
在計算出了引數的梯度以後,我們可以利用梯度下降法幫助我們進行引數的更新
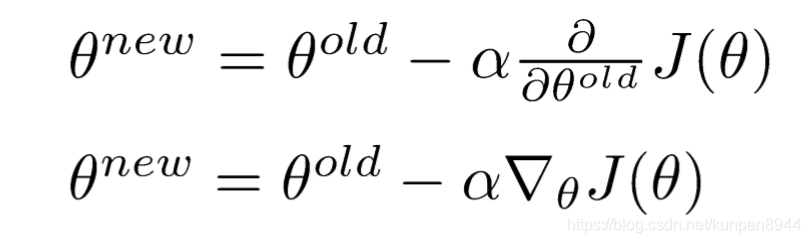 對應的python實現:
對應的python實現:
 我們也可以使用隨機梯度下降法來對引數進行優化,隨機梯度法每次只選取一個樣本進行梯度的計算,這樣的話會引入大量的噪音(noisy),對於自然語言處理的研究而言,這樣的噪音是有益的。所以,在NLP會大量得應用隨機梯度下降。
我們也可以使用隨機梯度下降法來對引數進行優化,隨機梯度法每次只選取一個樣本進行梯度的計算,這樣的話會引入大量的噪音(noisy),對於自然語言處理的研究而言,這樣的噪音是有益的。所以,在NLP會大量得應用隨機梯度下降。
