斯坦福大學-自然語言處理入門 筆記 第十六課 依存句法分析(Dependency Parsing)
阿新 • • 發佈:2018-11-06
一、介紹
1、依存句法
- 依存句法假設:句法結構包含相互之間是雙邊不對稱關係的詞典(lexical)元素,這種不對稱的關係成為依存(dependency),在圖中的表現是單向箭頭。
- 箭頭通常還會打上這種語法關係的名字(主語,前置賓語等等)
- 箭頭一邊連線中心詞head (governor, superior, regent),一邊則連線依存詞dependent (modifier, inferior, subordinate)。
- 這種關係表現為樹結構
2、片語結構(phrase structure)與依存結構之間的關係
- 依存語法有一箇中心詞的概念。但是CFG沒有。
- 但是在現代的語言理論以及所有的現代統計句法分析中,確實有一個手工定義的“中心詞規則”。
- 名詞片語(NP)的中心詞是名詞/數詞/形容詞
- 動詞片語(VP)的中心詞是動詞…
- “中心詞規則”可以幫助我們從上下文無關文法句法(CFG)中抽取依存句法
- 而從閉合的依存句法中我們亦可以得到片語結構的成分(constituency),但是同一個單詞的所有依存詞都必須在同一層中,這可能會導致片語結構和依存結構結果會略有不同。
3、四種依存分析方法

4、依存分析的資訊來源
- 雙單詞關聯:比如issues→the
- 依存距離:依存詞和中心詞的距離,大部分時候是相鄰的兩個詞
- 中間元素:一般依存關係之間不太可能會出現動詞或者標點
- 中心詞的價:一般,中心詞的左邊/右邊有多少個依存。
二、貪婪轉換句法分析(Greedy Transition-Based Parsing)
1、MaltPaser
- 這是一種簡單形式的判別依存句法分析。這種句法分析涉及到一系列自底向上的行動,比如移動(shift)和移除(reduce)。
- 這種分析句法含有:
- 一個堆疊 stack σ,從ROOT開始從頂向右儲存
- 一個緩衝區 buffer β,從輸入的句子開始從頭到左
- 一系列依存關係(dependency arcs),一開始是空的
- 一系列操作(action)
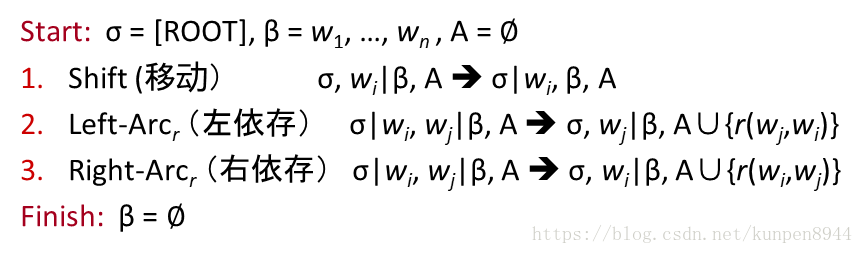
- 用字母語言來表示
- 初始狀態:σ=[ROOT],β=w1,…,wn, A=空集
- 基本的轉換依存句法分析(Basic transition-based dependency parser)
- “arc-eager”依存句法分析:上面基本的句法分析方法在處理某些依存結構的時候會存在一些問題,因此對操作進行了改進。
- 例子:
- 如何得知下一步操作是什麼?
- 利用一個判別分類模型來幫助我們判斷下一步需要做的操作是什麼。可以是SVM,也可以是最大熵模型。
- 如果這是一個不標記依存類別的分類,那麼我們的判別模型就是一個四分類問題,如果這是一個標記依存類別的分類問題,那麼總的分類類別就是|R|*2+2,其中|R|表示依存類別的個數。
- 判別模型的特徵一般是:棧頂的單詞以及對應的詞性;在緩衝區的第一個單詞以及詞性等等
- 這是一個貪婪的演算法,作為改進的話,可以做一些束搜尋(beam search)
- 利用一個判別分類模型來幫助我們判斷下一步需要做的操作是什麼。可以是SVM,也可以是最大熵模型。
- 這種語法分類方法的正確率只比最好的詞彙化PCFGs低了一點點,但它是一個線性時間複雜度的演算法,計算起來很快。


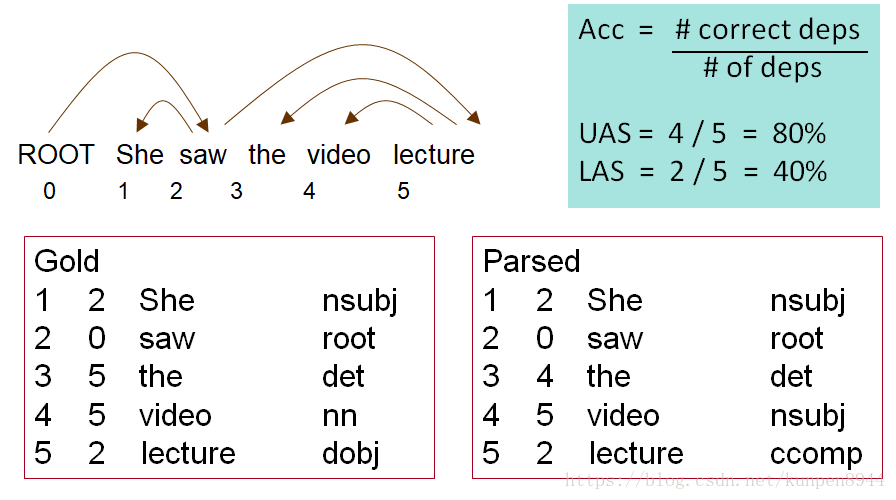
2、依存分析的評價以及表現
- 對每個單詞標上序號,列出每個依存關係對應的序號和型別。分為兩種正確率的計算
- UAS:不考慮依存關係的型別,只考慮依存關係的對應單詞是否正確
- LAS:同時考慮依存關係的對應單詞以及依存關係型別
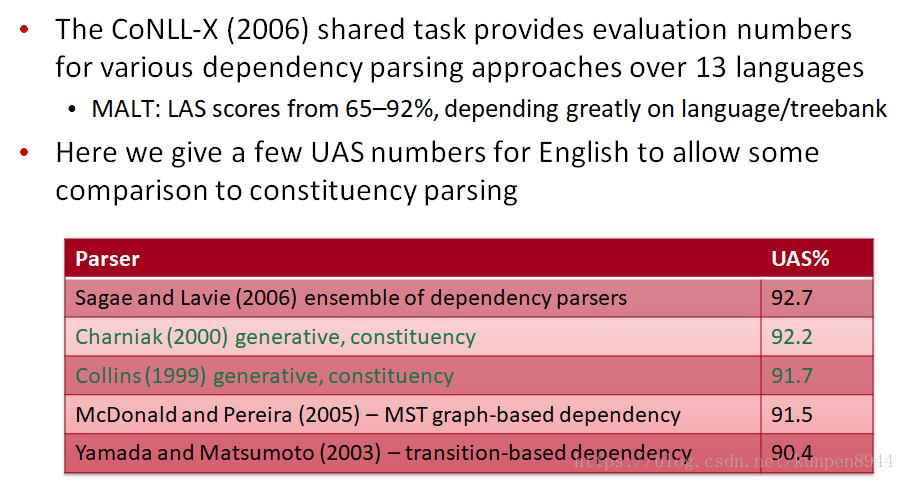
- 依存模型的效果
3、投射問題
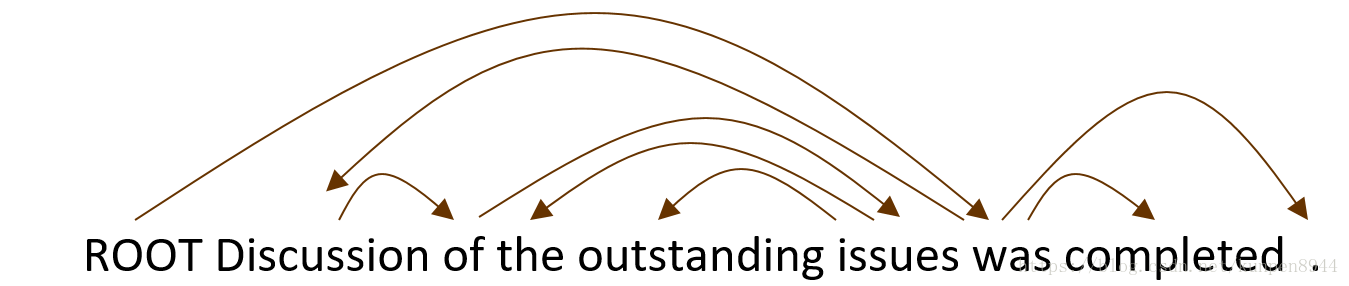
- 一個基於帶中心詞的CFG樹,它的依存關係必須是投射性的(projective)。所謂的投射性指的是當我們在單詞的上方用帶箭頭的弧度畫出單詞之間的依存關係的時候,這些弧度是不會相互交叉的。交叉情況如下圖。
- 但是一般依存理論是允許非投射性(non-projective)的情況出現的:對於某些結構而言,如果不用非投射性來研究的話,我們是無法理解其語義的。
- 我們上面展示的“arc-eager”演算法只能建立投射性(non-projective)樹,如果我們想要處理非投射性問題的話,這裡有一些解決方法。
- 直接預設不存在非投射性的依存關係,這種關係在英語裡面確實很少存在。
- 使用一種允許投射性表示的依存框架
- 在進行投射性語法分析演算法之前,先做一步預處理,找出非投射性依存並處理
- 在依存分析的演算法中加入新的操作,以處理一些比較常見的非投射性依存
- 使用那些沒有對投射性有限制的句法分析機制,比如基於圖的MSTParser

三、利用依存關係來進行關係抽取
- 依存路徑可以幫助我們定義蛋白質之間的互動關係
- 斯坦福依存(Stanford dependency)是一個可以實現這功能的軟體。其假設所有的依存關係都是投射性的。
- 構建依存樹:斯坦福依存假設所有的依存關係都是投射性的。因此我們可以用處理過的中心片語結構(Penn Treebank syntax)來構建依存關係,也可以直接使用依存分析,像上一節提到的MaltParser。
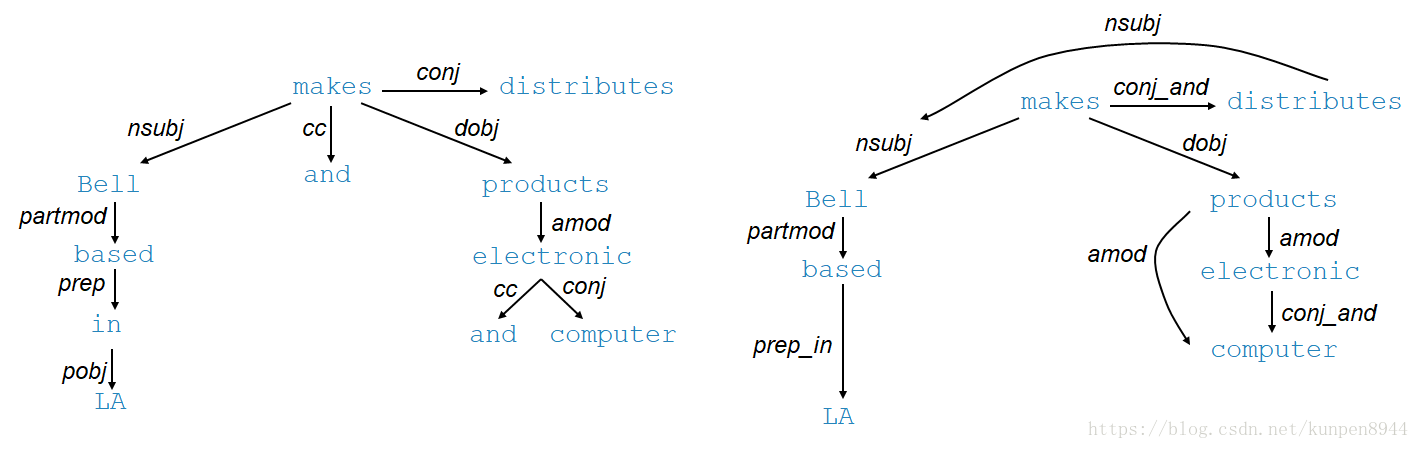
- 在構建了依存樹之後,我們進行一些圖的調整來幫助模型可以更好地進行關係抽取。如下圖,左邊是原來的依存樹,右邊是調整後的依存關係圖。
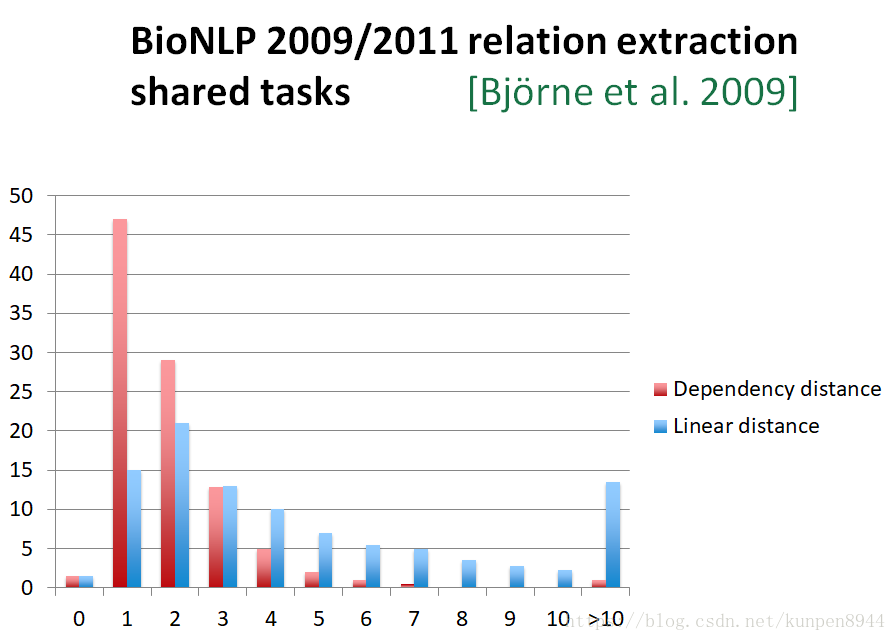
- 從實證角度來看:利用依存分析進行關係抽取的優勢是,依存分析下關係詞的距離要比直接進行關係抽取的單詞直接距離來得近。下圖橫軸表示單詞距離,紅色的是依存距離,藍色的是線性距離。縱軸表示頻率。可以看到單詞之間的依存距離比線性距離更多的集中在短距離的區域中。