
Python爬蟲教程-30-Scrapy 爬蟲框架介紹
阿新 • • 發佈:2018-09-07
start pre 出錯 名稱 erp pro rtp ise 結構性
從本篇開始學習 Scrapy 爬蟲框架
Python爬蟲教程-30-Scrapy 爬蟲框架介紹
- 框架:框架就是對於相同的相似的部分,代碼做到不出錯,而我們就可以將註意力放到我們自己的部分了
- 常見爬蟲框架:
- scrapy
- pyspider
- crawley
- Scrapy 是一個為了爬取網站數據,提取結構性數據而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中
- Scrapy 官方文檔
- https://doc.scrapy.org/en/latest/
- http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy 的安裝
- 可以直接在 Pycharm 進行安裝
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【scrapy】>【install】
- 具體操作截圖:
- 點擊左下角 install 靜靜等待
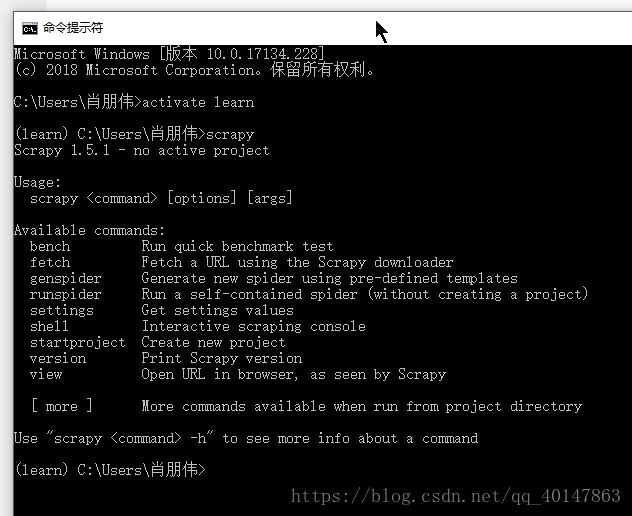
測試 Scrapy 是否安裝成功
- 進入當前所在的環境
- 輸入 scrapy 命令
- 截圖:
- 這裏就說明安裝成功l
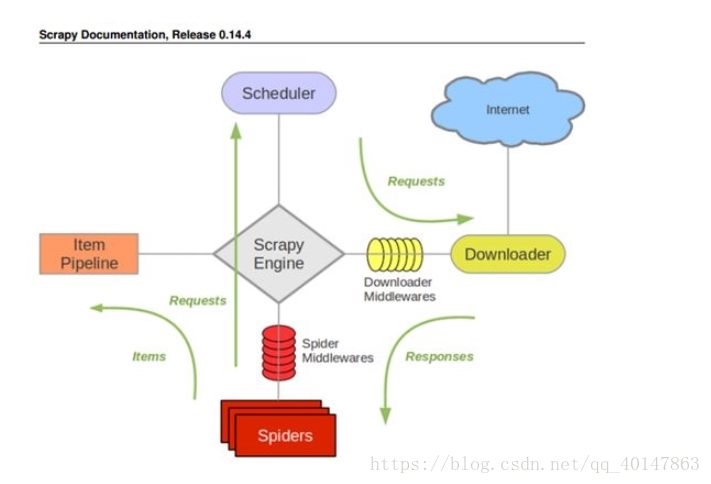
Scrapy 概述
- 包含各個部件
- ScrapyEngine:神經中樞,大腦,核心
- Scheduler 調度器:負責處理請求,引擎發來的 request 請求,調度器需要處理,然後交換引擎
- Downloader 下載器:把引擎發來的 requests 發出請求,得到 response
- Spider 爬蟲:負責把下載器得到的網頁/結果進行分解,分解成數據 + 鏈接
- ItemPipeline 管道:詳細處理 Item
- DownloaderMiddleware 下載中間件:自定義下載的功能擴展組件
- SpiderMiddleware 爬蟲中間件:對 spider 進行功能擴展
- 數據流圖:
- 綠色箭頭是數據的流向
- 由 Spider 開始 Requests, Requests, Responses, Items
爬蟲項目大致流程
- 1.新建項目:scrapy startproject xxx項目名
- 2.明確需要爬取的目標/產品:編寫 item.py
- 3.制作爬蟲:地址 spider/xxspider.py 負責分解,提取下載的數據
- 4.存儲內容:pipelines.py
模塊介紹
- ItemPipeline
- 對應 pipelines 文件
- 爬蟲提取出數據存入 item 後,item 中保存的數據需要進一步處理,比如清洗,去蟲,存儲等
- Pipeline 需要處理 process_item 函數
- process_item
- spider 提取出來的 item 作為參數傳入,同時傳入的還有 spider
- 此方法必須實現
- 必須返回一個 Item 對象,被丟棄的 item 不會被之後的 pipeline
- _ init _:構造函數
- 進行一些必要的參數初始化
- open_spider(spider):
- spider 對象對開啟的時候調用
- close_spider(spider):
- 當 spider 對象被關閉的時候調用
- Spider
- 對應的是文件夾 spider 下的文件
- _ init _:初始化爬蟲名稱,start _urls 列表
- start_requests:生成 Requests 對象交給 Scrapy 下載並返回 response
- parse:根據返回的 response 解析出相應的 item,item 自動進入 pipeline:如果需要,解析 url,url自動交給 requests 模塊,一直循環下去
- start_requests:此方法盡能被調用一次,讀取 start _urls 內容並啟動循環過程
- name:設置爬蟲名稱
- start_urls:設置開始第一批爬取的 url
- allow_domains:spider 允許去爬的域名列表
- start_request(self):只被調用一次
- parse:檢測編碼
- log:日誌記錄
中間件(DownloaderMiddlewares)
- 什麽是中間件?
- 中間件是處於引擎和下載器中間的一層組件,可以有多個
- 參照上面的流程圖,我們把中間件理解成成一個通道,簡單說,就是在請求/響應等傳輸的時候,在過程中設一個檢查哨,例如:
- 1.身份的偽裝: UserAgent,我們偽裝身份,不是在開始請求的時候就設置好,而是在請求的過程中,設置中間件,當檢測到發送請求的時候,攔下請求頭,修改 UserAgent 值
- 2.篩選響應數據:我們最開始得到的數據,是整個頁面,假設某個操作,需要我們過濾掉所有圖片,我們就可以在響應的過程中,設置一個中間件
- 比較抽象,可能不是很好理解,但是過程是其實很簡單的
- 在 middlewares 文件中
- 需要在 settings 中設置以是生效
- 一般一個中間件完成一項功能
- 必須實現以下一個或者多個方法
- process_request (self, request, spider)
- 在請求的過程中被調用
- 必須返回 None 或 Response 或 Request 或 raise IgnoreRequest
- 如果返回 None:scrapy 將繼續處理 request
- 如果返回 Request:scrapy 會停止調用 process_request 並沖洗調度返回的 request
- 如果返回 Response:scrapy 將不會調用其他的 process_request 或者 process _exception,直接將該 response 作為結果返回,同時會調用 process _response
- process_response (self, request, spider)
- 每次返回結果的時候自動調用
- process_request (self, request, spider)
- 下一篇鏈接:Python爬蟲教程-31-創建 Scrapy 爬蟲框架項目
- 拜拜
- 本筆記不允許任何個人和組織轉載
Python爬蟲教程-30-Scrapy 爬蟲框架介紹